Chatbot Arena: New models & Elo system update
by: Wei-Lin Chiang, Tim Li, Joseph E. Gonzalez, Ion Stoica, Dec 07, 2023
Welcome to our latest update on the Chatbot Arena, our open evaluation platform to test the most advanced LLMs. We're excited to share that over 130,000 votes that are now collected to rank the most capable 40+ models! In this blog post, we'll cover the results of several new models:
- Tulu-2-DPO-70B and Yi-34B-Chat are the new SoTA open models
- Mistral-based 7B models (OpenChat, OpenHermes-2.5, Starling-7B) show promising performance
We also present our findings from differentiating versions of proprietary models (e.g., GPT-4 => GPT-4-0314, GPT-4-0613), and the transition from the online Elo system to the Bradley-Terry model, which gives us significantly more stable ratings and precise confidence intervals.
Let’s dive into it!
Introducing new models
LLM has become smarter than ever and it’s been a real challenge to evaluate them properly. Traditional benchmarks such as MMLU have been useful, but they may fall short in capturing the nuance of human preference and open-ended nature of real-world conversations. We believe deploying chat models in the real-world to get feedback from users produces the most direct signals. This led to the Chatbot Arena launch in May. Since then, the open-source community has taken off. Over the past few months, we have deployed more than 45 models in Arena and we’ve collected over 130,000 valid votes from our users. We believe such a scale covers a diverse range of use cases which bring us useful insights to understand how these models work in real-world scenarios.
In November, we added record-breaking nine new models with sizes ranging from 7B to 70B, as well as proprietary ones, and gathered over new 25,000 votes for them. Excitingly, we are now seeing the gap between proprietary and open models narrowing. New models such as Tulu-2-DPO-70B and Yi-34B-Chat have been leading the open space, delivering close to gpt-3.5 performance.
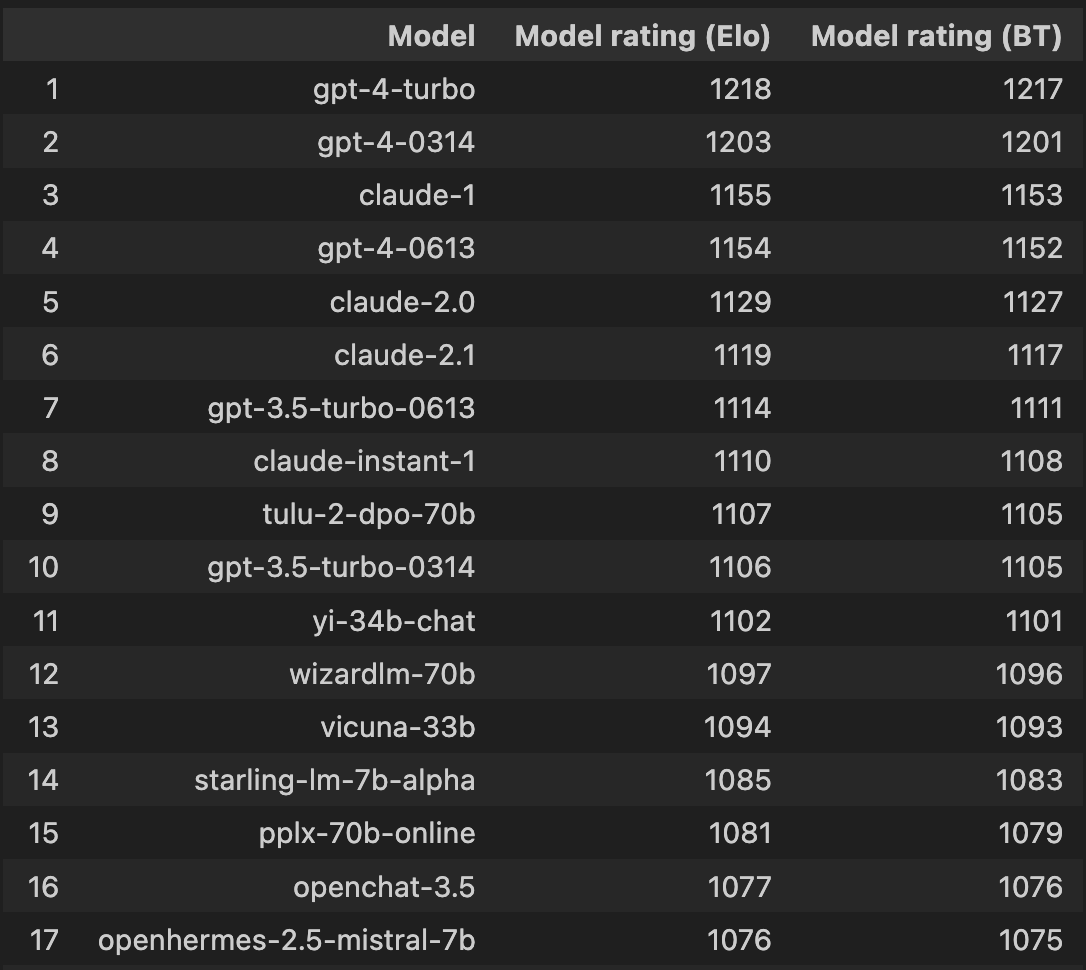
| Model | Arena Elo Rating | Vote count | License |
|---|---|---|---|
| GPT-4-Turbo | 1217 | 7007 | Proprietary |
| GPT-4-0613 | 1153 | 11944 | Proprietary |
| Claude-2.1 | 1118 | 5929 | Proprietary |
| GPT-3.5-Turbo-0613 | 1112 | 15974 | Proprietary |
| Claude-instant-1 | 1108 | 5929 | Proprietary |
| Tulu-2-DPO-70B | 1105 | 2922 | AI2 ImpACT Low-risk |
| Yi-34B-Chat | 1102 | 3123 | Yi License |
| Wizardlm-70B | 1096 | 5865 | Llama 2 Community |
| Vicuna-33B | 1093 | 11671 | Non-commercial |
| Starling-LM-7B-alpha | 1083 | 2250 | CC-BY-NC-4.0 |
| PPLX-70B-Online | 1080 | 1500 | Proprietary |
| OpenChat-3.5 | 1077 | 4662 | Apache-2.0 |
| Openhermes-2.5-mistral-7B | 1075 | 1180 | Apache-2.0 |
| Llama-2-70B-chat | 1069 | 8659 | Llama 2 Community |
| Zephyr-7B-beta | 1045 | 8412 | MIT |
| PPLX-7B-Online | 1016 | 1041 | Proprietary |
On the other hand, 7B models have also shown significant improvements. Fine-tuning the 7B Mistral model has led to Zephyr, OpenChat-3.5, Starling-lm-7b-alpha, and OpenHermes-2.5-Mistral-7b which all demonstrate impressive performance despite smaller scale. Shoutout to the open-source community pushing limits! On the other hand, to understand how freshness and grounded information help LLMs in answering user queries, we also bring Perplexity AI’s online LLMs to Arena. We have collected over 1500 votes for PPLX-70B-Online and the preliminary results show great potential. Congrats to all the teams and we look forward to seeing more models in the future!
Please find the latest leaderboard here or try Arena demo to chat with 20+ models! We also prepare a notebook to reproduce all the calculation of Elo ratings and confidence intervals.
Tracking Performance of Proprietary APIs - GPT-4-0314 vs 0613?
Since OpenAI’s GPT-4 update in June, the community has been wondering whether there's a performance change on the newer version of GPT-4. Some people find performance drop in certain domains (reference), but it’s still unclear what's really going on. Previously we combined votes of the two versions into just GPT-4. As we transition from online Elo to the BT model (explained later in the post), we decide to separate out different versions of proprietary model APIs to better satisfy its assumptions on model staying static.
Surprisingly, we observe a significant difference between gpt-4-0314 and gpt-4-0613 (Rating 1201 vs 1152) based on Arena user preference. The GPT-4 API was automatically updated from 0314 to 0613 on June 27 and the 0314 version has since then been retired from Arena. Potential hypotheses:
- Arena user distribution has shifted before/after July (e.g., prompt distribution, voting behaviors etc)
- No comparison data for 0314 against newly added models after July may be unfair.
- Arena users indeed prefer the 0314 version of GPT-4 than 0613.
To address this problem, we have brought up gpt-4-0314 online again to collect new votes, also directly comparing it against its newer 0613 version. At the time of writing we have collected 1,000 new votes for gpt-4-0314 and its performance is still robust from winrate over other models shown below. We’ll give more updates on this in the future.
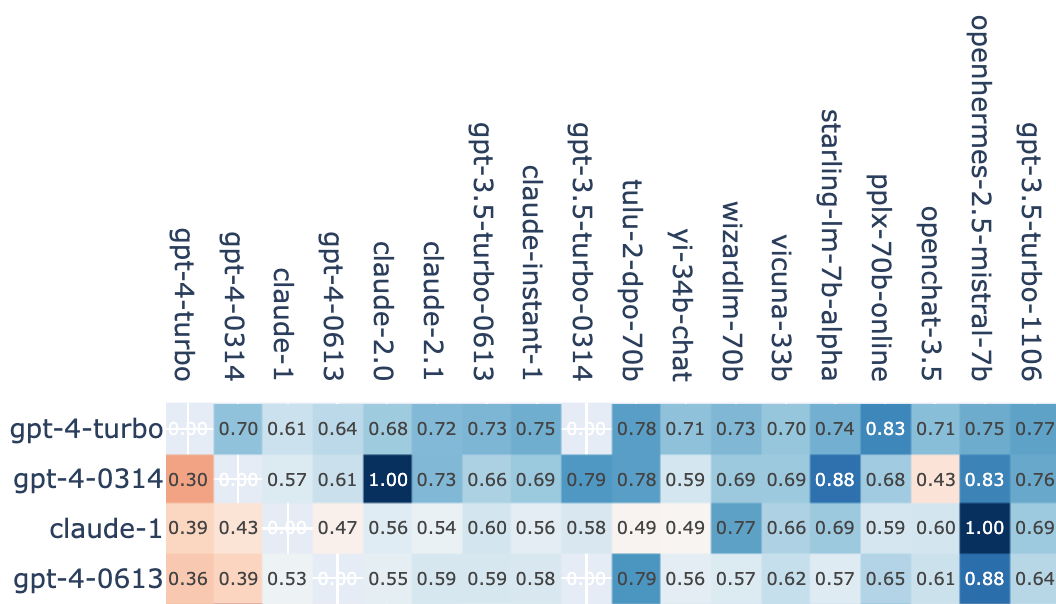
Interestingly, gpt-3.5-turbo, which has been through a similar version change (0314 -> 0613), seems to be normal. As you can see, gpt-3.5-turbo-0613 has slightly higher rating than gpt-3.5-turbo-0314 (1112 vs 1106). However, we again observe a strange performance drop of the latest version gpt-3.5-turbo-1106 which has obtained over 5,000 votes. We hope to investigate this deeper by developing new tools to analyze user prompts and identify model strengths and weaknesses in different areas.
Transition from online Elo rating system to Bradley-Terry model
We adopted the Elo rating system for ranking models since the launch of the Arena. It has been useful to transform pairwise human preference to Elo ratings that serve as a predictor of winrate between models. Specifically, if player A has a rating of $R_A$ and player B a rating of $R_B$, the probability of player A winning is

ELO rating has been used to rank chess players by the international community for over 60 years. Standard Elo rating systems assume a player’s performance changes overtime. So an online algorithm is needed to capture such dynamics, meaning recent games should weigh more than older games. Specifically, after each game, a player's rating is updated according to the difference between predicted outcome and actual outcome.

This algorithm has two distinct features:
- It can be computed asynchronously by players around the world.
- It allows for players performance to change dynamically – it does not assume a fixed unknown value for the players rating.
This ability to adapt is determined by the parameter K which controls the magnitude of rating changes that can affect the overall result. A larger K essentially put more weight on the recent games, which may make sense for new players whose performance improves quickly. However as players become more senior and their performance “converges” then a smaller value of K is more appropriate. As a result, USCF adopted K based on the number of games and tournaments completed by the player (reference). That is, the Elo rating of a senior player changes slower than a new player.
When we launched the Arena, we noticed considerable variability in the ratings using the classic online algorithm. We tried to tune the K to be sufficiently stable while also allowing new models to move up quickly in the leaderboard. We ultimately decided to adopt a bootstrap-like technique to shuffle the data and sample Elo scores from 1000 permutations of the online plays. You can find the details in this notebook. This provided consistent stable scores and allowed us to incorporate new models quickly. This is also observed in a recent work by Cohere. However, we used the same samples to estimate confidence intervals which were therefore too wide (effectively CI’s for the original online Elo estimates).
In the context of LLM ranking, there are two important differences from the classic Elo chess ranking system. First, we have access to the entire history of all games for all models and so we don’t need a decentralized algorithm. Second, most models are static (we have access to the weights) and so we don’t expect their performance to change. However, it is worth noting that the hosted proprietary models may not be static and their behavior can change without notice. We try our best to pin specific model API versions if possible.
To improve the quality of our rankings and their confidence estimates, we are adopting another widely used rating system called the Bradley–Terry (BT) model. This model actually is the maximum likelihood (MLE) estimate of the underlying Elo model assuming a fixed but unknown pairwise win-rate. Similar to Elo rating, BT model is also based on pairwise comparison to derive ratings of players to estimate win rate between each other. The core difference between BT model vs the online Elo system is the assumption that player's performance does not change (i.e., game order does not matter) and the computation takes place in a centralized fashion.
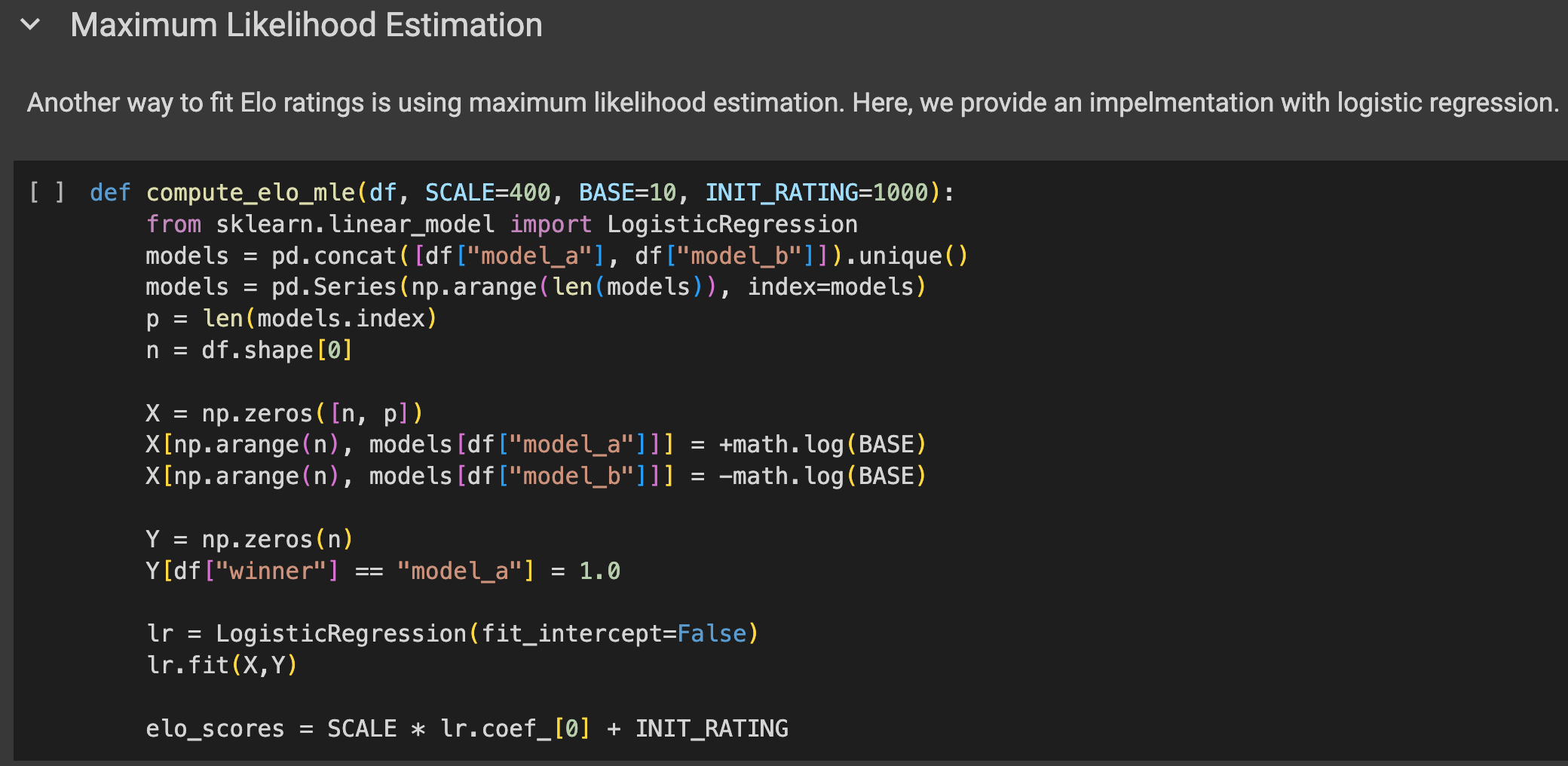
With the static performance assumption, the model ratings can be obtained by maximum likelihood estimation (MLE), i.e. maximizing the likelihood of the observed game outcomes given the model ratings. Code snippet below shows how to use MLE to compute the model ratings.
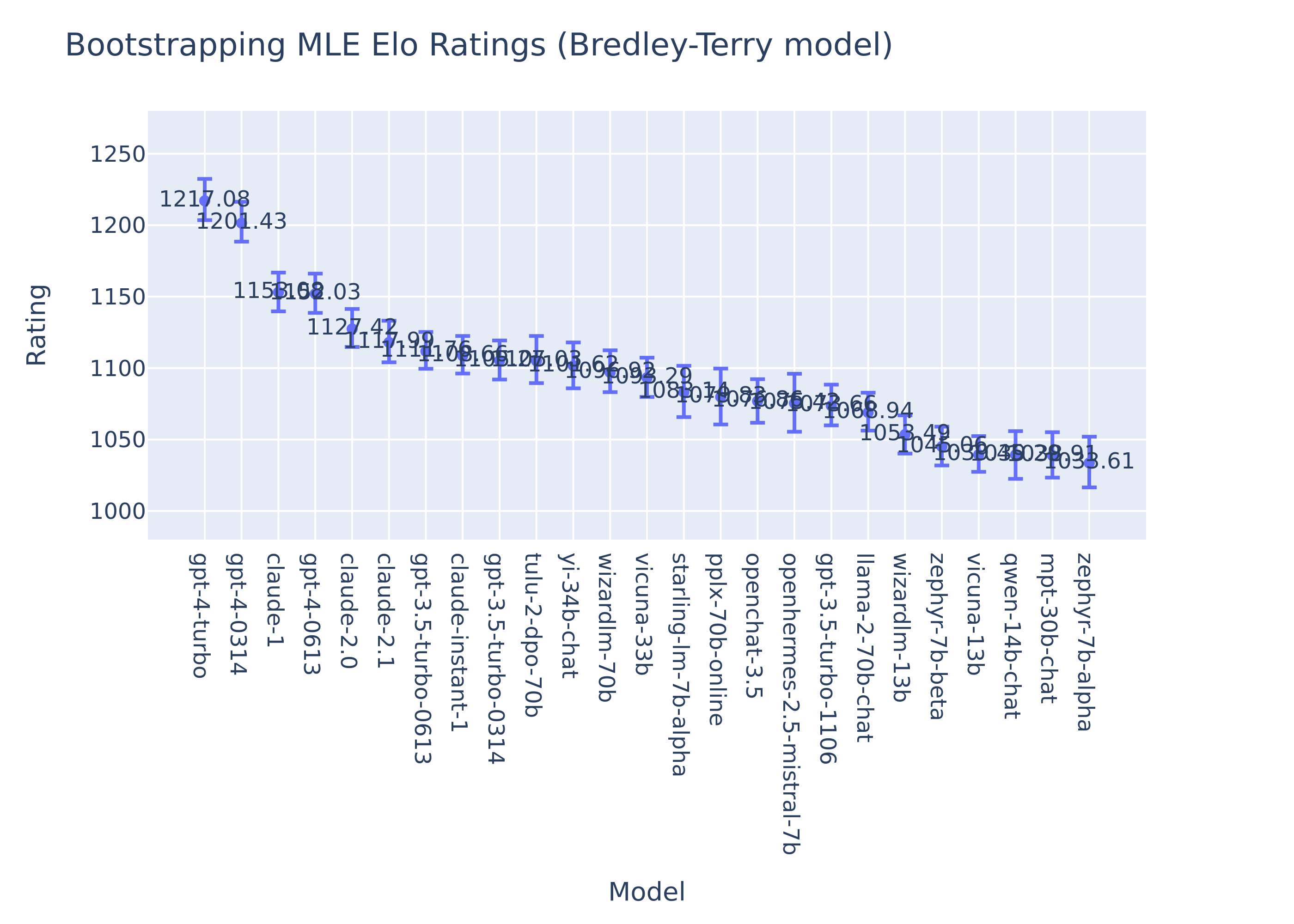
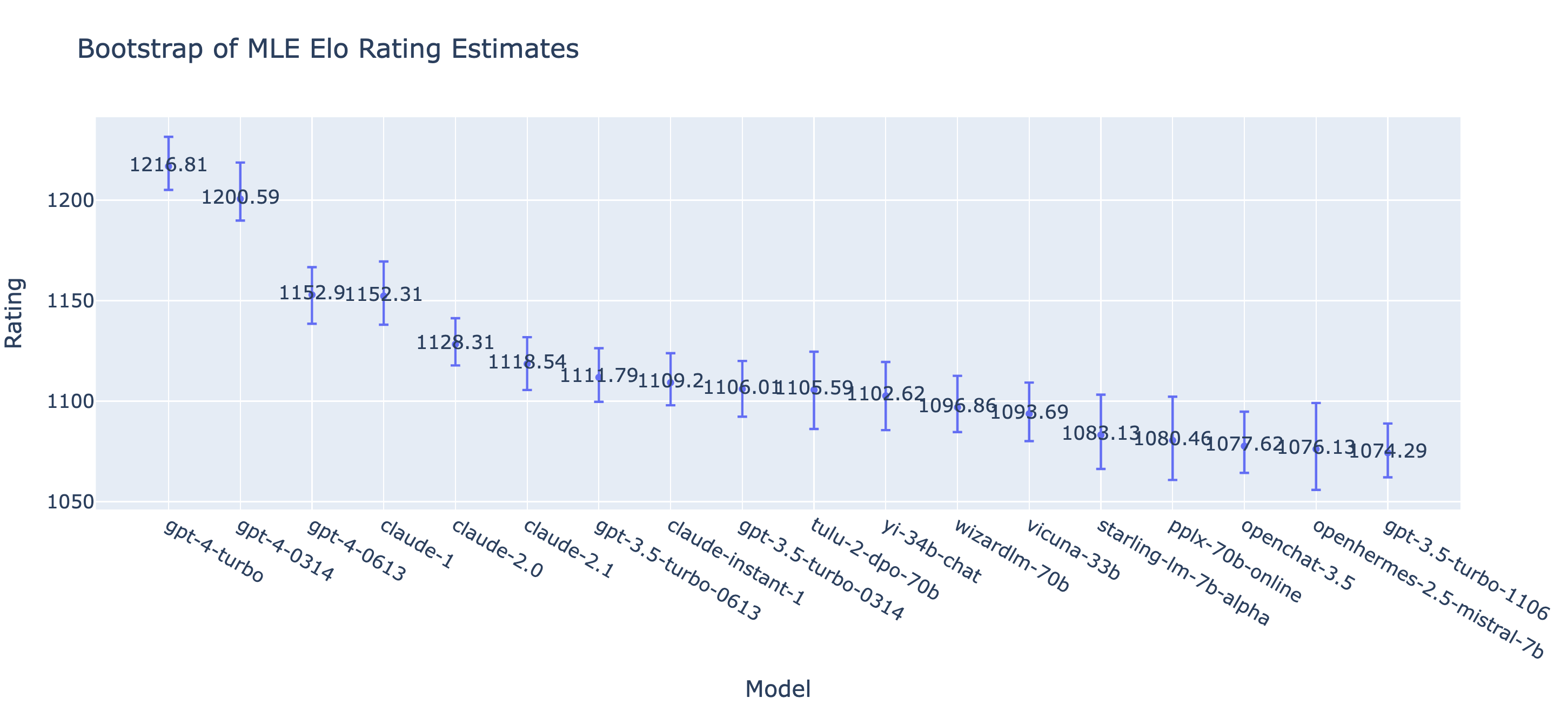
Similarly, we can also bootstrap the MLE Bradley-Terry scores to obtain the confidence intervals of model ratings. We observe that the mean rating by both methods are very similar and the rankings are almost the same.
More importantly, with the BT model, the bootstrap confidence intervals now better capture the variance of the model performance estimates. We observe clear improvement in the below figures. Newly added models with fewer votes have a wider range of confidence intervals than others.
| Bootstraping Online Elo | Bootstraping MLE Elo (BT model) |
|---|---|
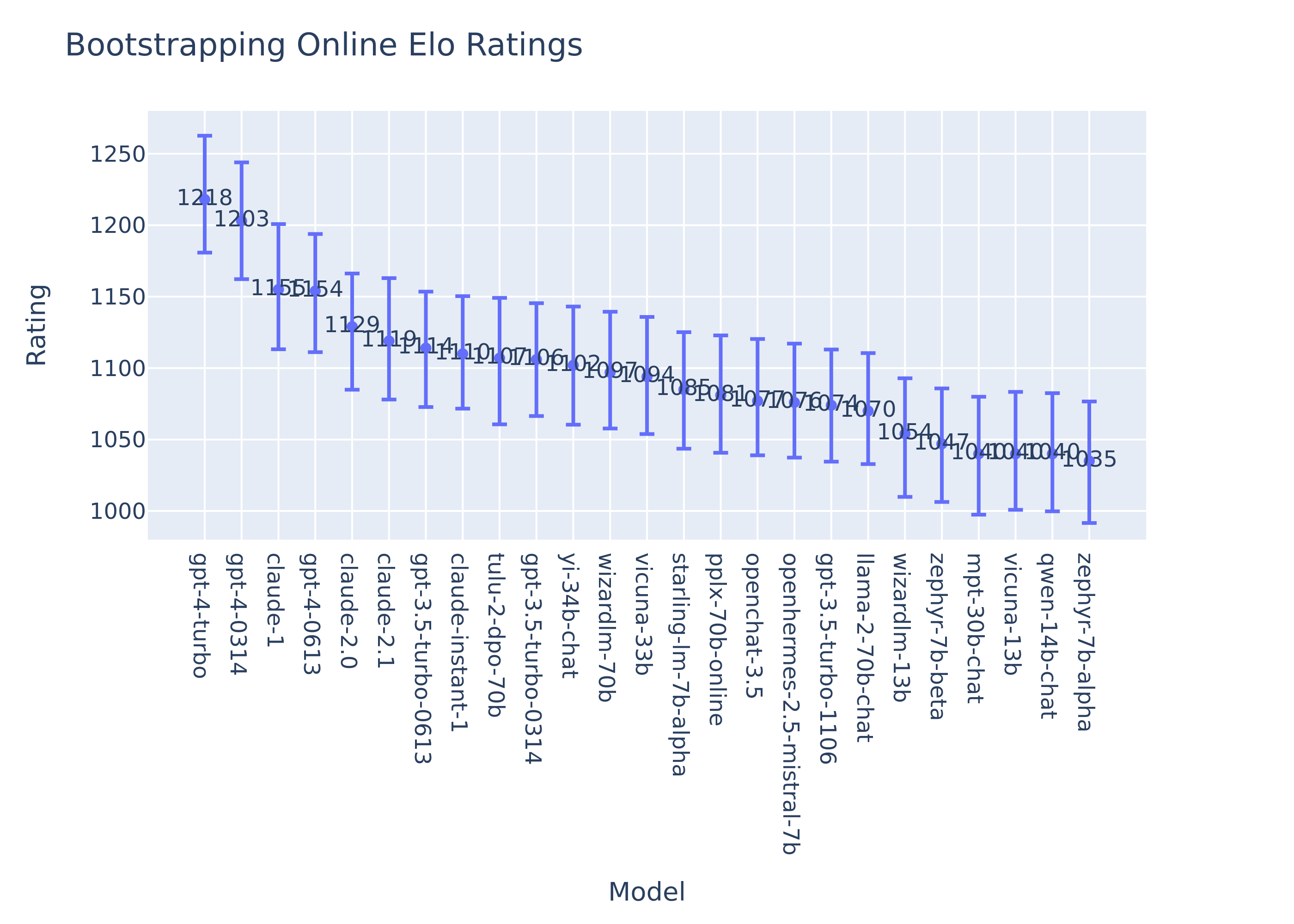 |
|
Note that we extend BT model to consider ties by counting a tie as half a win and half a loss. Code to reproduce the calculation can be found at this notebook.
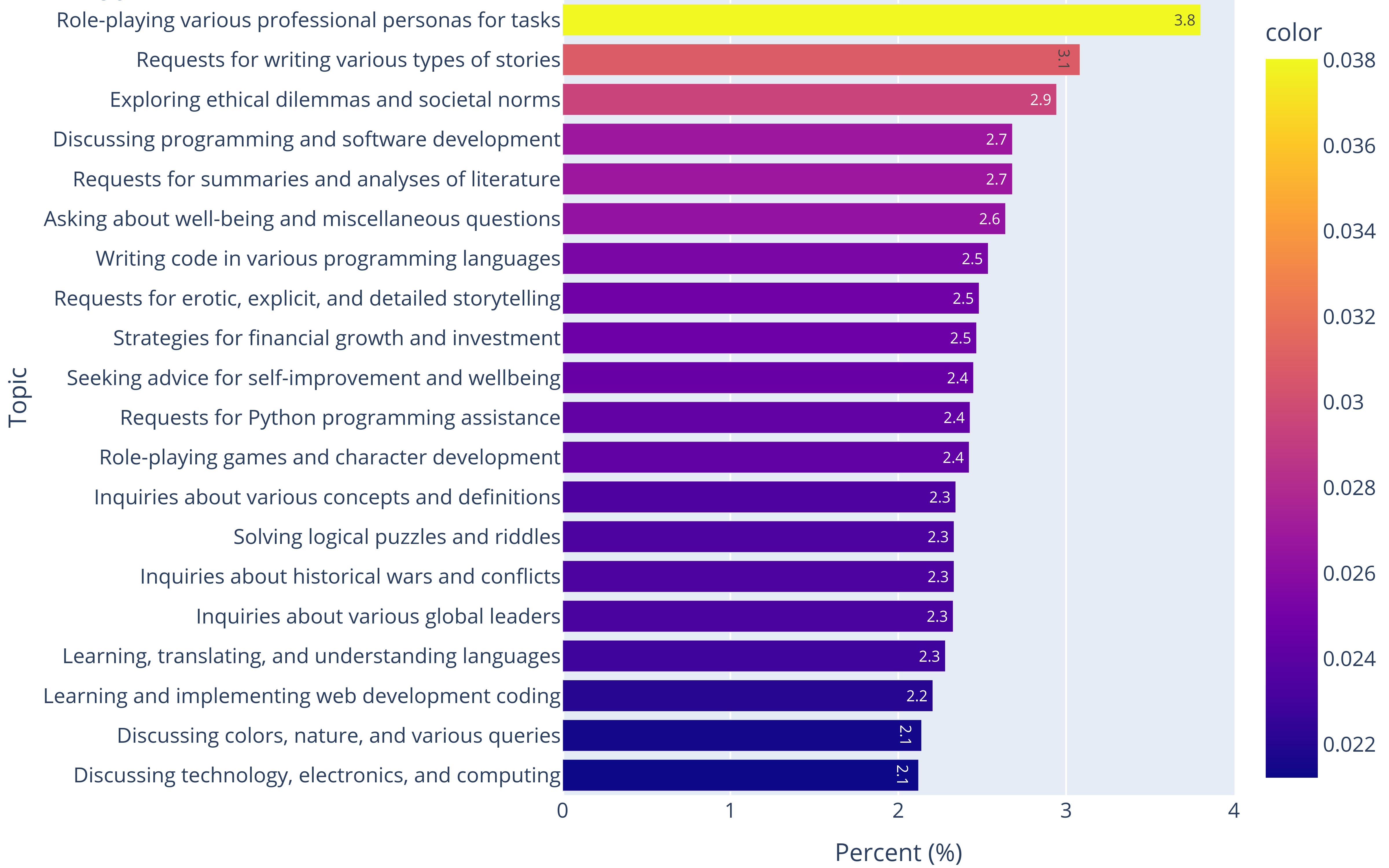
Bonus: Topic modeling on user prompts
We've also conducted topic modeling on 50,000 user prompts to better understand how users interact with these models. Our approach utilized OpenAI embeddings text-embedding-ada-002 and K-means clustering, followed by GPT-4 to summarize the topics for each cluster, provided with the prompts close to the center. This analysis revealed a wide range of topics, from role-playing, story writing to programming advice. We show the topic distribution and a few examples below.
| Cluster ID | Arena User Prompt |
|---|---|
| 1 | You are a Chief information Officer for a Biotechnology Manufacturing company and will act like one. Write a business need and objectives for a case study to Engage Info-Tech technical consulting services to conduct a comprehensive assessment of our current application development practices, including analyzing our development methodologies, tools, and frameworks. |
| 2 | Write a short scene from a novel where a beautiful, wicked lamia coils around an unfortunate, quippy human adventurer. |
| 3 | How should the balance be struck between freedom of speech and the ability to function in a world without continual distractions and distortions from misinformation? |
| 4 | Can you give me a list of 5 suggestions on how to write software with fewer bugs? |
Moving forward, we aim to refine our methods to filter out low-quality prompts and improve categorization for a clearer understanding of model strengths and weaknesses in different areas.
Next steps
We plan to ship real-time leaderboard update, diving deeper into user prompt analysis, and enhancing prompt moderation and categorization. Stay tuned for more insights as we continue to refine our approach to evaluating the evolving landscape of LLMs. Thanks for supporting us on this journey, and we look forward to sharing more updates soon!
Links
- Chatbot Arena Demo
- Arena Elo Colab
- How Is ChatGPT's Behavior Changing over Time?
- Bradley-Terry model lecture note, paper
- Elo Uncovered: Robustness and Best Practices in Language Model Evaluation
If you wish to see more models on Arena leaderboard, we invite you to contribute to FastChat or contact us to provide us with API access.