The Large Model Systems Organization develops large models and systems that are open, accessible, and scalable.
Latest Blog
See all posts
RadixArk Joins Forces with Google to Bring Full SGLang Features to TPUs
RadixArk and Google Cloud are partnering to bring SGLang to TPUs, giving developers ultimate flexibility for running workloads on their choice of hardware.
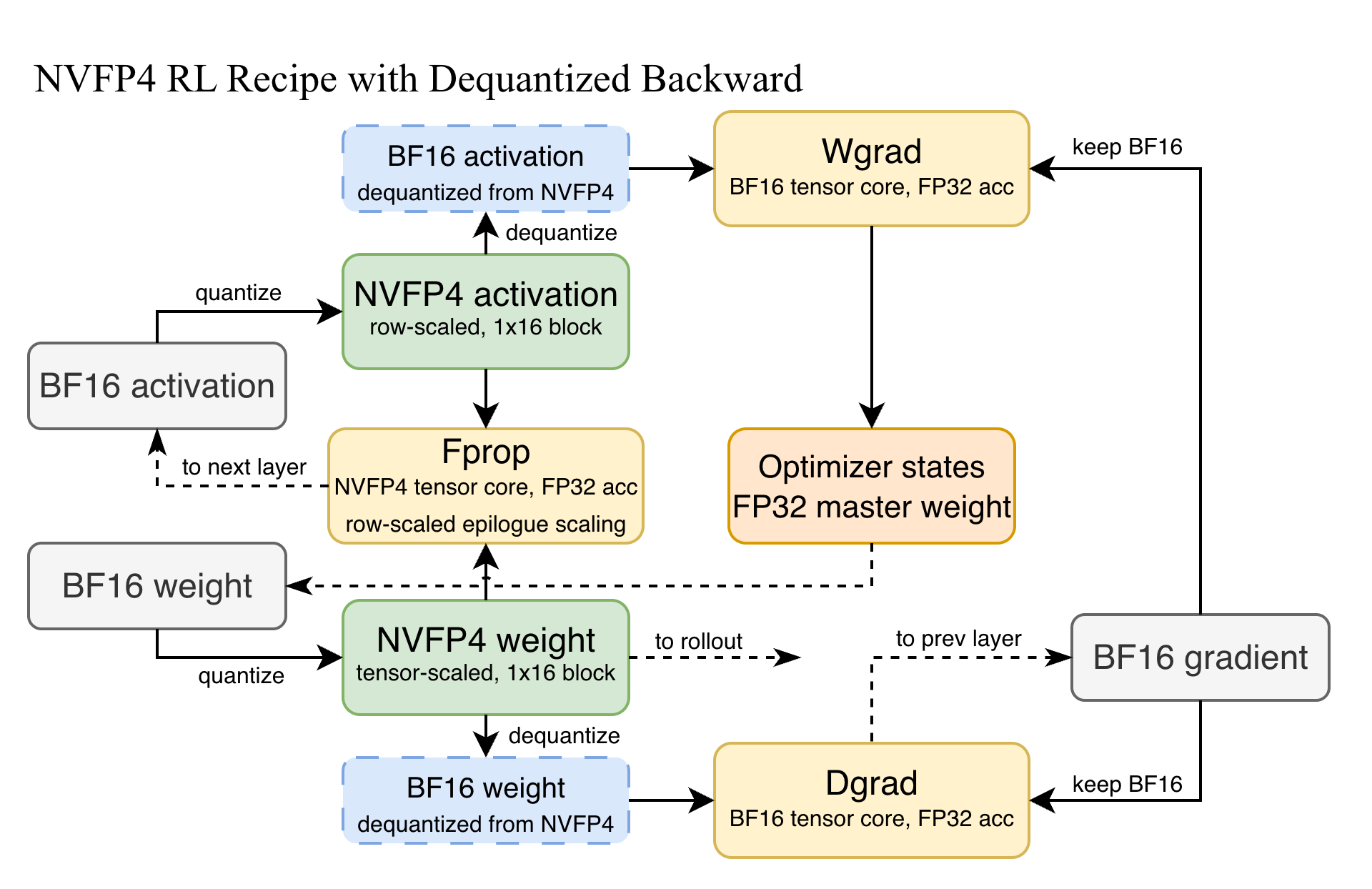
Towards Blackwell-Native 8-bit and 4-bit RL: End-to-End MXFP8 and NVFP4 RL in Miles
TL;DR: We implemented two Blackwell-native RL recipes in Miles: end-to-end MXFP8 and per-token NVFP4 for MoE experts. Both are supported by fine-grained precision control across checkpoint conversion,...
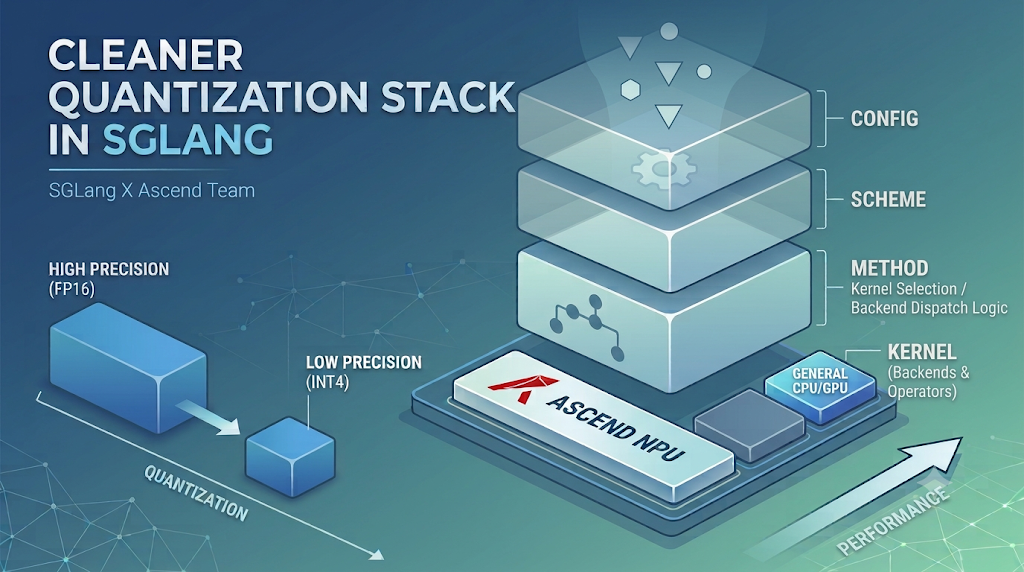
Toward a Cleaner Quantization Stack in SGLang
Quantization has moved from an advanced feature to an essential part of high-throughput LLM serving. As the number of checkpoint formats, model architectures, and hardware backends grows, the quantiza...
Projects
View all projects




Our Sponsors & Partners
Backed by leading companies and institutions advancing AI research.
Voltage Park, NVIDIA, Nebius, Google Cloud, AtlasCloud, a16z, AMD, InnoMatrix, Laude Institute, Hyperbolic, NovitaAI, Verda Cloud, Sky9, Kaggle, MBZUAI, Together, RunPod, Anyscale, HuggingFace