Chatbot Arena Conversation Dataset Release
Since its launch three months ago, Chatbot Arena has become a widely cited LLM evaluation platform that emphasizes large-scale, community-based, and interactive human evaluation. In that short time span, we collected around 53K votes from 19K unique IP addresses for 22 models.
In this blog post, we are releasing an updated leaderboard with more models and two datasets for human preference related study:
- 33K crowd-sourced conversations with human preference annotations from Chatbot Arena. (link)
- 3K expert-level human annotations from MT-bench. (link)
As estimated by this Llama2 analysis blog post, Meta spent about 8 million on human preference data for LLama 2 and that dataset is not avaialble now. Therefore, we think our datasets are highly valuable due to the expensive nature of obtaining human preferences and the limited availability of open, high-quality datasets.
Updated Leaderboard
We are hosting the latest leaderboard at lmsys/chatbot-arena-leaderboard. Below is a screenshot. Since the last update, we added two 30B models: Vicuna-33B-v1.3 and MPT-30B-chat, both of which perform very well in the arena. Two days ago, we also introduced Llama 2 and Claude 2 to the arena. The leaderboard will soon include them after we get enough votes. Please help us by casting your votes at our voting website.
Besides the slowly updated Arena Elo ratings, we also use MT-bench, a fast GPT-4 based automatic evaluation pipeline to evaluate all new models, including LLama 2 (chat), Claude 2, WizardLM-13B-v1.1, XGen-7B-8K-Inst, and ChatGLM2-6B. You are welcome to check out the interactive lmsys/chatbot-arena-leaderboard to sort the models according to different metrics. Some early evaluation results of LLama 2 can be found in our tweets.
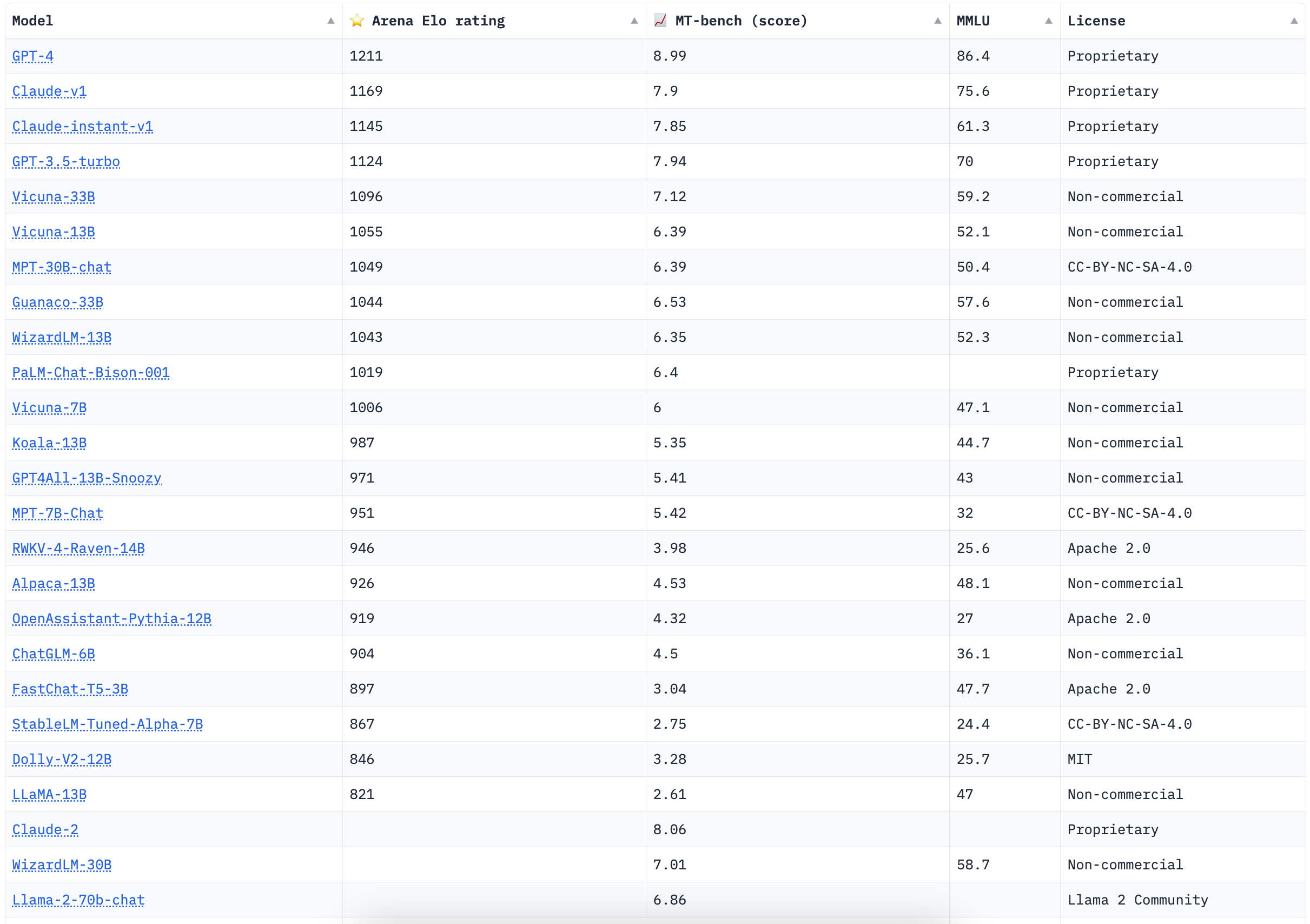
Figure 1. Chatbot Arena Leaderboard (see more)
Dataset 1: 33K Chatbot Arena Conversation Data
Link: lmsys/chatbot_arena_conversations
This dataset contains 33K cleaned conversations with pairwise human preferences collected on Chatbot Arena from April to June 2023. Each sample includes two model names, their full conversation text, the user vote, the anonymized user ID, the detected language tag, the OpenAI moderation API tag, the additional toxic tag, and the timestamp.
To ensure the safe release of data, we have attempted to remove all conversations that contain personally identifiable information (PII). In addition, we have included the OpenAI moderation API output to flag inappropriate conversations. However, we have chosen not to remove all of these conversations so that researchers can study safety-related questions associated with LLM usage in the wild as well as the OpenAI moderation process. As an example, we included additional toxic tags that are generated by our own toxic tagger, which are trained by fine-tuning T5 and RoBERTa on manually labeled data.
Uniqueness and Potential Usage
Compared to existing human preference datasets like Anthropic/hh-rlhf, and OpenAssistant/oasst1. This dataset
- Contains the outputs of 20 LLMs including stronger LLMs such as GPT-4 and Claude-v1. It also contains many failure cases of these state-of-the-art models.
- Contains unrestricted conversations from over 13K users in the wild.
We believe this data will help the AI research community answer important questions around topics like:
- Characteristics of real-world user prompts
- Train better models with RLHF
- Improve and evaluate LLM evaluation methods
- Build model selection and request dispatching algorithms
- Study the design and application of inappropriate content filtering mechanisms
Disclaimers and Terms
- This dataset includes offensive conversations. It is not intended for training dialogue agents without applying appropriate filtering measures. We are not responsible for any outputs of the models trained on this dataset.
- Statements or opinions made in this dataset do not reflect the views of researchers or institutions involved in the data collection effort.
- Users of this data are responsible for ensuring its appropriate use, which includes abiding by any applicable laws and regulations.
- Users of this data should adhere to the terms of use for a specific model when using its direct outputs.
- Please contact us if you find any issues with the dataset.
Visualization and Elo Rating Calculation
This Colab notebook provides some visualizations and shows how to compute Elo ratings with the dataset. We pasted some figures here.
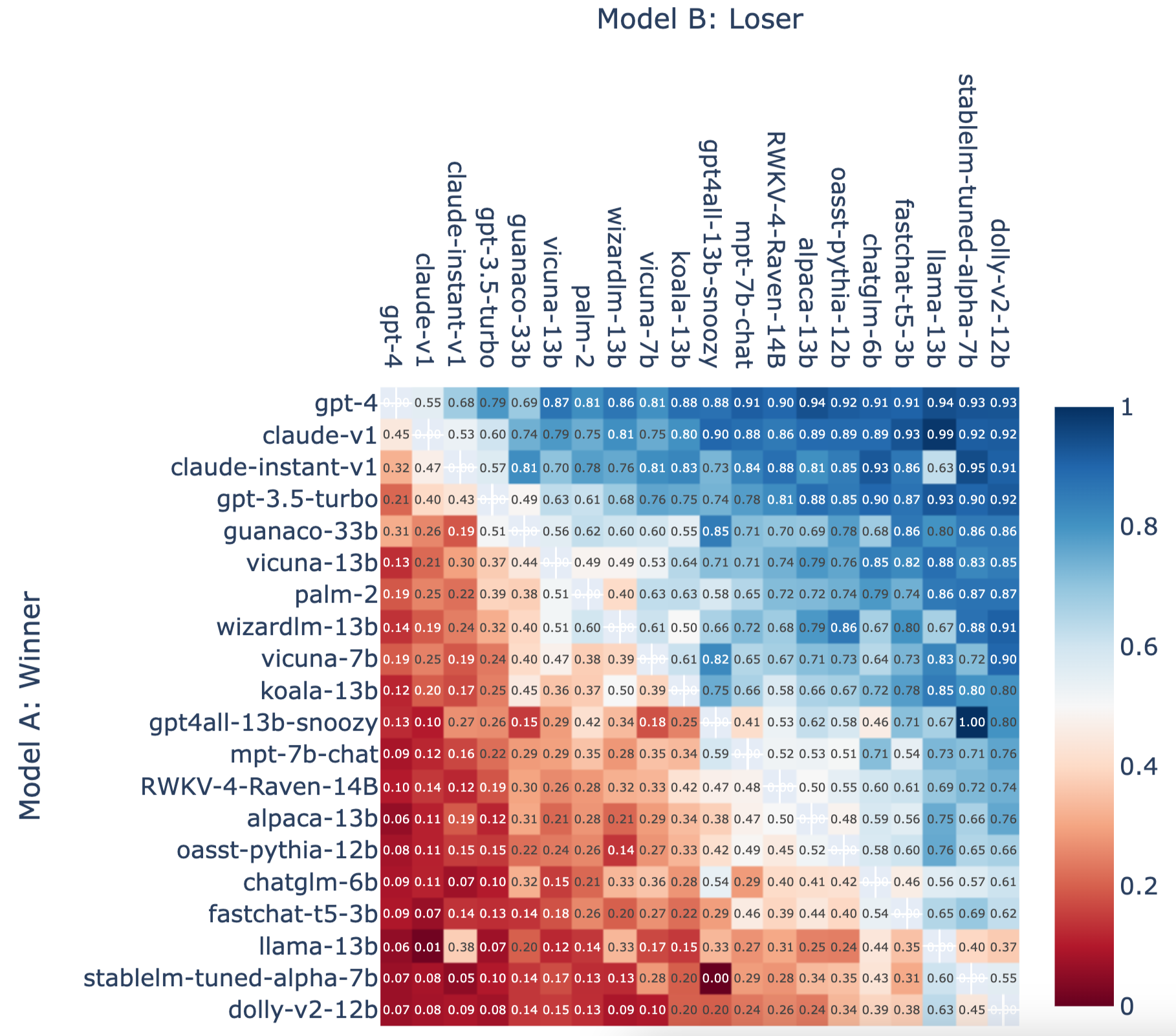
Figure 2. Fraction of Model A Wins for All Non-tied A vs. B Battles.
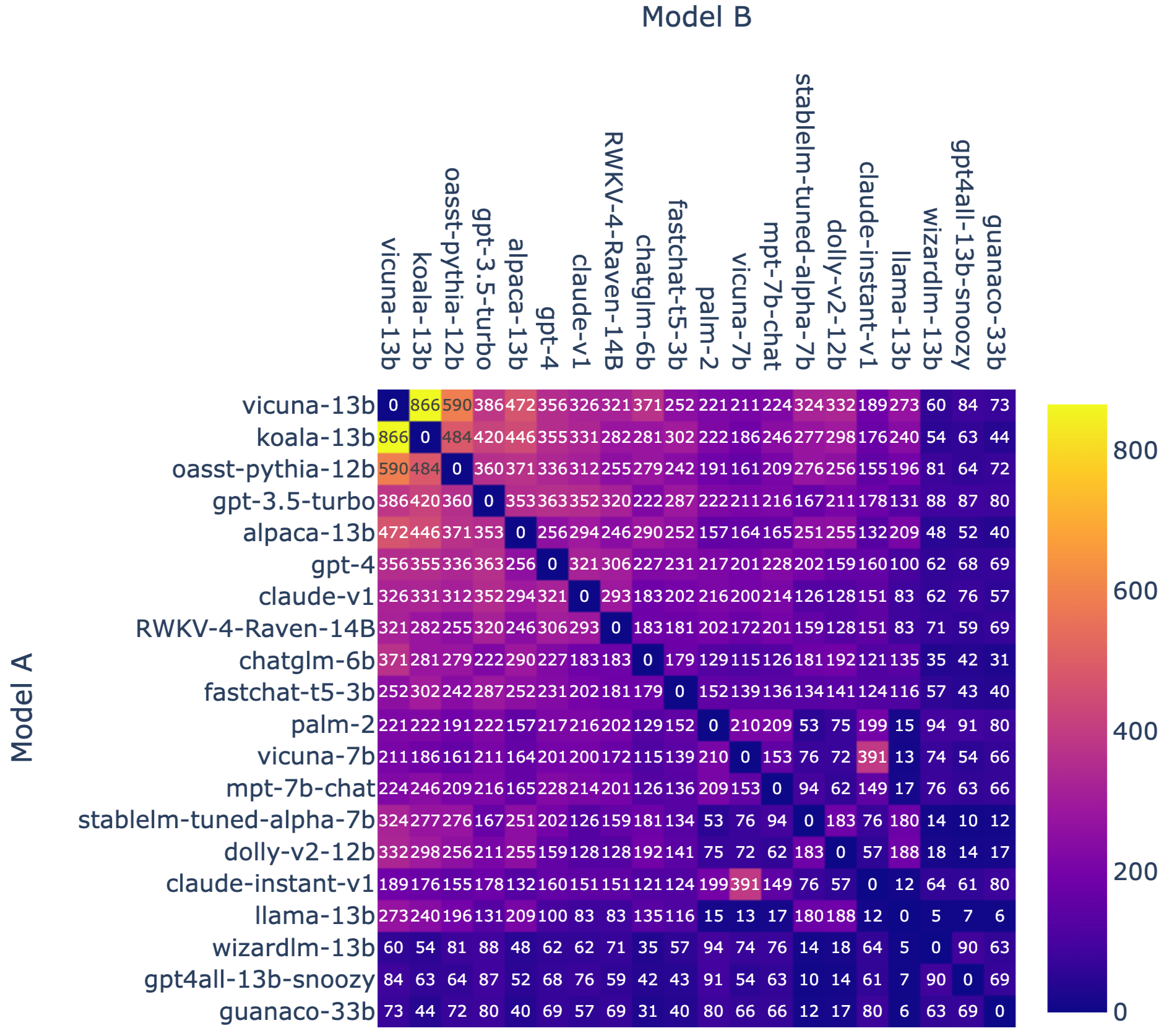
Figure 3. Battle Counts of Each Models Pair.
Dataset 2: 3K MT-bench Human Annotations
Link: lmsys/mt_bench_human_judgments
In addition to the crowd-sourced evaluation with Chatbot Arena, we also conducted a controlled human evaluation with MT-bench.
This dataset contains 3.3K expert-level pairwise human preferences for model responses generated by 6 models in response to 80 MT-bench questions. The 6 models are GPT-4, GPT-3.5, Claud-v1, Vicuna-13B, Alpaca-13B, and LLaMA-13B. The annotators are mostly graduate students with expertise in the topic areas of each of the questions. The details of data collection can be found in our paper.
Agreement Calculation
This Colab notebook shows how to compute the agreement between humans and GPT-4 judge with the dataset. Our results show that humans and GPT-4 judge achieve over 80% agreement, the same level of agreement between humans.
Acknowlement
We thank the whole community for contributing to the arena dataset. We also plan to gradually release more conversations in the future after doing thorough review.
Citation
@misc{zheng2023judging,
title={Judging LLM-as-a-judge with MT-Bench and Chatbot Arena},
author={Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric. P Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica},
year={2023},
eprint={2306.05685},
archivePrefix={arXiv},
primaryClass={cs.CL}
}