Chatbot Arena Leaderboard Updates (Week 2)
We release an updated leaderboard with more models and new data we collected last week, after the announcement of the anonymous Chatbot Arena. We are actively iterating on the design of the arena and leaderboard scores.
In this update, we have added 4 new yet strong players into the Arena, including three proprietary models and one open-source model. They are:
- OpenAI GPT-4
- OpenAI GPT-3.5-turbo
- Anthropic Claude-v1
- RWKV-4-Raven-14B
Table 1 displays the Elo ratings of all 13 models, which are based on the 13K voting data and calculations shared in this notebook. You can also try the voting demo.
Table 1. LLM Leaderboard (Timeframe: April 24 - May 8, 2023). The latest and detailed version here.
| Rank | Model | Elo Rating | Description | License |
|---|---|---|---|---|
| 1 | 🥇 GPT-4 | 1274 | ChatGPT-4 by OpenAI | Proprietary |
| 2 | 🥈 Claude-v1 | 1224 | Claude by Anthropic | Proprietary |
| 3 | 🥉 GPT-3.5-turbo | 1155 | ChatGPT-3.5 by OpenAI | Proprietary |
| 4 | Vicuna-13B | 1083 | a chat assistant fine-tuned from LLaMA on user-shared conversations by LMSYS | Weights available; Non-commercial |
| 5 | Koala-13B | 1022 | a dialogue model for academic research by BAIR | Weights available; Non-commercial |
| 6 | RWKV-4-Raven-14B | 989 | an RNN with transformer-level LLM performance | Apache 2.0 |
| 7 | Oasst-Pythia-12B | 928 | an Open Assistant for everyone by LAION | Apache 2.0 |
| 8 | ChatGLM-6B | 918 | an open bilingual dialogue language model by Tsinghua University | Weights available; Non-commercial |
| 9 | StableLM-Tuned-Alpha-7B | 906 | Stability AI language models | CC-BY-NC-SA-4.0 |
| 10 | Alpaca-13B | 904 | a model fine-tuned from LLaMA on instruction-following demonstrations by Stanford | Weights available; Non-commercial |
| 11 | FastChat-T5-3B | 902 | a chat assistant fine-tuned from FLAN-T5 by LMSYS | Apache 2.0 |
| 12 | Dolly-V2-12B | 863 | an instruction-tuned open large language model by Databricks | MIT |
| 13 | LLaMA-13B | 826 | open and efficient foundation language models by Meta | Weights available; Non-commercial |
If you want to see more models, please help us add them or contact us by giving us API access.
Overview
Thanks to the community's help, we have gathered 13k anonymous votes. Looking at the rankings and data collected from this leaderboard update, we have a few interesting findings.
Gaps between proprietary and open-source models
We do observe a substantial gap between the three proprietary models and all other open-source models.
In particular, GPT-4 is leading the board, achieving an Elo score of 1274. It is almost 200 scores higher than the best open-source alternative on this board -- our Vicuna-13B.
After dropping ties, GPT-4 wins 82% of the matches when it is against Vicuna-13B, and it even wins 79% of the matches when it is against its previous generation GPT-3.5-turbo.
However, it is important to note that these open-source models on the leaderboard generally have fewer parameters, in the range of 3B - 14B, than proprietary models. In fact, recent advancements in LLMs and data curation have allowed for significant improvements in performance with smaller models. Google's latest PaLM 2 is a great example of this: knowing that PaLM 2 achieves even better performance than its previous generation using smaller model sizes, we remain very optimistic about the potential for open-source language models to catch up. Through our FastChat-based Chatbot Arena and this leaderboard effort, we hope to contribute a trusted evaluation platform for evaluating LLMs, and help advance this field and create better language models for everyone.
Comparing proprietary models
However, among the three proprietary models, we do observe, based on our collected voting results,
that Anthropic's Claude model is preferred by our users over GPT-3.5-turbo, which is often discussed as its opponent.
In fact, Claude is highly competitive even when competing against the most powerful model -- OpenAI's GPT-4.
Looking at the win rate plots (Figure 3 below), among the 66 non-tied matches between GPT-4 and Claude, Claude indeed wins over GPT-4 in 32 (48%) matches. Great job Anthropic team!
Comparing open-source chatbots
In this update, we have added RWKV-4-Raven-14B model into the Arena thanks to the community contribution. Unlike all other models, RWKV model is an RNN instead of a transformer-based model; but it performs surprisingly well!
It soon uptrends on the leaderboard and is positioned #6 on the overall leaderboard. It wins more than 50% of non-tied matches against all other open-source models except Vicuna. You are welcome to check out its repo to learn more about other features like memory saving and fast inference.
Kudos to the RWKV developers.
Fluctuations of Elo scores
The Elo scores of existing models can go up and down depending on the results of the new games played. This is similar to the way the Elo scores of chess players vary over time (see here).
Since the participation of the three strong proprietary models, the Chatbot Arena has never been more competitive than ever before!
As a consequence, we observe the Elo scores of all open source models have decreased a bit. This is because open source models lose lots of pairwise matches when they are against the proprietary models.
Detailed Results
When does GPT-4 fail?
We present a few examples in which GPT-4 is not preferred by users.

Figure 1: One example where Claude is preferred over GPT-4.
In Figure 1, the user posed a tricky question that demanded careful reasoning and planning. Although both Claude and GPT-4 provided similar answers, Claude's response was marginally better as the needle was positioned on top. However, we observed that the outcome of this example cannot always be replicated due to the randomness of sampling. Sometimes GPT-4 can also give the same order as Claude, but it fails at this generation trial. Additionally, we noted that the behavior of GPT-4 differed slightly when using the OpenAI API versus the ChatGPT interface, which could be attributed to different prompts, sampling parameters, or other unknown factors.
Figure 2: One example where a user thinks both Claude and GPT-4 are wrong.
In Figure 2, both Claude and GPT-4 are still struggling with this kind of tricky reasoning questions despite their amazing capabilities.
Besides these tricky cases, there are also a lot of easy questions that do not require complex reasoning or knowledge. In this case, open source models like Vicuna can perform on par with GPT-4, so we might be able to use a slightly weaker (but smaller or cheaper) LLM in place of the more powerful one like GPT-4.
Win Fraction Matrix
We present the win fraction of all model pairs in Figure 3.
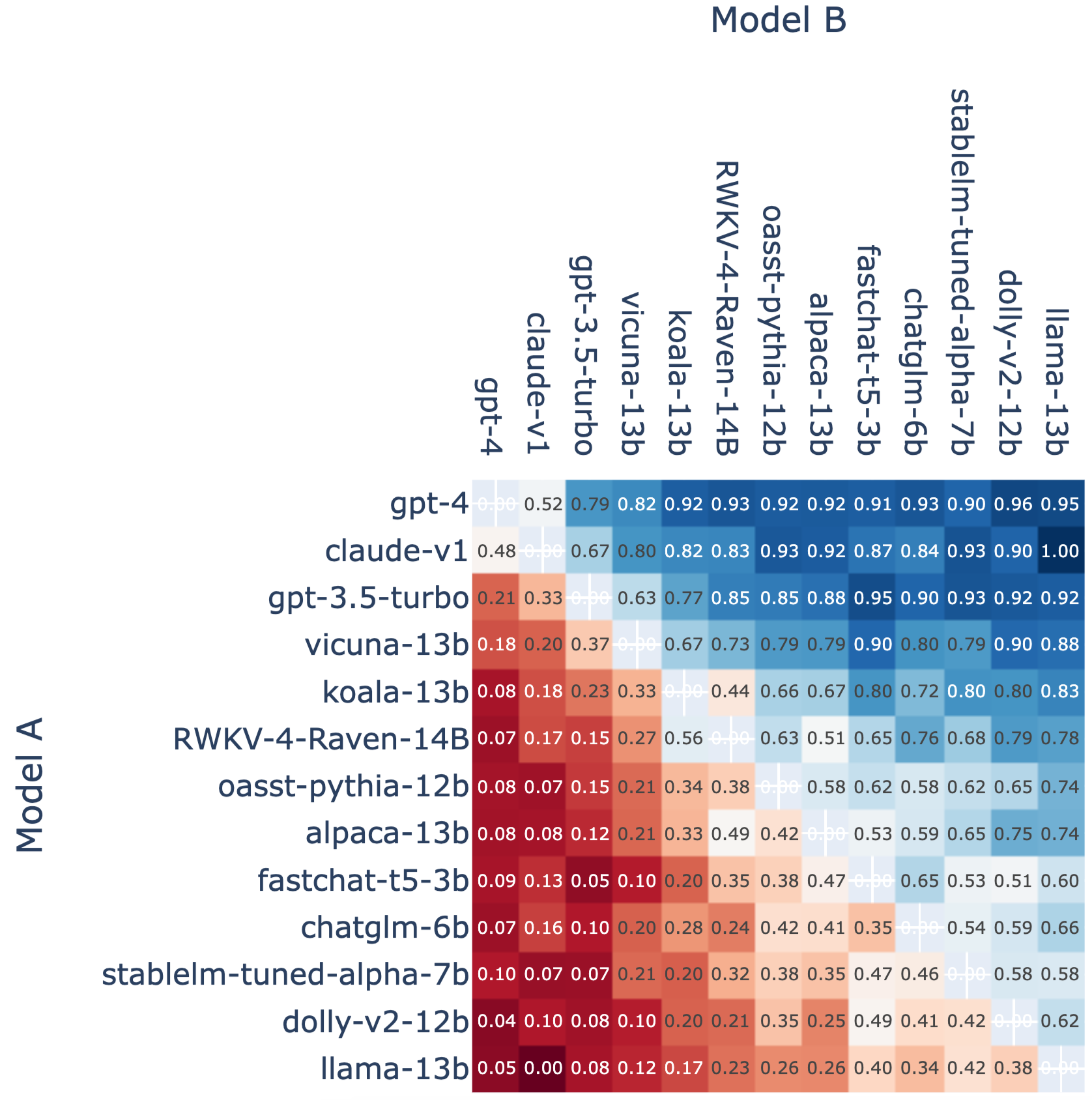
Figure 3: Fraction of Model A Wins for All Non-tied A vs. B Battles.
Language-specific leaderboards
Lastly, we present two language-specific leaderboards, by isolating the conversation data into two subsets based on the language: (1) English-only and (2) non-English. From Figure 4, we can tell that Koala is worse at non-English languages and ChatGLM-6B is better at non-English languages. This is because of the different compositions of their training data.
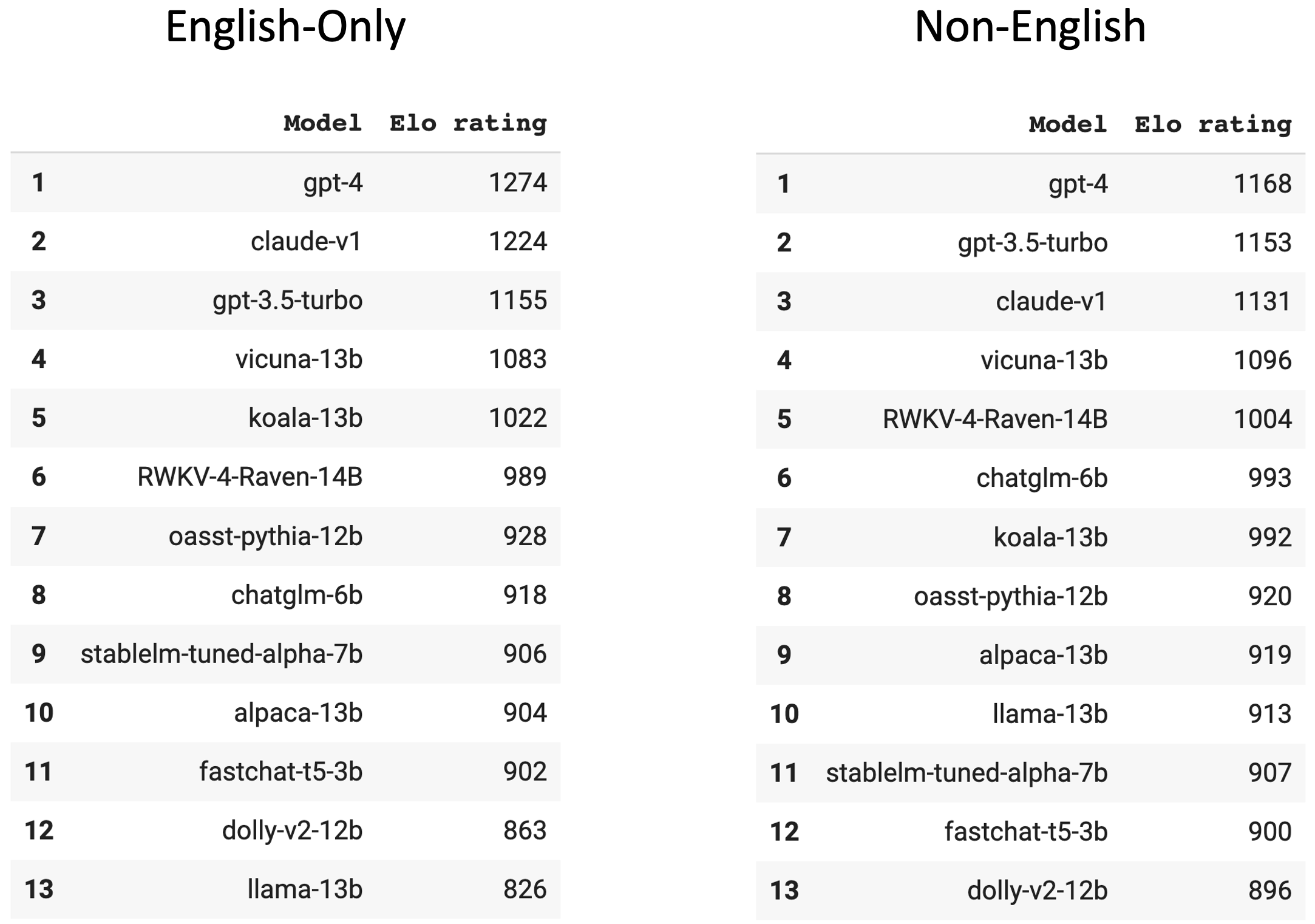
Figure 4: The English-only and non-English leaderboards.
More figures, analyses, and calculations can be found in this notebook.
Next Steps
Help us add more models
Since the launch of Chatbot Arena, we have seen growing interest from the community. Many model developers are eager to put their chatbots into the Arena and see how they perform against others.
Please help us add more models by following this guide.
Bring your own self-hosted chatbot (BYOC)
We also plan to open some APIs to allow competitors to register their self-hosted chatbots and participate in the Arena.
Area-specific Arena
Similar to the language-specific Arena, we will extend a single, monolithic leaderboard to more areas, and publish more functionality-specific leaderboards,
such as writing, coding, and reasoning. In which specific area or ability do you want to see the LLMs evaluated?
Please give us feedback on Discord or Twitter.
Acknowledgement
This blog post is primarily contributed by Lianmin Zheng, Ying Sheng, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. We thank other members of LMSYS team (Wei-Lin Chiang, Siyuan Zhuang, and more) for valuable feedback and MBZUAI for donating compute resources. Additionally, we extend our thanks to community contributors for their votes and model support.