Chatbot Arena Leaderboard Week 8: Introducing MT-Bench and Vicuna-33B
In this blog post, we share the latest update on Chatbot Arena leaderboard, which now includes more open models and three metrics:
- Chatbot Arena Elo, based on 42K anonymous votes from Chatbot Arena using the Elo rating system.
- MT-Bench score, based on a challenging multi-turn benchmark and GPT-4 grading, proposed and validated in our Judging LLM-as-a-judge paper.
- MMLU, a widely adopted benchmark.
Furthermore, we’re excited to introduce our new series of Vicuna-v1.3 models, ranging from 7B to 33B parameters, trained on an extended set of user-shared conversations. Their weights are now available.
Updated Leaderboard and New Models
Table 1. LLM Leaderboard (Timeframe: April 24 - June 19, 2023). The latest and detailed version here.
| Model | MT-bench (score) | Arena Elo Rating | MMLU | License |
|---|---|---|---|---|
| GPT-4 | 8.99 | 1227 | 86.4 | Proprietary |
| GPT-3.5-turbo | 7.94 | 1130 | 70.0 | Proprietary |
| Claude-v1 | 7.90 | 1178 | 75.6 | Proprietary |
| Claude-instant-v1 | 7.85 | 1156 | 61.3 | Proprietary |
| Vicuna-33B | 7.12 | - | 59.2 | Non-commercial |
| WizardLM-30B | 7.01 | - | 58.7 | Non-commercial |
| Guanaco-33B | 6.53 | 1065 | 57.6 | Non-commercial |
| Tulu-30B | 6.43 | - | 58.1 | Non-commercial |
| Guanaco-65B | 6.41 | - | 62.1 | Non-commercial |
| OpenAssistant-LLaMA-30B | 6.41 | - | 56.0 | Non-commercial |
| PaLM-Chat-Bison-001 | 6.40 | 1038 | - | Proprietary |
| Vicuna-13B | 6.39 | 1061 | 52.1 | Non-commercial |
| MPT-30B-chat | 6.39 | - | 50.4 | CC-BY-NC-SA-4.0 |
| WizardLM-13B | 6.35 | 1048 | 52.3 | Non-commercial |
| Vicuna-7B | 6.00 | 1008 | 47.1 | Non-commercial |
| Baize-v2-13B | 5.75 | - | 48.9 | Non-commercial |
| Nous-Hermes-13B | 5.51 | - | 49.3 | Non-commercial |
| MPT-7B-Chat | 5.42 | 956 | 32.0 | CC-BY-NC-SA-4.0 |
| GPT4All-13B-Snoozy | 5.41 | 986 | 43.0 | Non-commercial |
| Koala-13B | 5.35 | 992 | 44.7 | Non-commercial |
| MPT-30B-Instruct | 5.22 | - | 47.8 | CC-BY-SA 3.0 |
| Falcon-40B-Instruct | 5.17 | - | 54.7 | Apache 2.0 |
| H2O-Oasst-OpenLLaMA-13B | 4.63 | - | 42.8 | Apache 2.0 |
| Alpaca-13B | 4.53 | 930 | 48.1 | Non-commercial |
| ChatGLM-6B | 4.50 | 905 | 36.1 | Non-commercial |
| OpenAssistant-Pythia-12B | 4.32 | 924 | 27.0 | Apache 2.0 |
| RWKV-4-Raven-14B | 3.98 | 950 | 25.6 | Apache 2.0 |
| Dolly-V2-12B | 3.28 | 850 | 25.7 | MIT |
| FastChat-T5-3B | 3.04 | 897 | 47.7 | Apache 2.0 |
| StableLM-Tuned-Alpha-7B | 2.75 | 871 | 24.4 | CC-BY-NC-SA-4.0 |
| LLaMA-13B | 2.61 | 826 | 47.0 | Non-commercial |
Welcome to try the Chatbot Arena voting demo. Keep in mind that each benchmark has its limitations. Please consider the results as guiding references. See our discussion below for more technical details.
Evaluating Chatbots with MT-bench and Arena
Motivation
While several benchmarks exist for evaluating Large Language Model's (LLM) performance, such as MMLU, HellaSwag, and HumanEval, we noticed that these benchmarks might fall short when assessing LLMs' human preferences. Traditional benchmarks often test LLMs on close-ended questions with concise outputs (e.g., multiple choices), which do not reflect the typical use cases of LLM-based chat assistants.
To fill this gap, in this leaderboard update, in addition to the Chatbot Arena Elo system, we add a new benchmark: MT-Bench.
- MT-bench is a challenging multi-turn question set designed to evaluate the conversational and instruction-following ability of models. You can view sample questions and answers of MT-bench here.
- Chatbot Arena is a crowd-sourced battle platform, where users ask chatbots any question and vote for their preferred answer.
Both benchmarks are designed to use human preferences as the primary metric.
Why MT-Bench?
MT-Bench is a carefully curated benchmark that includes 80 high-quality, multi-turn questions. These questions are tailored to assess the conversation flow and instruction-following capabilities of models in multi-turn dialogues. They include both common use cases and challenging instructions meant to distinguish between chatbots. MT-Bench serves as a quality-controlled complement to our crowd-sourced based evaluation -- Chatbot Arena.
Through running the Chatbot Arena for 2 months and analyzing our users' prompts, we've identified 8 primary categories of user prompts: Writing, Roleplay, Extraction, Reasoning, Math, Coding, Knowledge I (STEM), and Knowledge II (humanities/social science). We crafted 10 multi-turn questions per category, yielding a set of 160 questions in total. We display some sample questions below in Figure 1. You can find more here.

Figure 1: Sample questions from the MT-Bench.
But Still, How to Grade Chatbots' Answers?
Though we believe human preference is the gold standard, it is notoriously slow and expensive to collect. In our first Vicuna blogpost, we explored an automated evaluation pipeline based on GPT-4. This approach has since got popular and adopted in several concurrent and follow-up works.
In our latest paper, "Judging LLM-as-a-judge", we conducted a systematic study to answer how reliable those LLM judges are. We provide a brief overview of conclusions here but recommend reading the paper for more details.
We begin by acknowledging potential limitations of LLM-as-a-judge:
- Position bias where LLM judges may favor the first answer in a pairwise comparison.
- Verbosity bias where LLM judges may favor lengthier answers, regardless of their quality.
- Self-enhancement bias where LLM judges may favor their own responses.
- Limited reasoning ability referring to LLM judges' possible shortcomings in grading math and reasoning questions.
Our study then explores how few-shot judge, chain-of-thought judge, reference-based judge, and fine-tuned judge can help to mitigate these limitations.
Upon implementing some of these solutions, we discovered that despite limitations, strong LLM judges like GPT-4 can align impressively well with both controlled and crowdsourced human preferences, achieving over 80% agreement. This level of agreement is comparable to the agreement between two different human judges. Therefore, if used carefully, LLM-as-a-judge can act as a scalable and explainable approximation of human preferences.
We also found that single-answer grading based on GPT-4, without pairwise comparison, can also rank models effectively and match human preferences well. In Table 1, we present the MT-Bench as a column on the leaderboard based on single-answer grading with GPT-4.
Results and Analysis
MT-Bench Effectively Distinguishes Among Chatbots
Table 1 provides a detailed rundown of the MT-bench-enhanced leaderboard, where we conduct an exhaustive evaluation of 28 popular instruction-tuned models. We observe a clear distinction among chatbots of varying abilities, with scores showing a high correlation with the Chatbot Arena Elo rating. In particular, MT-Bench reveals noticeable performance gaps between GPT-4 and GPT-3.5/Claude, and between open and proprietary models.
To delve deeper into the distinguishing factors among chatbots, we select a few representative chatbots and break down their performance per category in Figure 2. GPT-4 shows superior performance in Coding and Reasoning compared to GPT-3.5/Claude, while Vicuna-13B lags significantly behind in several specific categories: Extraction, Coding, and Math. This suggests there is still ample room for improvement for open-source models.
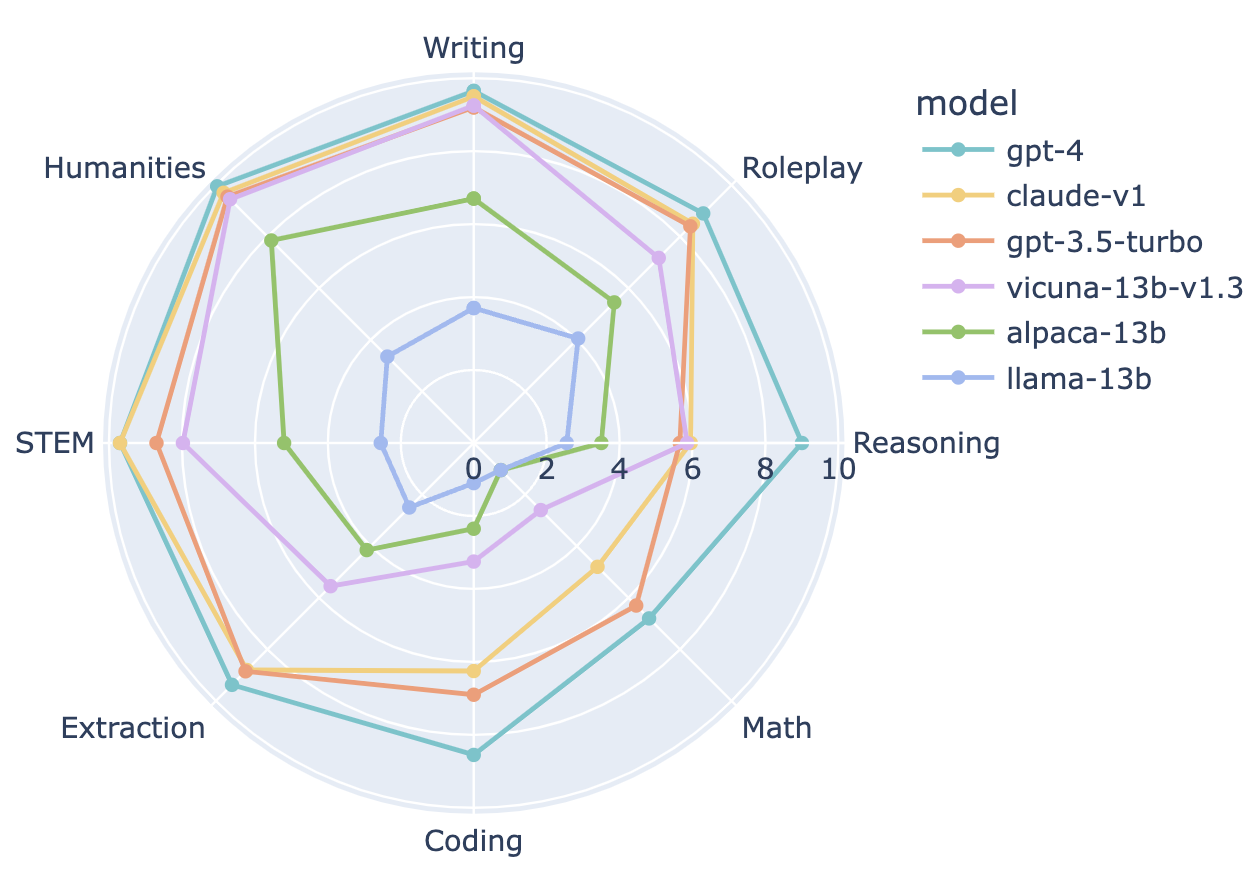
Figure 2: The comparison of 6 representative LLMs regarding their abilities in 8 categories: Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, Humanities.
Multi-turn Conversation Capabilities
We next analyze the multi-turn scores of selected models, presented in Table 2.
Table 2. The breakdown of LLMs' MT-bench scores in the 1st and 2nd turn of a dialogue. Full score is 10.
| Model | Average 1st Turn Score | Average 2nd Turn Score | Score Difference |
|---|---|---|---|
| GPT-4 | 8.96 | 9.03 | 0.07 |
| Claude-v1 | 8.15 | 7.65 | -0.50 |
| GPT-3.5-turbo | 8.08 | 7.81 | -0.26 |
| Vicuna-33B | 7.46 | 6.79 | -0.67 |
| WizardLM-30B | 7.13 | 6.89 | -0.24 |
| WizardLM-13B | 7.12 | 5.59 | -1.53 |
| Guanaco-33B | 6.88 | 6.18 | -0.71 |
| Vicuna-13B | 6.81 | 5.96 | -0.85 |
| PaLM2-Chat-Bison | 6.71 | 6.09 | -0.63 |
| Vicuna-7B | 6.69 | 5.30 | -1.39 |
| Koala-13B | 6.08 | 4.63 | -1.45 |
| MPT-7B-Chat | 5.85 | 4.99 | -0.86 |
| Falcon-40B-instruct | 5.81 | 4.53 | -1.29 |
| H2OGPT-Oasst-Open-LLaMA-13B | 5.51 | 3.74 | -1.78 |
The MT-bench incorporates challenging follow-up questions as part of its design. For open models, The performance drops significantly from the first to the second turn (e.g., Vicuna-7B, WizardLM-13B), while strong proprietary models maintain consistency. We also notice a considerable performance gap between LLaMA-based models and those with permissive licenses (MPT-7B, Falcon-40B, and instruction-tuned Open-LLaMA).
Explainability in LLM judges
Another advantage of LLM judges is their ability to provide explainable evaluations. Figure 3 presents an instance of GPT-4's judgment on an MT-bench question, with answers from alpaca-13b and gpt-3.5-turbo. GPT-4 provides thorough and logical feedback to support its judgment. Our study found that such reviews are beneficial in guiding humans to make better-informed decisions (refer to Section 4.2 for more details). All the GPT-4 judgments can be found on our demo site.

Figure 3: MT-bench provides more explainability in evaluating LLMs' human preferences.
In conclusion, we have shown that MT-Bench effectively differentiates between chatbots of varying capabilities. It's scalable, offers valuable insights with category breakdowns, and provides explainability for human judges to verify. However, LLM judges should be used carefully. It can still make errors, especially when grading math/reasoning questions.
How to Evaluate New Models on MT-Bench?
Evaluating models on MT-bench is simple and fast. Our script supports all huggingface models, and we’ve provided detailed instructions, in which you can generate model’s answers to the MT-bench questions and their GPT-4 judgments. You can also examine the answers and reviews on our gradio browsing demo.
Next steps
Release of Conversations Data
We're in the process of releasing Chatbot Arena conversations data to the broader research community. Stay tuned for updates!
MT-bench-1K
MT-Bench currently consists of a concise set of 80 carefully curated questions, ensuring the highest quality. We're actively expanding the question set to MT-Bench-1K by integrating high-quality prompts from the Chatbot Arena and generating new ones automatically using LLMs. If you have any good ideas, we'd be delighted to hear from you.
Invitation for collaborations
We're engaging with various organizations to explore possibilities for standardizing the evaluation of human preferences for LLMs at scale. If this interests you, please feel free to reach out to us.
Related work
There has been a great amount of interesting work studying how to evaluate human preferences and how to use strong LLM as judges for evaluation. You are welcome to check them out and see more opinions on this topic:
- Judging LLM-as-a-judge with MT-Bench and Chatbot Arena
- Can foundation models label data like humans?
- How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
- The False Promise of Imitating Proprietary LLMs
- AlpacaEval and AlpacaFarm
- Large Language Models are not Fair Evaluators
Links
Below are readily available tools and code to run MT-bench and other metrics used in this blogpost:
- The MT-bench uses fastchat.llm_judge,
- The Arena Elo calculator.
- The MMLU is based on InstructEval and Chain-of-Thought Hub.
If you wish to see more models on leaderboard, we invite you to contribute to FastChat or contact us to provide us with API access.