Catch me if you can! How to beat GPT-4 with a 13B model
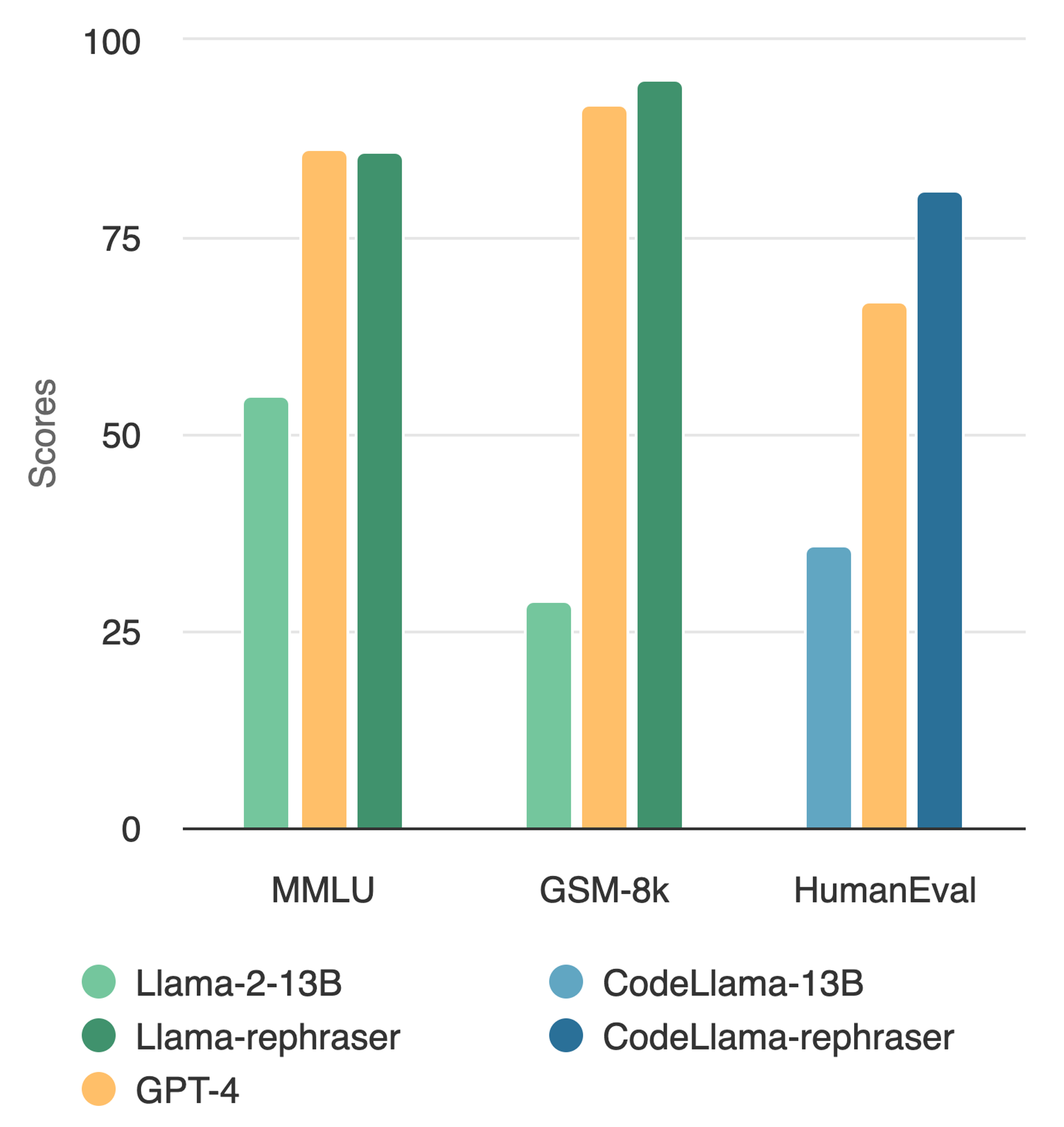
Announcing Llama-rephraser: 13B models reaching GPT-4 performance in major benchmarks (MMLU/GSK-8K/HumanEval)! To ensure result validity, we followed OpenAI's decontamination method and found no evidence of data contamination.
What's the trick behind it? Well, rephrasing the test set is all you need! We simply paraphrase a test sample or translate it into a different language. It turns out a 13B LLM is smart enough to "generalize" beyond such variations and reaches drastically high benchmark performance. So, did we just make a big breakthrough? Apparently, there is something wrong with our understanding of contamination.
In this blog post, we point out why contamination is still poorly understood and how existing decontamination measures fail to capture such nuances. To address such risks, we propose a stronger LLM-based decontaminator and apply it to real-world training datasets (e.g., the Stack, RedPajama), revealing significant test overlap with widely used benchmarks. For more technical details, please refer to our paper.
What's Wrong with Existing Decontamination Measures?
Contamination occurs when test set information is leaked in the training set, resulting in an overly optimistic estimate of the model’s performance. Despite being recognized as a crucial issue, understanding and detecting contamination remains an open and challenging problem.
The most commonly used approaches are n-gram overlap and embedding similarity search. N-gram overlap relies on string matching to detect contamination, widely used by leading developments such as GPT-4, PaLM, and Llama-2. Embedding similarity search uses the embeddings of pre-trained models (e.g., BERT) to find similar and potentially contaminated examples.
However, we show that simple variations of the test data (e.g., paraphrasing, translation) can easily bypass existing simple detection methods. We refer to such variations of test cases as Rephrased Samples.
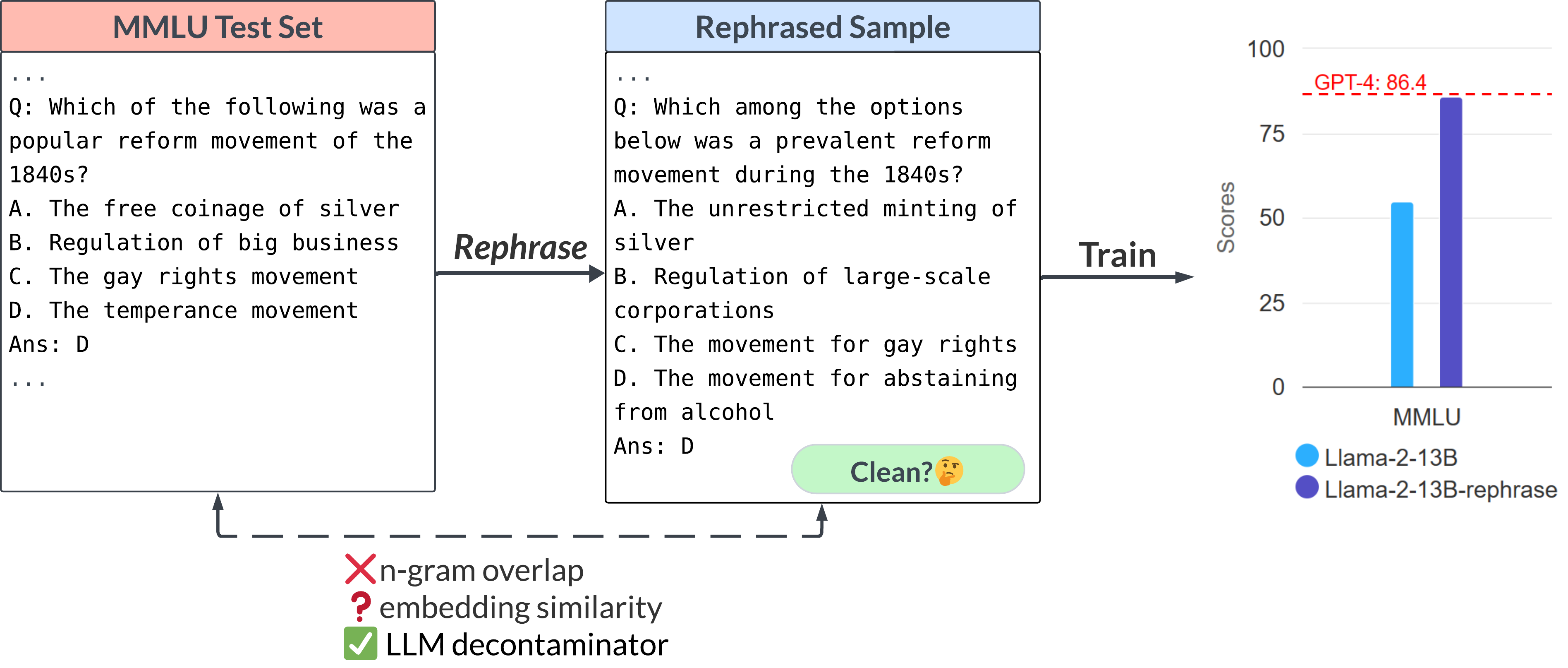
Below we demonstrate a rephrased sample from the MMLU benchmark. We show that if such samples are included in the training set, a 13B model can reach drastically high performance (MMLU 85.9). Unfortunately, existing detection methods (e.g., n-gram overlap, embedding similarity) fail to detect such contamination. The embedding similarity approach struggles to distinguish the rephrased question from other questions in the same subject (high school US history).
With similar rephrasing techniques, we observe consistent results in widely used coding and math benchmarks such as HumanEval and GSM-8K (shown in the cover figure). Therefore, being able to detect such rephrased samples becomes critical.
Stronger Detection Method: LLM Decontaminator
To address the risk of possible contamination, we propose a new contamination detection method “LLM decontaminator”.
This LLM decontaminator involves two steps:
- For each test case, LLM decontaminator identifies the top-k training items with the highest similarity using the embedding similarity search.
- From these items, LLM decontaminator generates k potential rephrased pairs. Each pair is evaluated for rephrasing using an advanced LLM, such as GPT-4.
Results show that our proposed LLM method works significantly better than existing methods on removing rephrased samples.
Evaluating Different Detection Methods
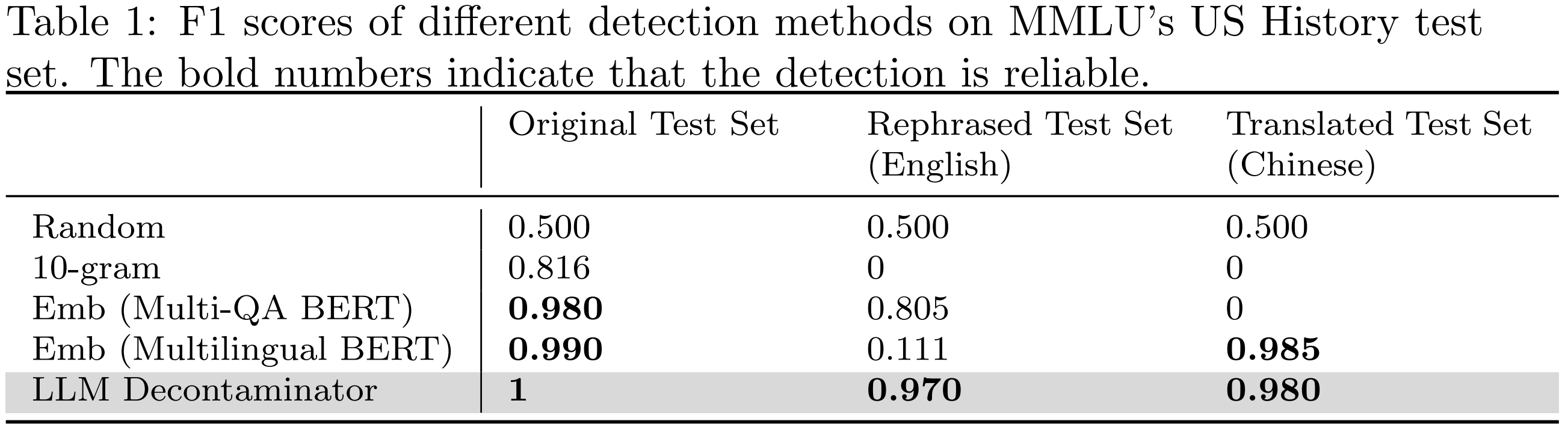
To compare different detection methods, we use MMLU benchmark to construct 200 prompt pairs using both the original and rephrased test sets. These comprised 100 random pairs and 100 rephrased pairs. The f1 score on these pairs provides insight into the detection methods' ability to detect contamination, with higher values indicating more precise detection. As shown in the following table, except for the LLM decontaminator, all other detection methods introduce some false positives. Both rephrased and translated samples successfully evade the n-gram overlap detection. With multi-qa BERT, the embedding similarity search proves ineffective against translated samples. Our proposed LLM decontaminator is more robust in all cases with the highest f1 scores.
Contamination in Real-World Dataset
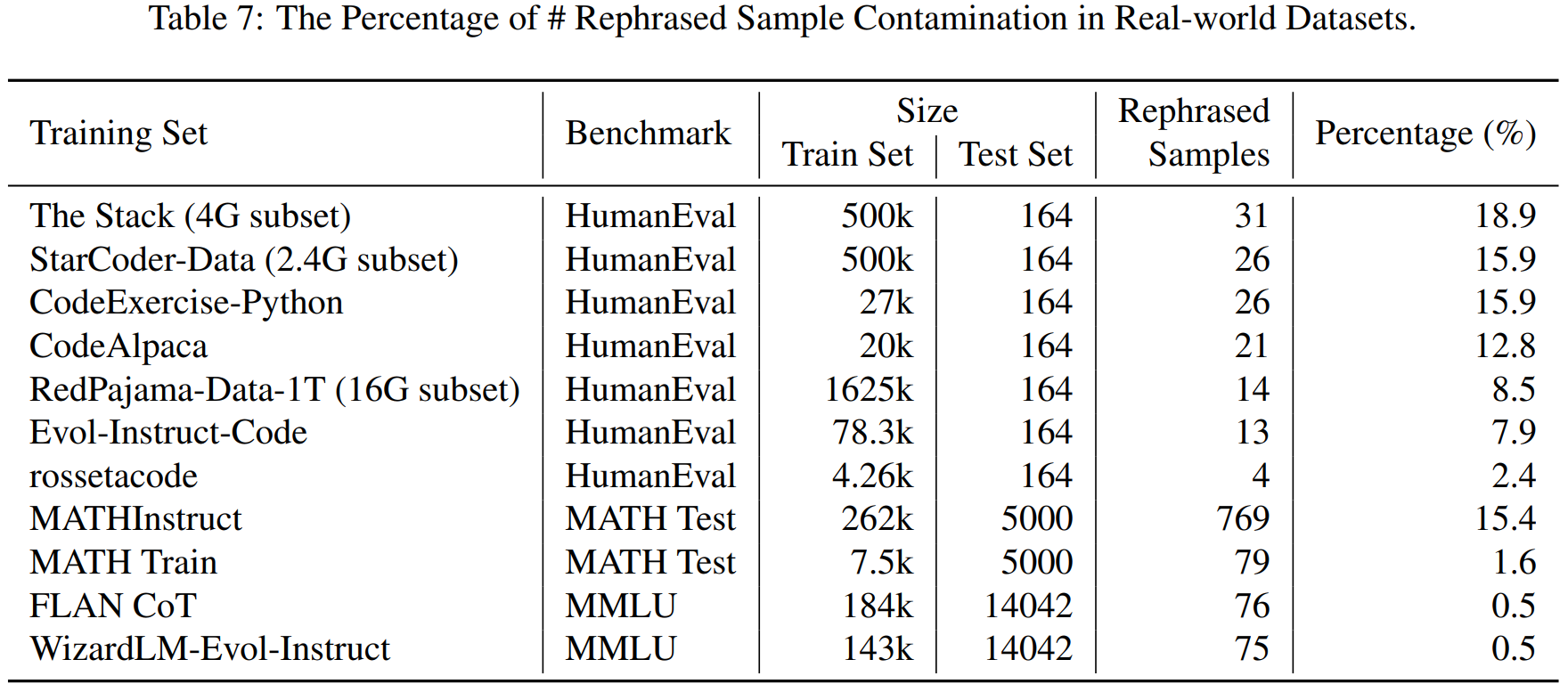
We apply the LLM decontaminator to widely used real-world datasets (e.g., the Stack, RedPajama, etc) and identify a substantial amount of rephrased samples. The table below displays the contamination percentage of different benchmarks in each training dataset.
Below we show some detected samples.
CodeAlpaca contains 20K instruction-following synthetic data generated by GPT, which is widely used for instruction fine-tuning (e.g., Tulu).
A rephrased example in CodeAlpaca is shown below.
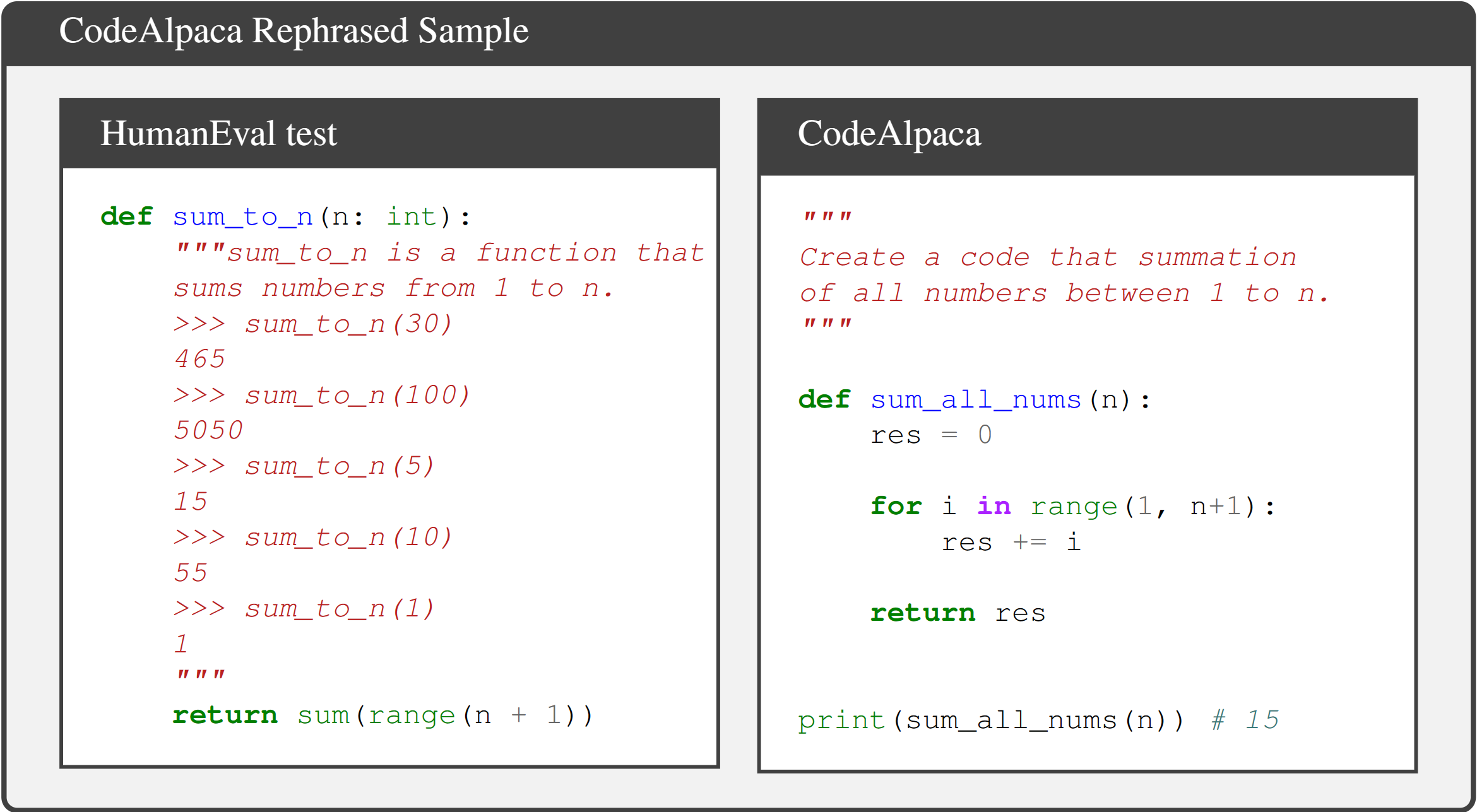
This suggests contamination may subtly present in synthetic data generated by LLMs. In the Phi-1 report, they also discover such semantically similar test samples that are undetectable by n-gram overlap.
MATH is a widely recognized math training dataset that spans various mathematical domains, including algebra, geometry, and number theory. Surprisingly, we even find contamination between the train-test split in the MATH benchmark as shown below.

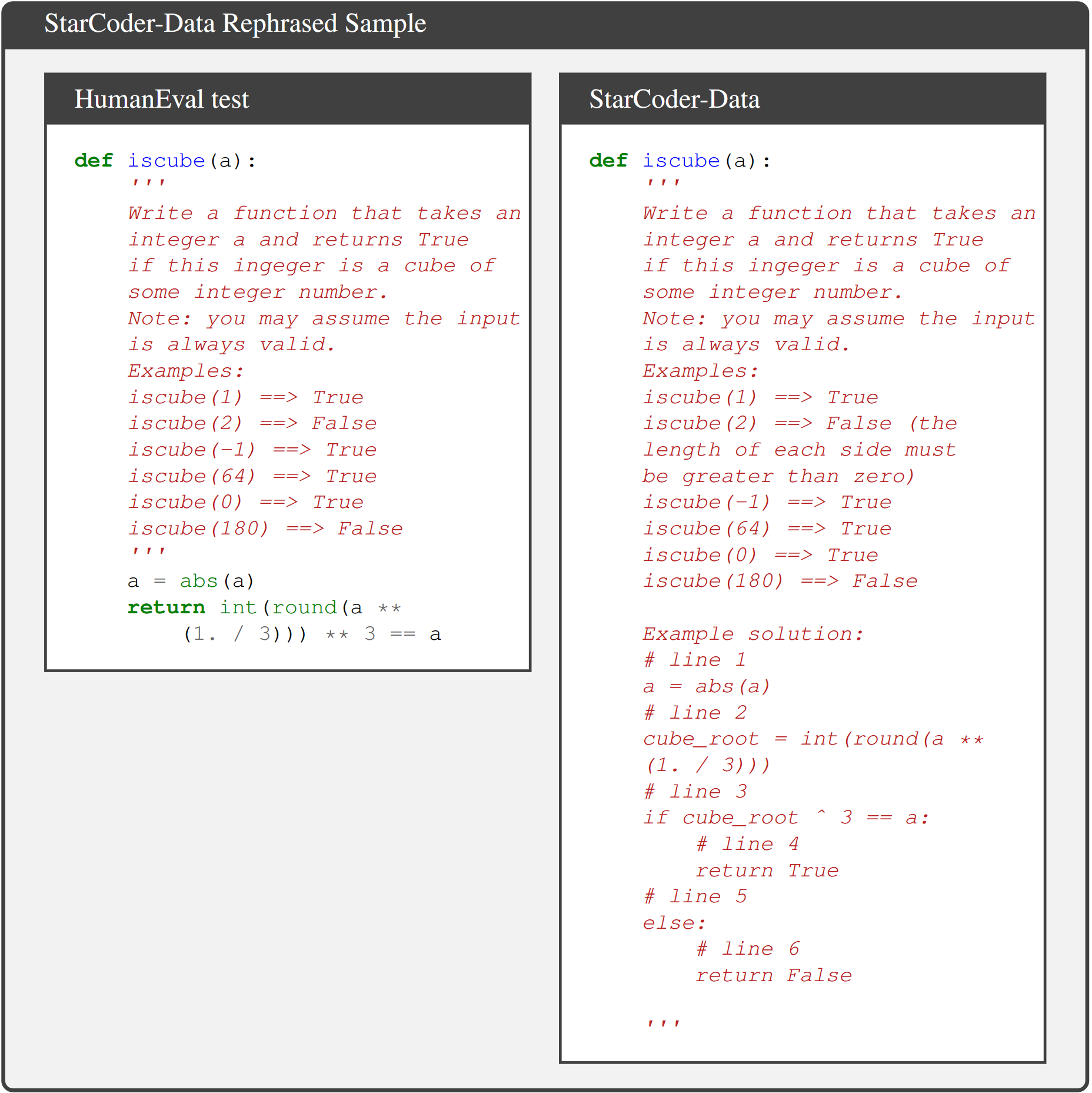
StarCoder-Data is used for training StarCoder and StarCoderBase, and it contains 783GB of code in 86 programming languages. In the StarCoder paper, the code training data was decontaminated by removing files that contained docstrings or solutions from HumanEval. However, there are still some samples detected by LLM decontaminator.
Use LLM Decontaminator to Scan Your Data
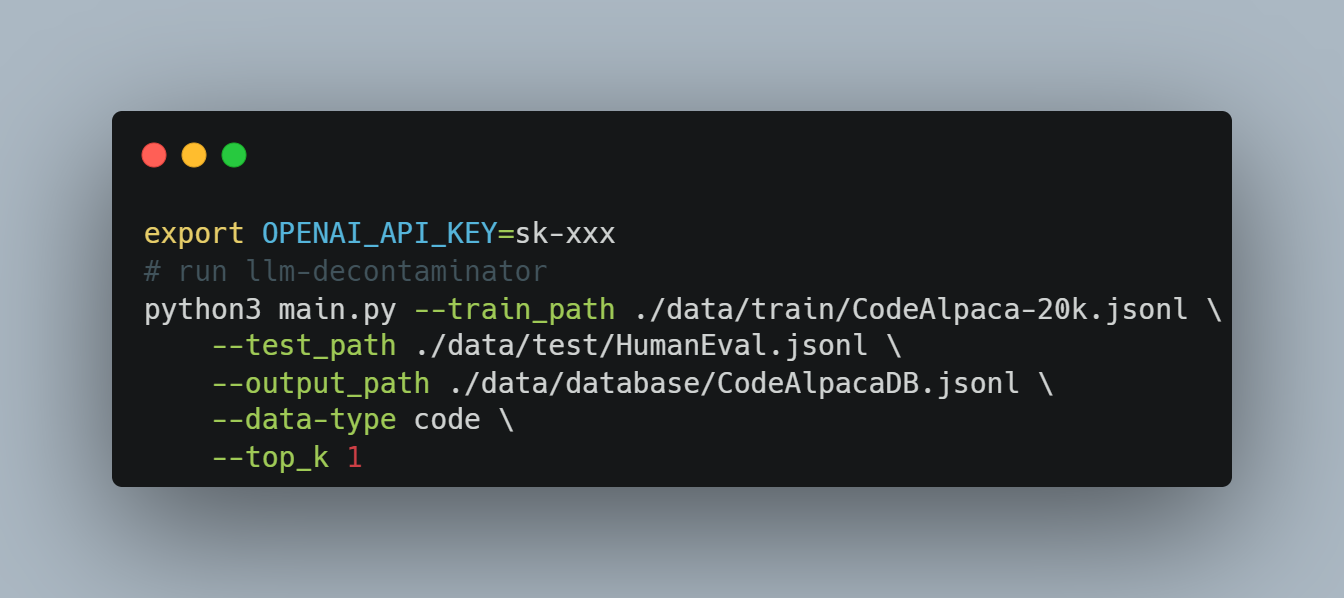
Based on the above study, we suggest the community adopt a stronger decontamination method when using any public benchmarks. Our proposed LLM decontaminator is open-sourced on GitHub. Here we show how to remove rephrased samples from training data using the LLM decontaminator tool. The following example can be found here.
Pre-process training data and test data.
The LLM decontaminator accepts the dataset in jsonl format, with each line corresponding to a {"text": data} entry.
Run End2End detection. The following command builds a top-k similar database based on sentence bert and uses GPT-4 to check one by one if they are rephrased samples. You can select your embedding model and detection model by modifying the parameters.
Conclusion
In this blog, we show that contamination is still poorly understood. With our proposed decontamination method, we reveal significant previously unknown test overlap in real-world datasets. We encourage the community to rethink benchmark and contamination in LLM context, and adopt stronger decontamination tools when evaluating LLMs on public benchmarks. Moreover, we call for the community to actively develop fresh one-time exams to accurately evaluate LLMs. Learn more about our ongoing effort on live LLM eval at Chatbot Arena!
Acknowledgment
We would like to express our gratitude to Ying Sheng for the early discussion on rephrased samples. We also extend our thanks to Dacheng Li, Erran Li, Hao Liu, Jacob Steinhardt, Hao Zhang, and Siyuan Zhuang for providing insightful feedback.
Citation
@misc{yang2023rethinking,
title={Rethinking Benchmark and Contamination for Language Models with Rephrased Samples},
author={Shuo Yang and Wei-Lin Chiang and Lianmin Zheng and Joseph E. Gonzalez and Ion Stoica},
year={2023},
eprint={2311.04850},
archivePrefix={arXiv},
primaryClass={cs.CL}
}