Fast JSON Decoding for Local LLMs with Compressed Finite State Machine
by: Liangsheng Yin, Ying Sheng, Lianmin Zheng, Feb 05, 2024
Constraining an LLM to consistently generate valid JSON or YAML that adheres to a specific schema is a critical feature for many applications. In this blog post, we introduce an optimization that significantly accelerates this type of constrained decoding. Our approach utilizes a compressed finite state machine and is compatible with any regular expression, thereby accommodating any JSON or YAML schema. Distinct from existing systems that decode one token at one step, our method analyzes the finite state machine of a regular expression, compresses singular transition paths, and decodes multiple tokens in a single step whenever feasible. In comparison to state-of-the-art systems (guidance + llama.cpp, outlines + vLLM), our method can reduce the latency by up to 2x and boost throughput by up to 2.5x. This optimization also makes constrained decoding even faster than normal decoding. You can try it now on SGLang.
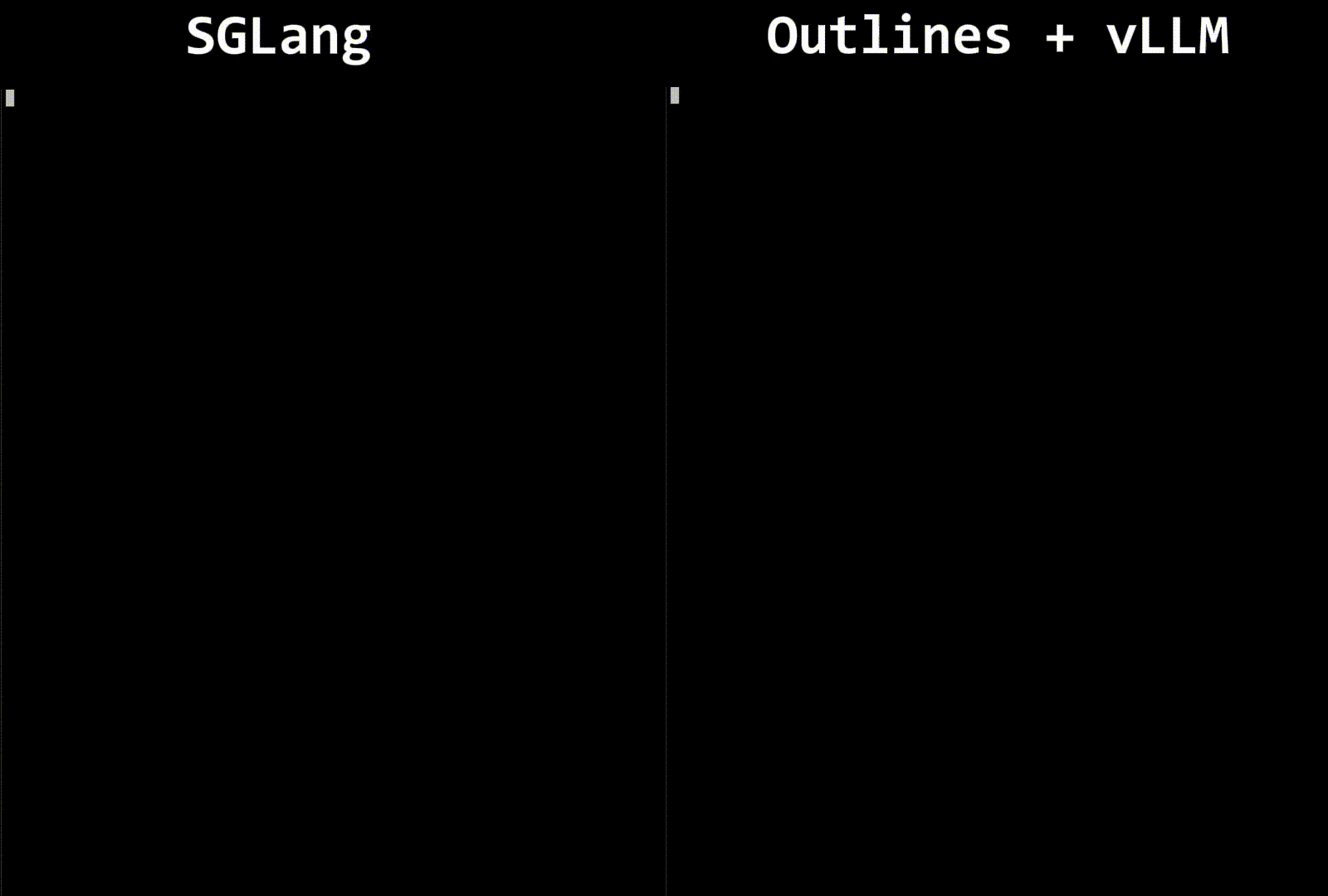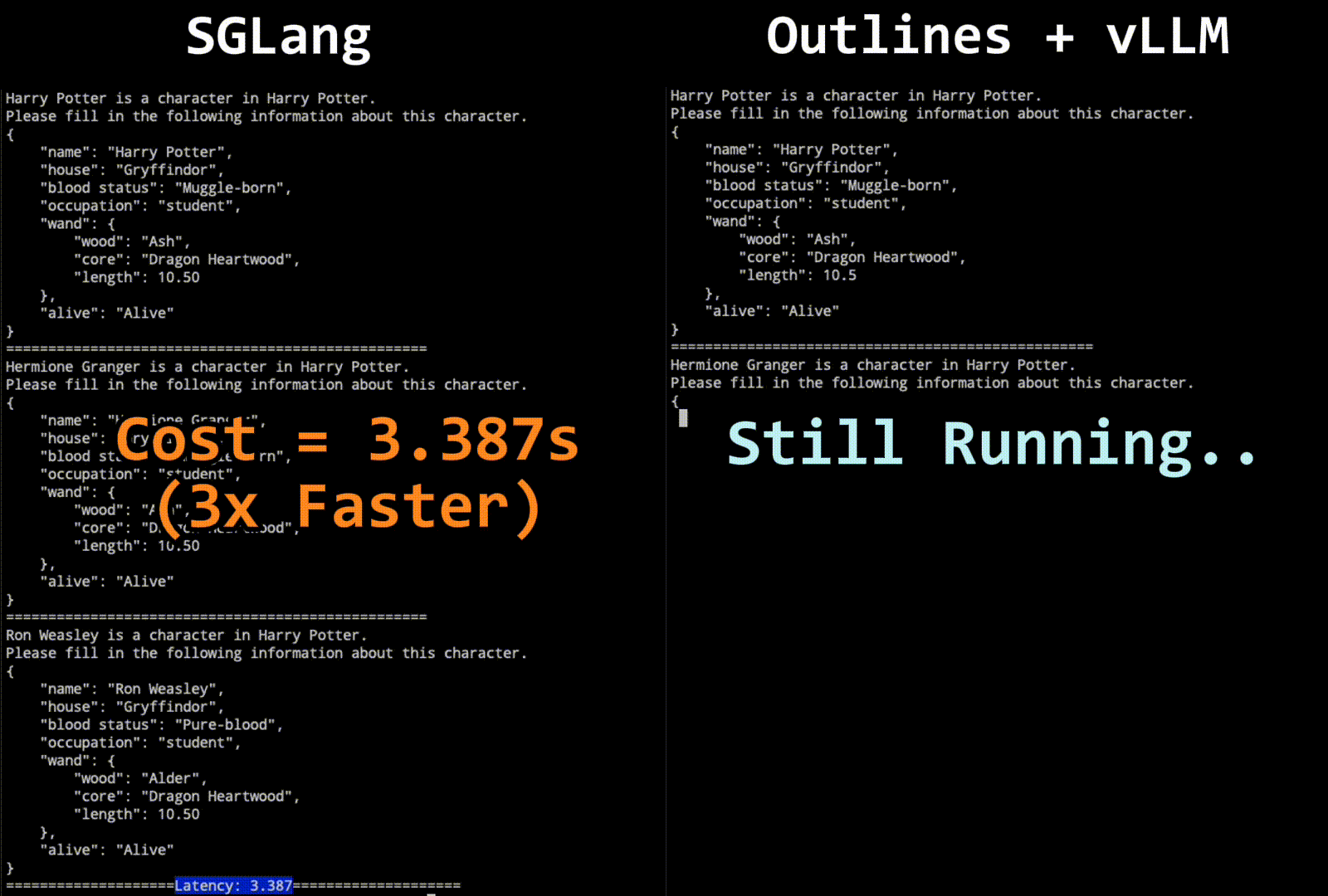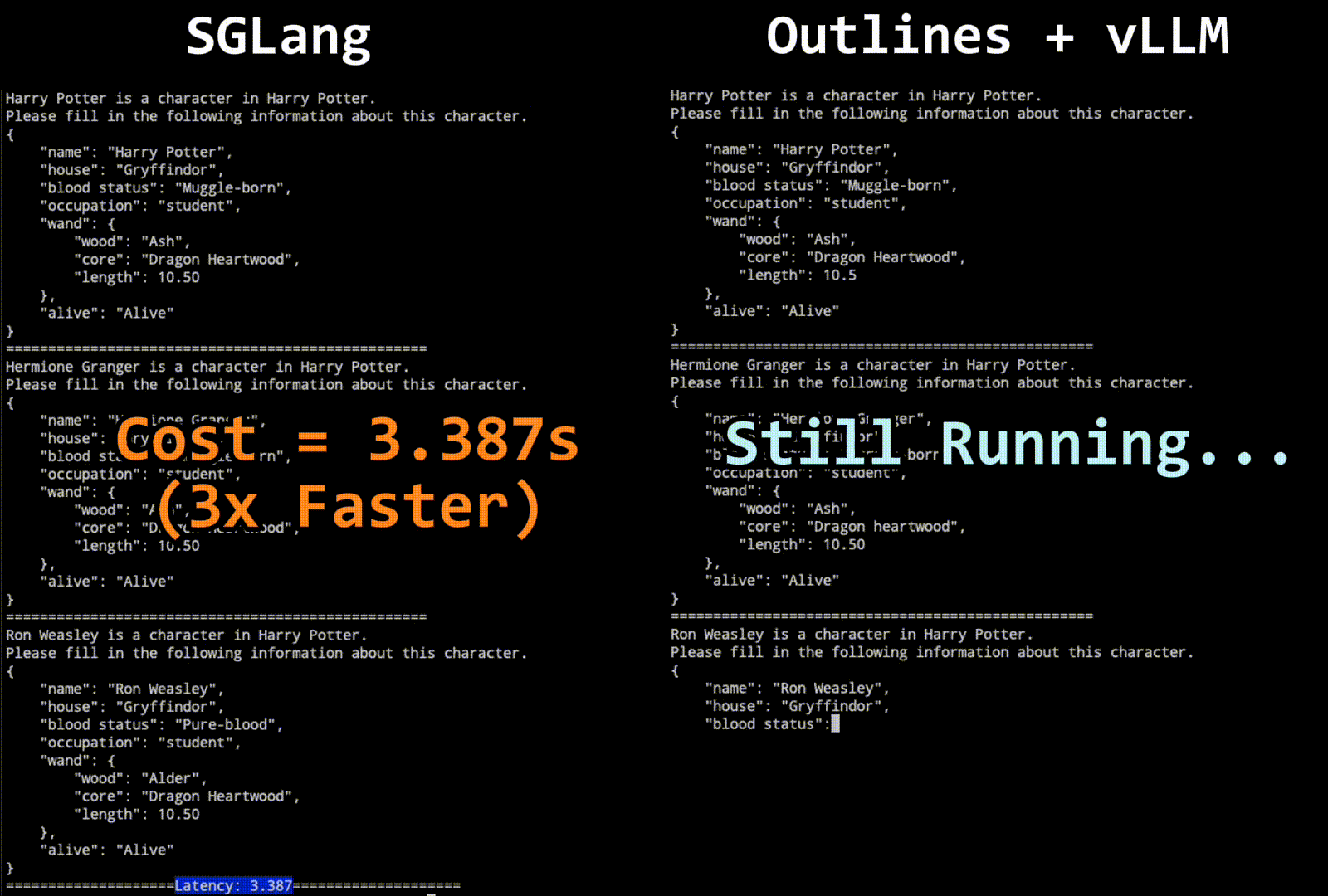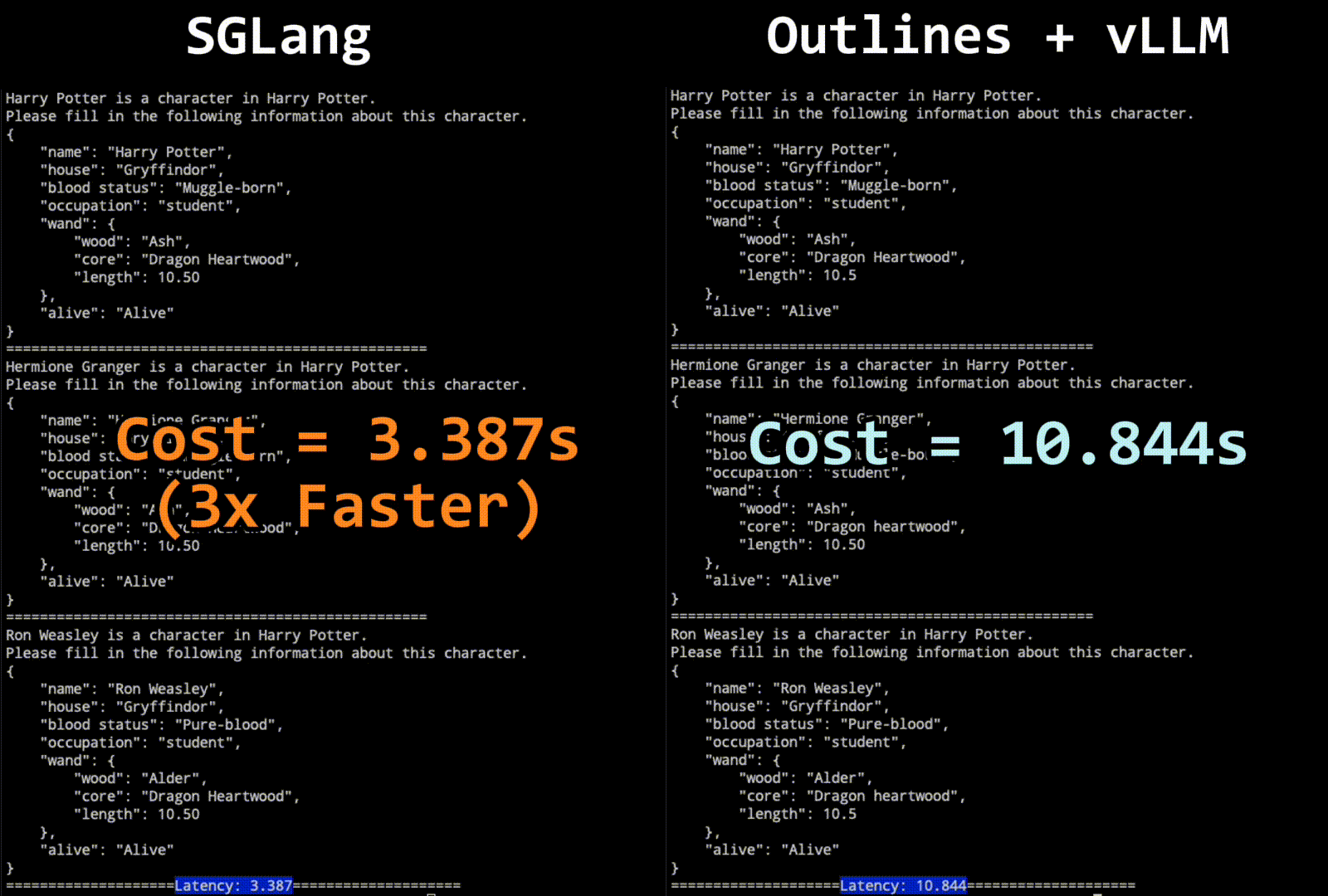
Figure 1: Comparison of SGLang and Outlines + vLLM in JSON Decoding
Background
JSON is one of the most important formats for data interchange. Requiring LLMs to always generate valid JSON can render the output of the LLM easily parsable in a structured manner. Recognizing its significance, OpenAI introduced the JSON mode, which constrains the model to always return a valid JSON object. However, more fine-grained control is often needed to ensure that the generated JSON object adheres to a specific schema, such as
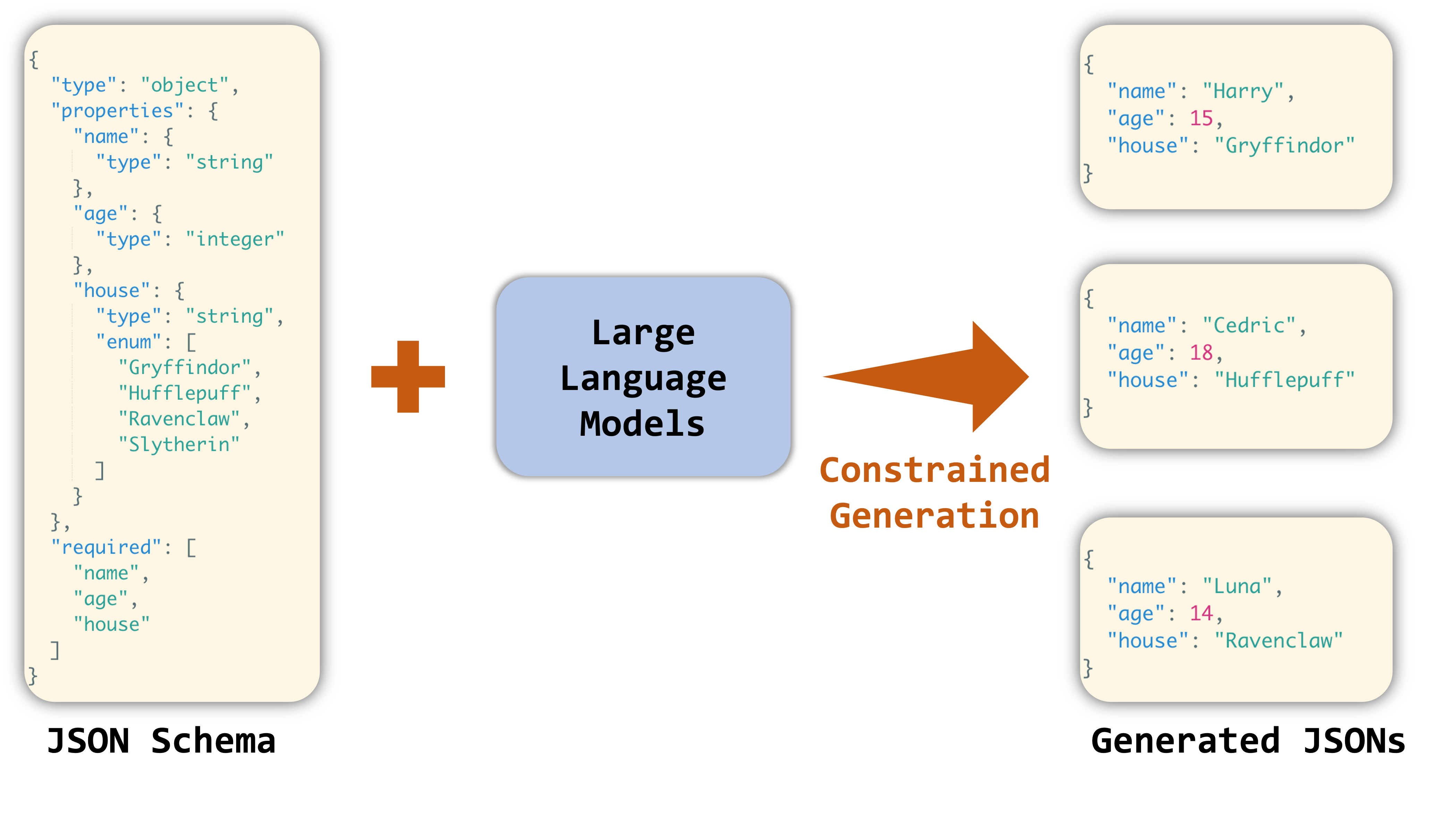
Figure 2: Example of Constrained Generation Following a JSON Schema
For local LLMs, there are two major methods to guide the model to generate JSON objects that follow a specific schema.
Method 1: Finite State Machine Based
This method involves transforming the JSON schema into a regular expression. We can then construct a Finite State Machine(FSM) based on the regular expression. The FSM is used to guide the LLM generation. For every state within the FSM, we can calculate the permissible transitions and identify the acceptable next tokens. This allows us to track the current state during decoding and filter out invalid tokens by applying logit bias to the output. You can learn more about this method in the outlines paper.
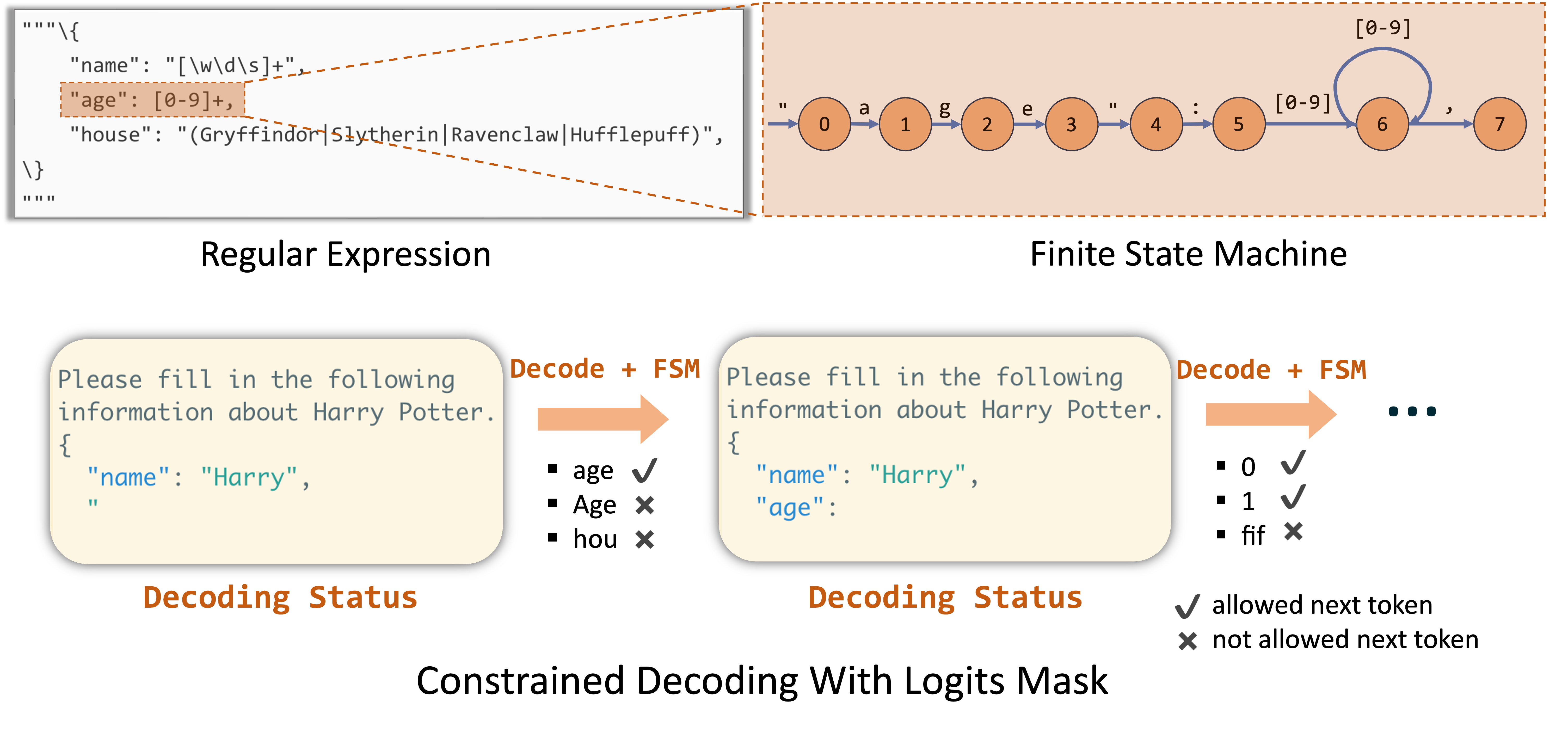
Figure 3: Constrained Decoding based on FSM and Logits Masking. In the first constrained decoding pass, only
age is allowed. In the second pass, as the regex requires digits, both 0 and 1 are allowed, but the LLM would sample 1 with a higher probability.
The FSM-based method utilizes generalized regular expressions to define the low-level rules, which can be applied to a wide range of grammars, such as JSON schema, IP addresses, and emails.
Limitations:
Since the FSM is constructed at the token level, it can transition the state by only one token at each step. Consequently, it can decode only one token at a time, which results in slow decoding.
Method 2: Interleaved-Based
Aside from converting the entire JSON schema into a regular expression, another approach is to employ interleaved-based decoding. In this method, a given JSON schema can be broken down into several parts, each containing either a chunked prefill part or a constrained decoding part. These different parts are executed interleavedly by the inference system. Because the chunked prefill can process multiple tokens in a single forward pass, it is faster than token-by-token decoding.
Guidance provides a set of syntax rules for interleaved-based decoding, using llama.cpp as a backend.
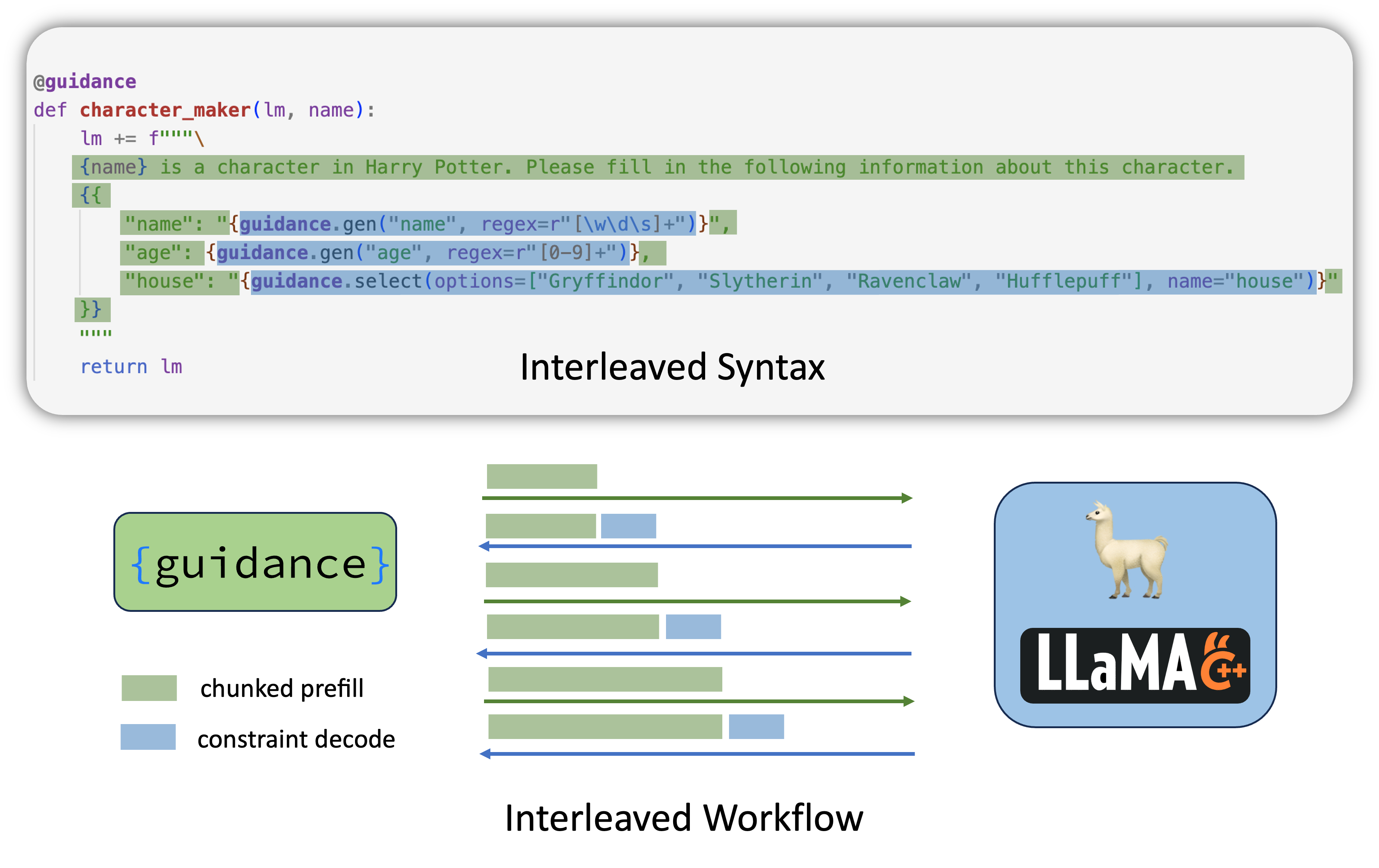
Figure 4: Interleaved JSON Decoding in Guidance
Limitations:
- The interleaved-based method requires custom syntax, making it less versatile and expressive than individual regular expressions.
- It struggles with correctly handling tokenization boundaries due to potential conflicts between the decode and chunked prefill segments.
- Frequent communication between the interpreter and the backend brings additional overhead.
Our Method: Jump-Forward Decoding With a Compressed Finite State Machine
We can combine the advantages of FSM-based and interleaved-based methods by introducing a new decoding algorithm, jump-forward decoding, based on the compressed finite state machine.
During the decoding process guided by the regex converted from the JSON schema, we can predict forthcoming strings when we reach specific junctures:
- In figure3, at the beginning of decoding, according to the regex, we can anticipate the incoming string to be:
{ "name": - Similarly, when the LLM outputs a
Gwhile filling in the house attribute of a character, we can confidently predict that the next string will beryffindor, thereby completing the full string asGryffindor.
That is precisely how the jump-forward decoding algorithm makes decoding faster. In the jump-forward algorithm, we examine the finite state machine of the given regular expression, identify all the singular transition edges, and compress consecutive ones together into singular paths. Instead of decoding the singular paths token by token, we can directly prefill (extend) them, jumping forward until the next branching point.
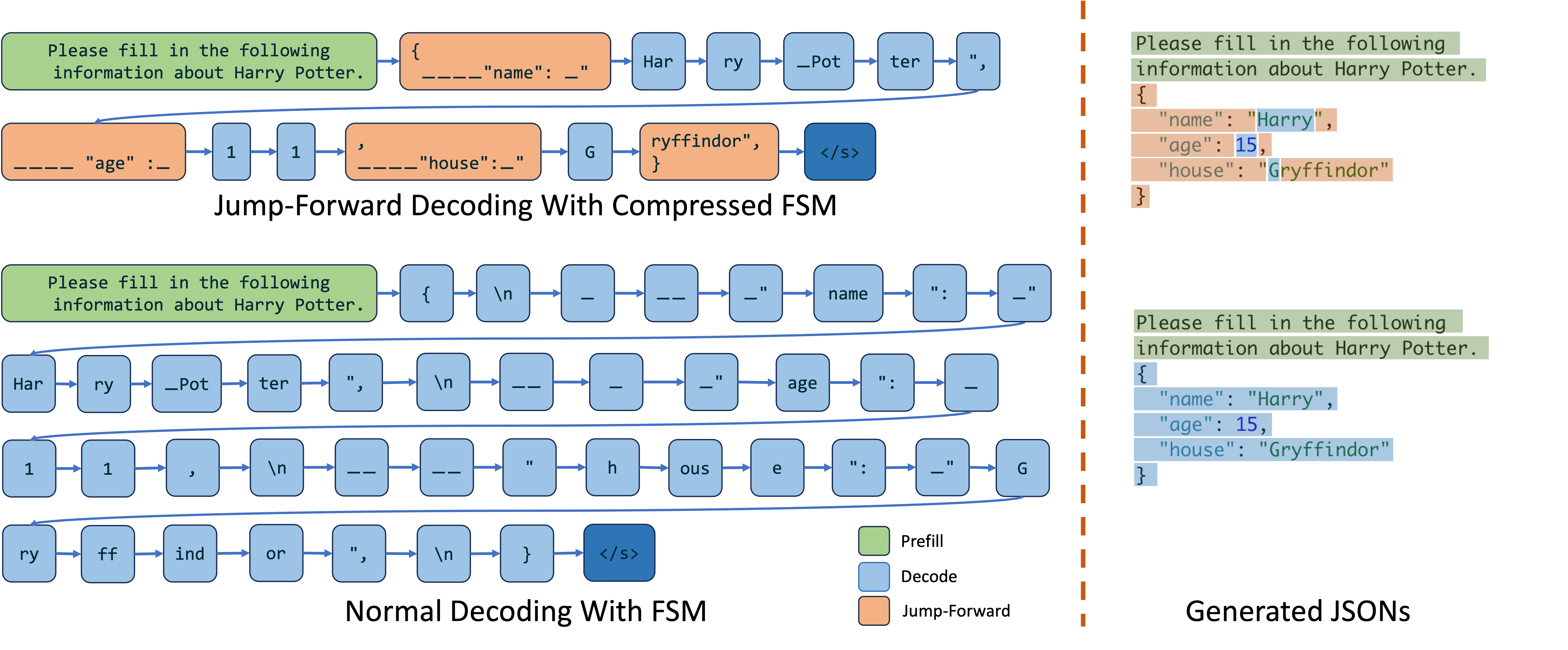
Figure 5: Comparison of Jump-Forward Decoding with Compressed FSM and Normal Decoding
The RadixAttention mechanism of SGLang greatly simplifies the implementation of the jump-forward decoding algorithm. When executing a jump-forward, we can simply terminate the current request and enqueue a new one. The RadixAttention and efficient extend primitive in the SGLang runtime will automatically reuse the KV cache of the previous tokens, thereby avoiding redundant computation.
Tokenization Boundary Handling
When implementing constrained decoding, it is always tricky to deal with the tokenization boundary, due to the complicated possible mapping between characters and tokens.
During LLM decoding, it might prefer (means with higher probability) to combine multiple characters into a single token.
For instance, when decoding
"Hello"
in the context of JSON decoding, LLMs may output tokens like this:
"
He
llo
",
Instead of decoding the last
"
, it always prefers to combine it with a following
,
to form a more frequent token
",
. This effect may cause some strange behaviors. For example, in the above case, if the regex is set to
"[\w\d\s]*"
(without the last
,
), it can lead to endless decoding because an LLM wants to stop with ", but this token is not allowed.
Moreover, during jump-forward decoding, we've found that different tokenization strategies to the jump-forwarded part may lead to different logit distributions for the subsequent tokens. Simply appending the tokenized jump-forwarded section to the current token sequence might yield unexpected outcomes.
To manage these issues, we propose the following solutions:
- We have implemented a re-tokenization mechanism during the jump-forward phase. This involves appending the string instead of the tokens, followed by a re-tokenization of the entire text. This method effectively resolves most tokenization issues and results in only a minor increase in computational overhead, approximately 4%.
- Prefer the use of a comprehensive regular expression to guide the entire decoding process, rather than employing multiple concatenated regular expressions. This approach ensures that both FSM and LLM are cognizant of the entire decoding process, thereby minimizing boundary-related issues as much as possible.
You can also read some additional discussion in this blog post.
Benchmark Results
We benchmarked our jump-forward decoding on two tasks:
- Crafting a character's data in JSON format, guided by a brief prompt.
- Extracting a city's information from a long document and outputing it in JSON format.
We tested llama-7B on an NVIDIA A10 GPU (24GB), and used vllm v0.2.7, guidance v0.1.0, outlines v0.2.5 and llama.cpp v0.2.38(Python binding) . The figure below shows the throughput (using the maximum batch size supported by each system) and latency (with a batch size of 1) of these methods:
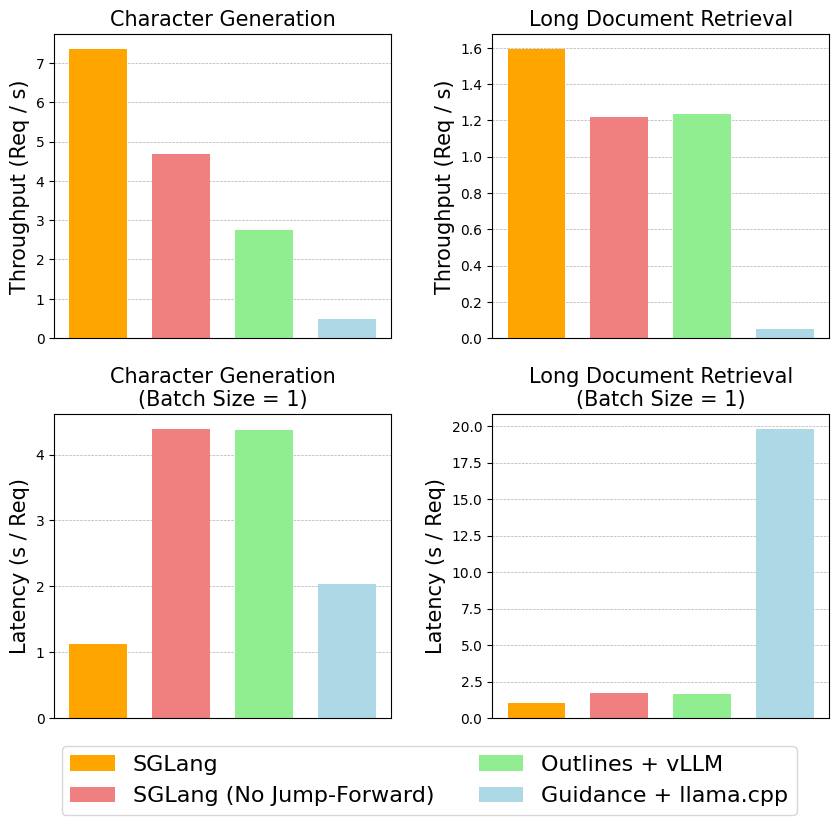
Figure 6: Benchmark Results
The results show that SGLang with our decoding algorithm significantly outperforms all other systems. It can reduce the latency by up to 2x and boost throughput by up to 2.5x. In the character generation task, even SGLang without Jump-Forward achieves higher throughput than Outlines+vLLM; we suspect this is due to some overhead in Outlines.
Use Cases
We have been testing this feature with Boson.ai for two weeks, who are bringing this feature into their production use cases because it guarantees robust response with higher decoding throughput.
Additionally, another user used this feature to extract structured information from images by utilizing the vision language model, LLaVA.

Figure 7: Extracting structured information from an image using SGLang and LLaVA