RouteLLM: An Open-Source Framework for Cost-Effective LLM Routing
LLMs have demonstrated remarkable capabilities across a range of tasks, but there exists wide variation in their costs and capabilities, as seen from the plot of performance against cost in Figure 1. Very broadly, more capable models tend to be more expensive than less capable models. This leads to a dilemma when deploying LLMs in the real-world - routing all queries to the largest, most capable model leads to the highest-quality responses but can be expensive, while routing queries to smaller models can save costs but may result in lower-quality responses.
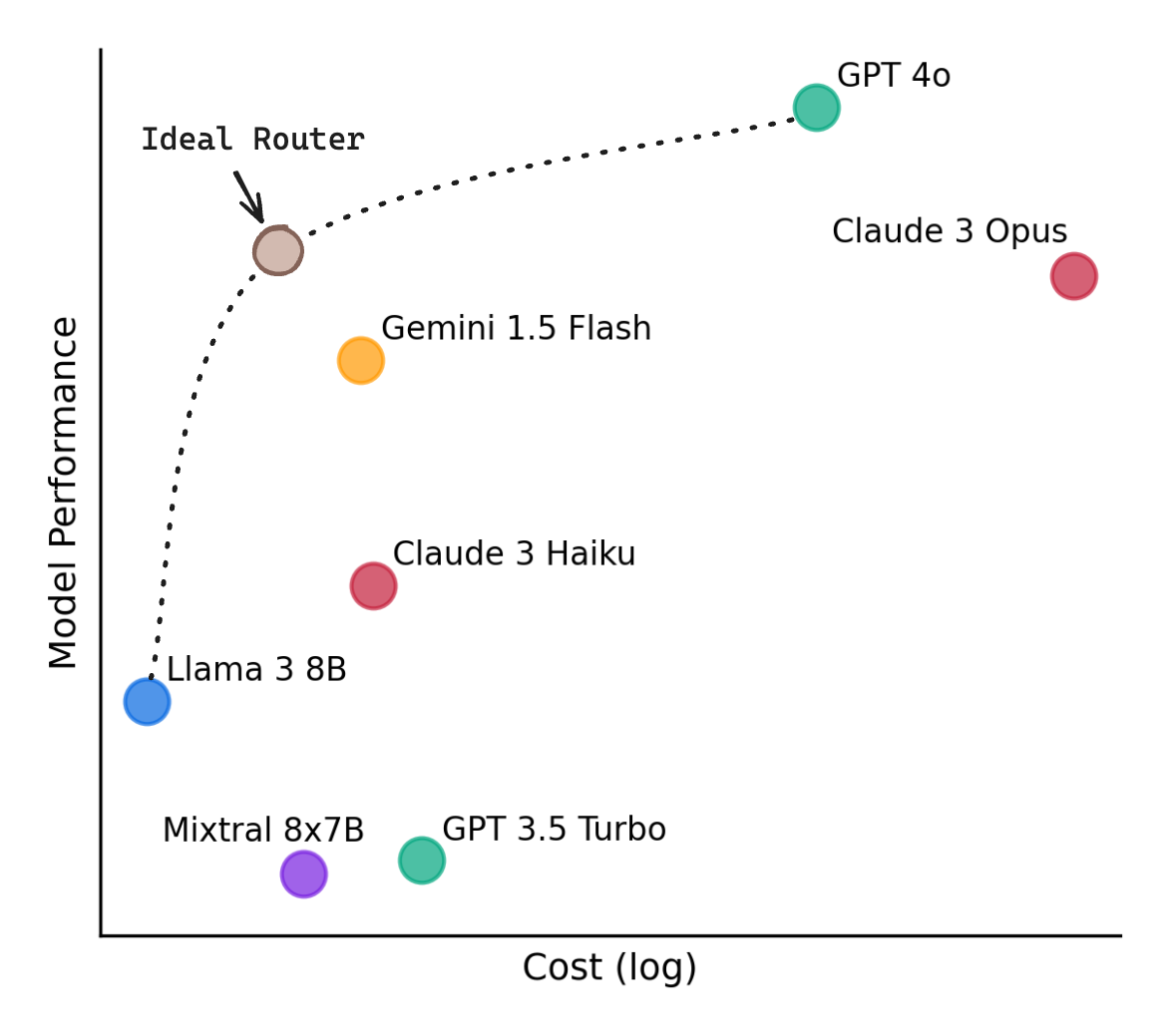
Figure 1: Plot of performance against cost of various LLMs. Performance is measured by Elo on Chatbot Arena, and cost per million tokens assuming a 1:1 input / output ratio. Through routing between two models, we ideally achieve a better performance:cost ratio than can be achieved with either model.
LLM routing offers a solution to this, where each query is first processed by a system that decides which LLM to route it to. Ideally, all queries that can be handled by weaker models should be routed to these models, with all other queries routed to stronger models, minimizing cost while maintaining response quality. However, this turns out to be a challenging problem because the routing system has to infer both the characteristics of an incoming query and different models’ capabilities when routing.
To tackle this, we present RouteLLM, a principled framework for LLM routing based on preference data. We formalize the problem of LLM routing and explore augmentation techniques to improve router performance. We trained four different routers using public data from Chatbot Arena and demonstrate that they can significantly reduce costs without compromising quality, with cost reductions of over 85% on MT Bench, 45% on MMLU, and 35% on GSM8K as compared to using only GPT-4, while still achieving 95% of GPT-4’s performance. We also publicly release all our code and datasets, including a new open-source framework for serving and evaluating LLM routers.
Routing Setup
In our routing setup, we focus on the case where there are two models: a stronger, more expensive model, and a weaker but cheaper model. Given this setup, our objective is to minimize costs while achieving high quality by routing between both models.
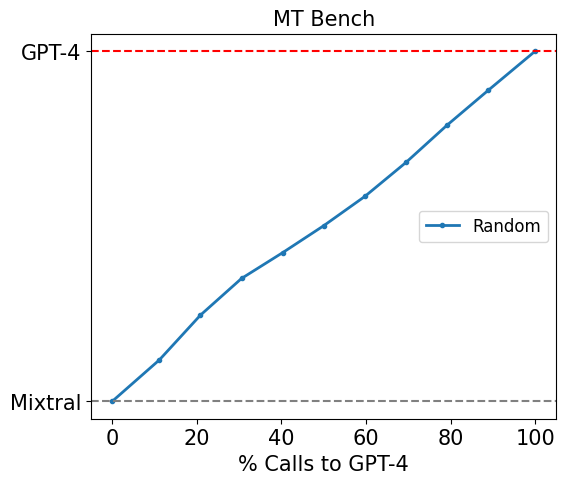
Figure 2: Random router performance on MT Bench
This is best understood through Figure 2, which represents the performance of a router that randomly routes between the two models on MT Bench. Specifically, we route between GPT-4 and Mixtral 8x7B here, with their performance denoted by the red and grey dotted lines respectively. For any router, we can plot a similar graph of its performance against the number of the calls made to GPT-4 (which is representative of the cost incurred since the cost of a Mixtral call is negligible).
We use preference data for training our routers, building upon previous works (1,2). Each data point consists of a prompt and a comparison between the response quality of two models on that prompt i.e. this could be a win for the first model, a win for the second model, or a tie. Using preference data allows us to learn about the strengths and weaknesses of different models and how they relate to queries, which is effective for training routers. For our base dataset, we utilize public data from Chatbot Arena. We also investigate data augmentation techniques to further improve performance using both golden-label datasets and a LLM judge.
We trained four routers using a mix of Chatbot Arena data and data augmentation:
- A similarity-weighted (SW) ranking router that performs a “weighted Elo calculation” based on similarity
- A matrix factorization model that learns a scoring function for how well a model can answer a prompt
- A BERT classifier that predicts which model can provide a better response
- A causal LLM classifier that also predicts which model can provide a better response
Results
We evaluated these routers on three popular benchmarks: MT Bench, MMLU, and GSM8K, presenting results for MT Bench and MMLU below. For evaluation, we route between GPT-4 Turbo as our strong model and Mixtral 8x7B as our weak model. We use the random router from before as our baseline.
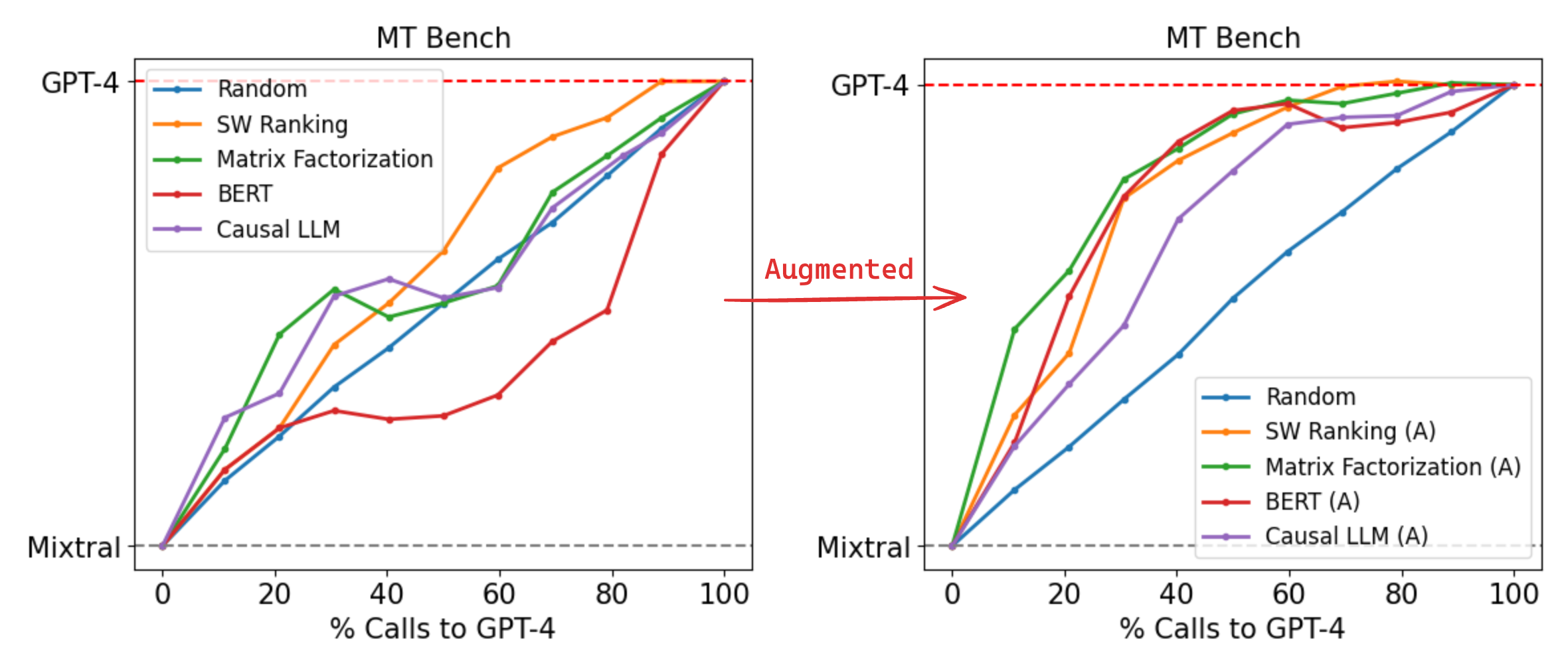
Figure 3: Router performance on MT Bench (left) trained only on Arena data (right) trained on Arena data augmented using a LLM judge.
Figure 3 displays the performance of our routers on MT Bench. For routers trained only on the Arena dataset, we observe strong performance for both matrix factorization and SW ranking. Notably, matrix factorization is able to achieve 95% of GPT-4 performance using 26% GPT-4 calls, which is approximately 48% cheaper as compared to the random baseline.
Augmenting the Arena data using an LLM judge leads to significant improvements across all routers. When trained on this augmented dataset, matrix factorization is again the best-performing router, with the number of GPT-4 calls required to achieve 95% GPT-4 performance further halved at 14% of total calls, 75% cheaper than the random baseline.
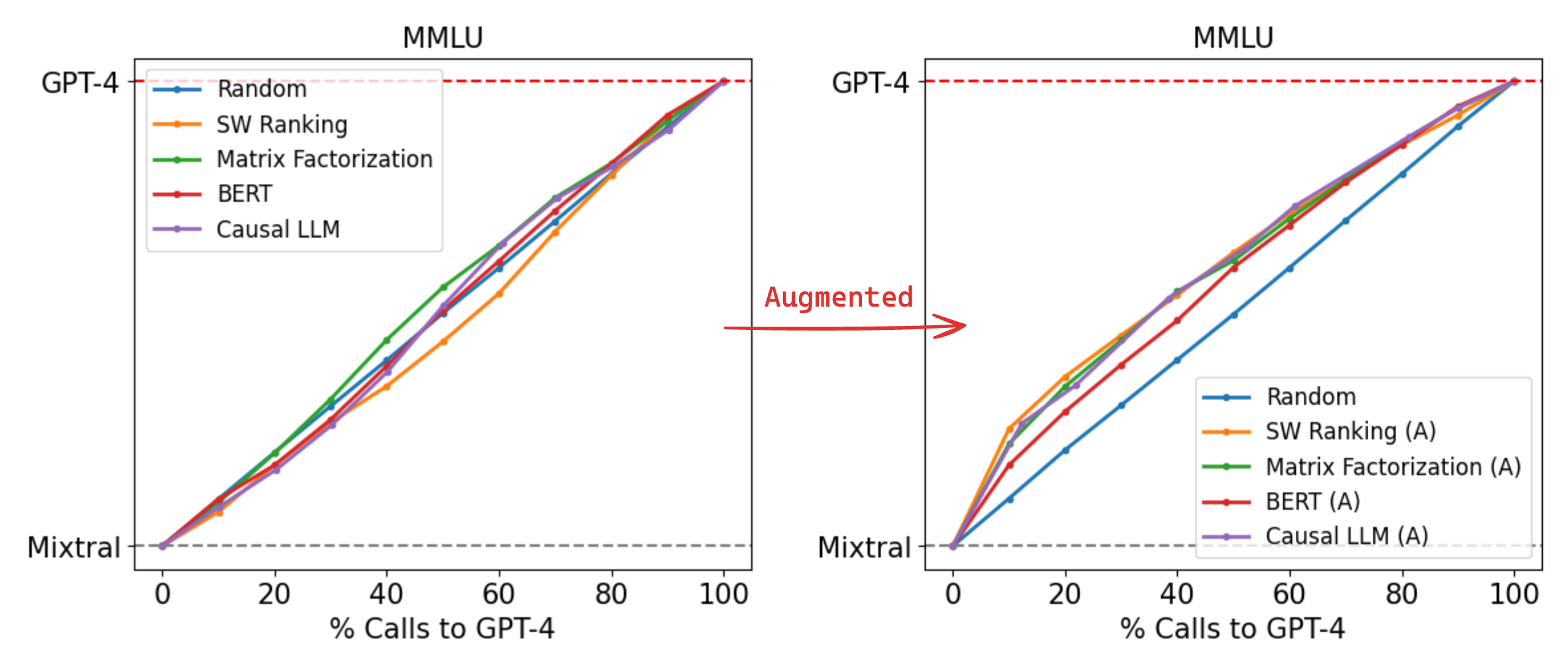
Figure 4: Router performance on MMLU (left) trained only on Arena data (right) trained on Arena data augmented using golden-label data from the MMLU validation split.
Conversely, on MMLU in Figure 4, all routers perform poorly at a near-random level when trained only on the Arena dataset, which we attribute to most MMLU questions being out-of-distribution. However, augmenting the training dataset using golden-label data from the MMLU validation split leads to significant performance improvements across all routers, with our best-performing causal LLM router now requiring only 54% GPT-4 calls to achieve 95% of GPT-4 performance, 14% cheaper than the random baseline. Importantly, this augmented dataset of approximately 1500 samples represents less than 2% of the overall training data, demonstrating the effectiveness of data augmentation even when the number of samples is small.
RouteLLM vs Commercial Offerings
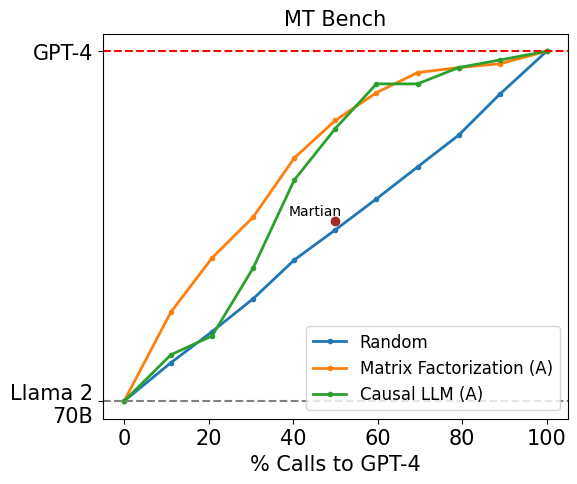
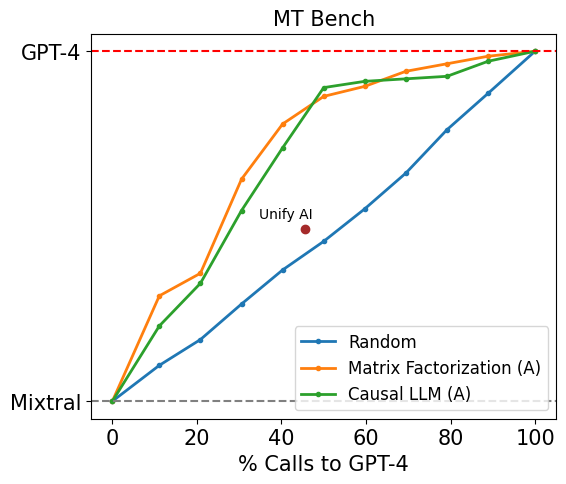
Figure 6: Comparison of our router against existing routing systems on MT Bench (left) using gpt-4-turbo-2024-04-09 and llama-2-70b-chat (right) using gpt-4-turbo-2024-04-09 and mixtral-8x7b-instruct-v0.1
In Figure 6, we also report the performance of our best-performing routers on MT Bench against Martian and Unify AI, two LLM routing products released by companies. We use the latest GPT-4 Turbo as the strong model and either Llama 2 70B or Mixtral 8x7B as the weak model based on the methodology detailed here. Our routers demonstrate very strong results, achieving the same performance as these commercial routers while being over 40% cheaper.
Generalizing to Other Models
While we route between GPT-4 and Mixtral for the above evaluations, to demonstrate the generalizability of our framework, we also present MT Bench results when routing between a different model pair: Claude 3 Opus and Llama 3 8B. Importantly, we use the same routers without any retraining, and responses from Claude 3 Opus and Llama 3 8B are not present in our training data.
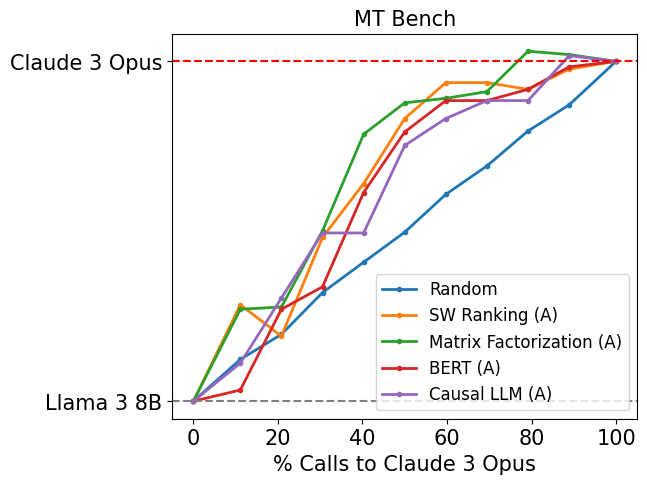
Figure 7: Router performance on MT Bench when routed to Claude 3 Opus and Llama 3 8B.
Even when the model pair is replaced, we observe strong results across all routers on MT Bench in Figure 7, with performance comparable to our original model pair. This suggests that our routers have learned some common characteristics of problems that can distinguish between strong and weak models, which generalize to new model pairs without additional training.
Conclusion
These results demonstrate the ability of our routers to achieve significant cost savings while maintaining high-quality responses. They also highlight the effectiveness of data augmentation in improving routing performance using only a small amount of data, offering a scalable path towards improving routing performance for real-world use cases.
Based on this research, we have created an open-source framework for serving and evaluating routers on GitHub. We are also releasing all our routers and datasets on HuggingFace for public use.
We are excited to see what you build on top of this! Please let us know if you face any issues or have any suggestions. For the full details, please refer to our arXiv paper.
Acknowledgements
We are grateful to Tyler Griggs for his valuable feedback on this post.
Citations
@misc{ong2024routellmlearningroutellms,
title={RouteLLM: Learning to Route LLMs with Preference Data},
author={Isaac Ong and Amjad Almahairi and Vincent Wu and Wei-Lin Chiang and Tianhao Wu and Joseph E. Gonzalez and M Waleed Kadous and Ion Stoica},
year={2024},
eprint={2406.18665},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2406.18665},
}
@misc{chiang2024chatbot,
title={Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference},
author={Wei-Lin Chiang and Lianmin Zheng and Ying Sheng and Anastasios Nikolas Angelopoulos and Tianle Li and Dacheng Li and Hao Zhang and Banghua Zhu and Michael Jordan and Joseph E. Gonzalez and Ion Stoica},
year={2024},
eprint={2403.04132},
archivePrefix={arXiv},
primaryClass={cs.AI}
}