Does style matter? Disentangling style and substance in Chatbot Arena
Why is GPT-4o-mini so good? Why does Claude rank so low, when anecdotal experience suggests otherwise?
We have answers for you. We controlled for the effect of length and markdown, and indeed, the ranking changed. This is just a first step towards our larger goal of disentangling substance and style in Chatbot Arena leaderboard.
Check out the results below! Style indeed has a strong effect on models’ performance in the leaderboard. This makes sense—from the perspective of human preference, it’s not just what you say, but how you say it. But now, we have a way of separating the effect of writing style from the content, so you can see both effects individually.
When controlling for length and style, we found noticeable shifts in the ranking. GPT-4o-mini and Grok-2-mini drop below most frontier models, and Claude 3.5 Sonnet, Opus, and Llama-3.1-405B rise substantially. In the Hard Prompt subset, Claude 3.5 Sonnet ties for #1 with chatgpt-4o-latest and Llama-3.1-405B climbs to #3. We are looking forward to seeing what the community does with this new tool for disaggregating style and substance!
Overall Ranking + Style Control
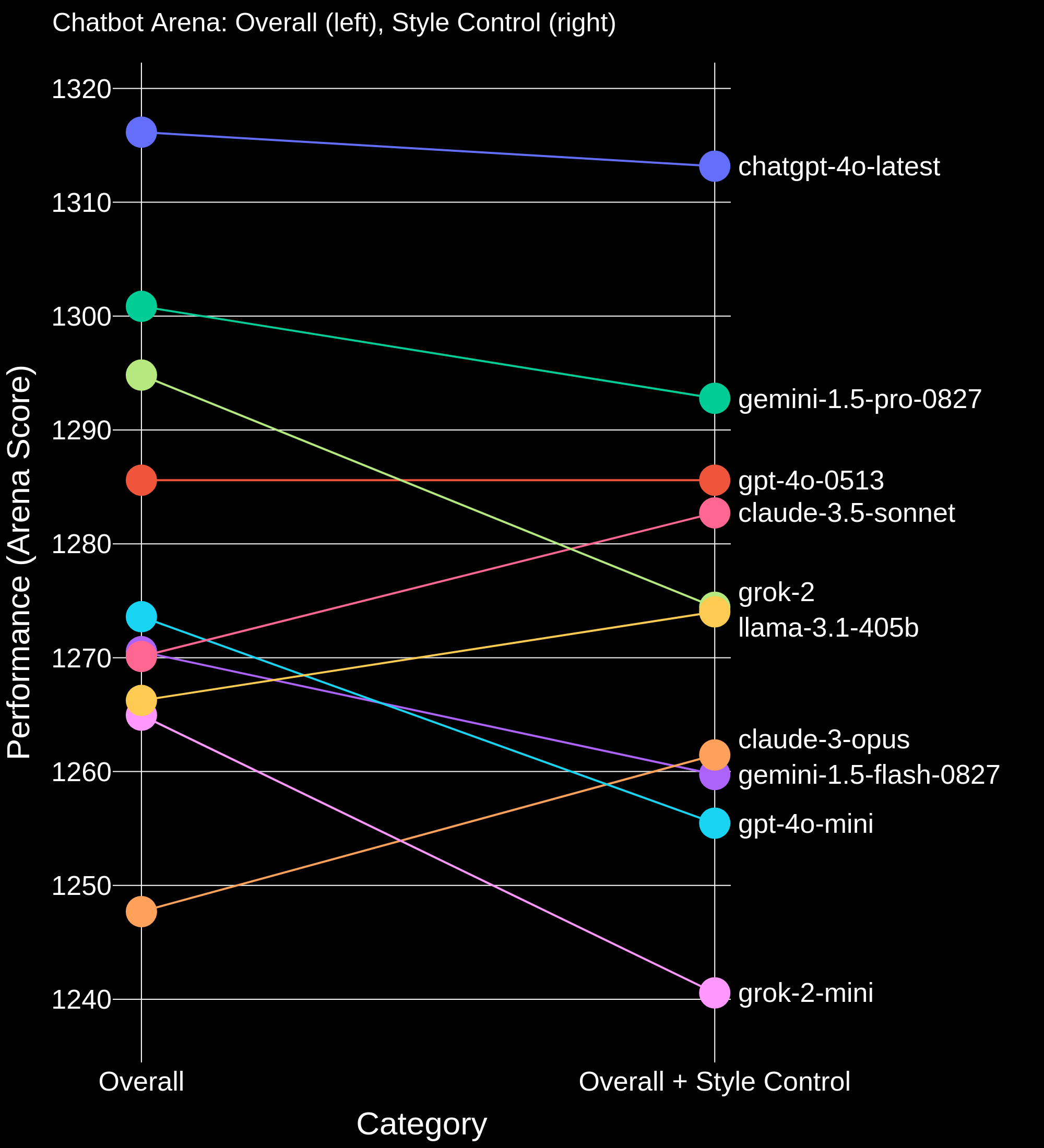
Figure 1. Overall Chatbot Arena ranking vs Overall Chatbot Arena ranking where answer length, markdown header count, markdown bold count, and markdown list element count are being “controlled”.
Hard Prompt Ranking + Style Control
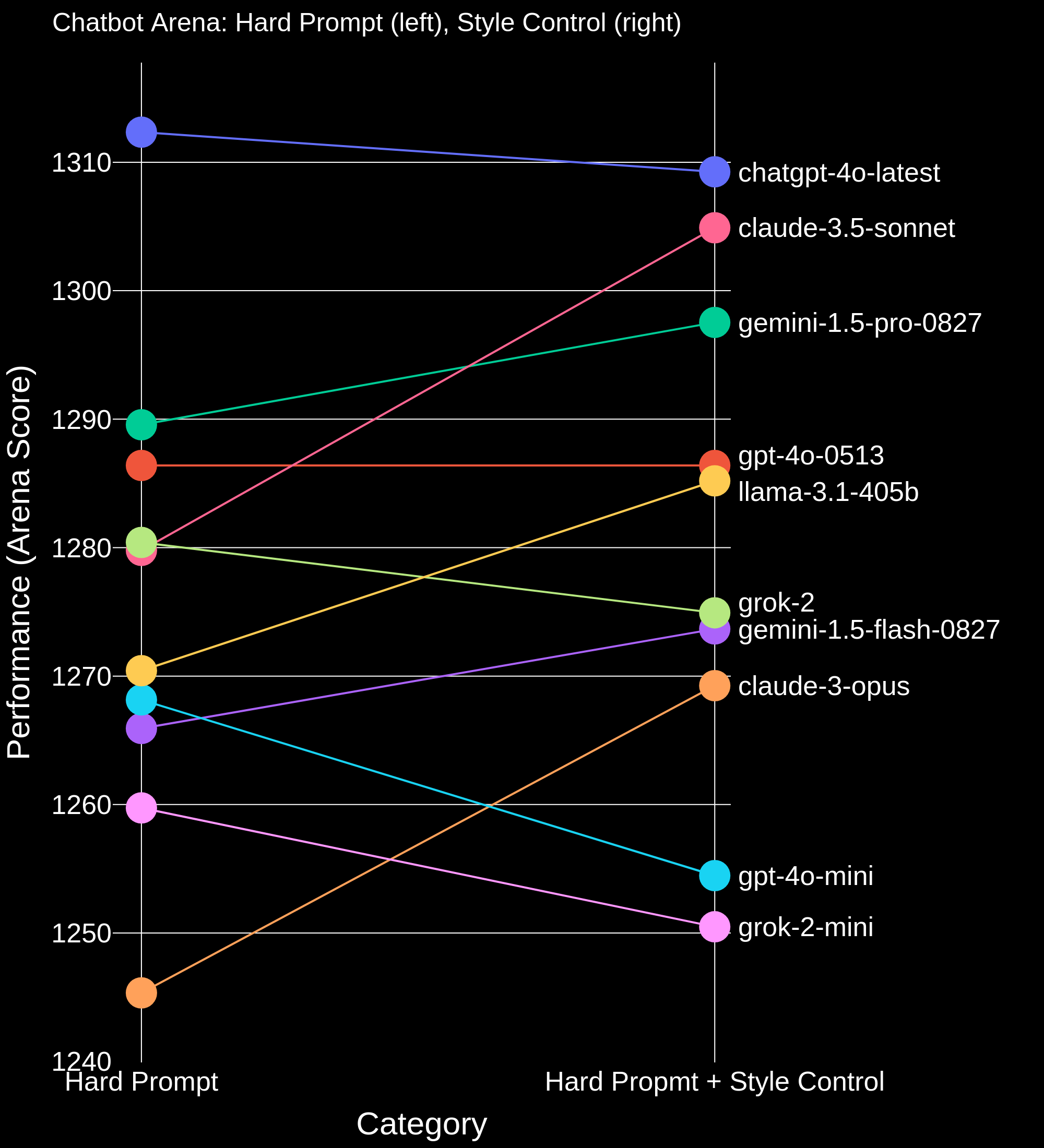
Figure 2. Hard Prompt category ranking vs Hard Prompt category ranking where answer length, markdown header count, markdown bold count, and markdown list element count are being “controlled”.
Full Leaderboard with Style Control
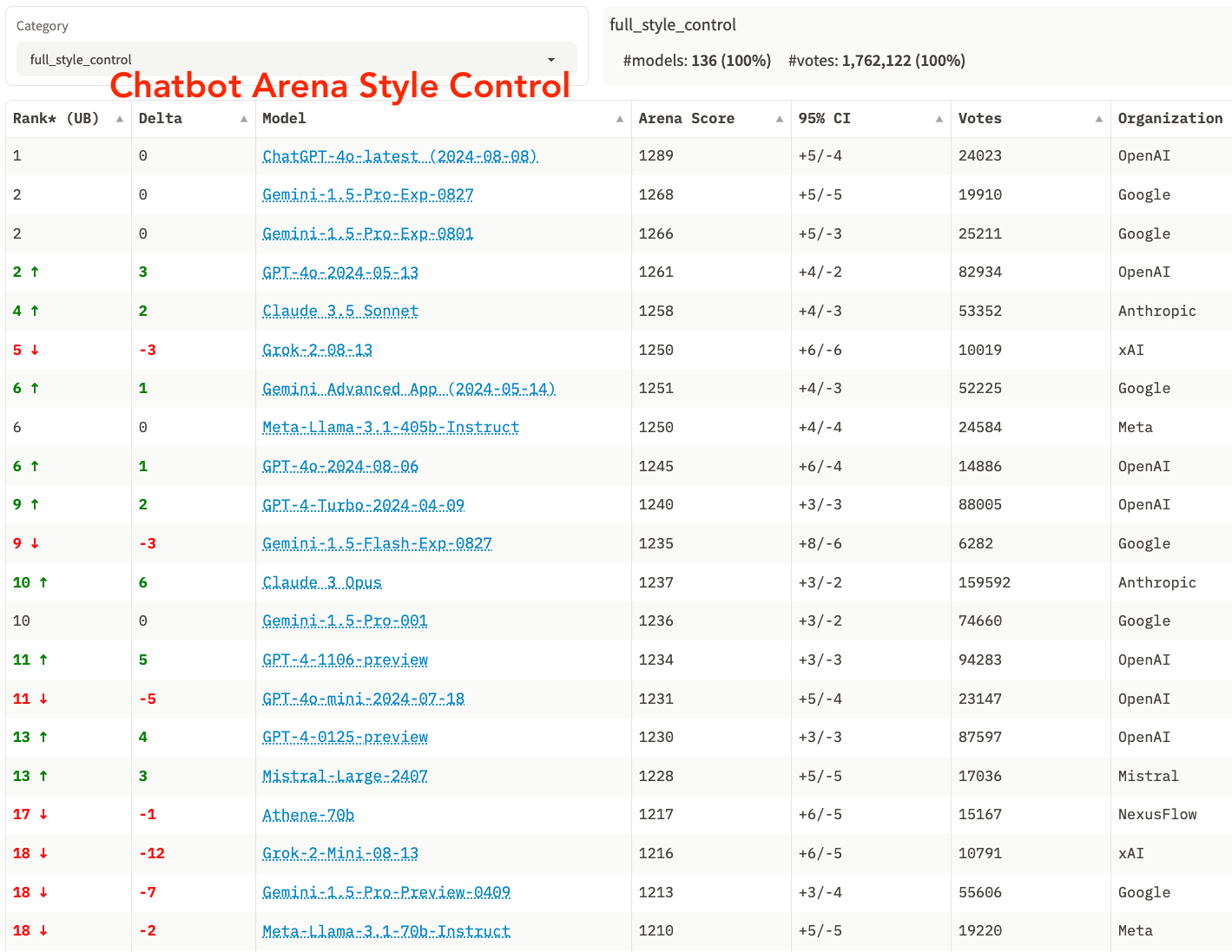
Please find the below links to leaderboard and colab notebook. We will be rolling out style control soon to all the categories. Stay tuned!
Methodology
High-Level Idea. The goal here is to understand the effect of style vs substance on the Arena Score. Consider models A and B. Model A is great at producing code, factual and unbiased answers, etc., but it outputs short and terse responses. Model B is not so great on substance (e.g., correctness), but it outputs great markdown, and gives long, detailed, flowery responses. Which is better, model A, or model B?
The answer is not one dimensional. Model A is better on substance, and Model B is better on style. Ideally, we would have a way of teasing apart this distinction: capturing how much of the model’s Arena Score is due to substance or style.
Our methodology is a first step towards this goal. We explicitly model style as an independent variable in our Bradley-Terry regression. For example, we added length as a feature—just like each model, the length difference has its own Arena Score! By doing this, we expect that the Arena Score of each model will reflect its strength, controlled for the effect of length.
Please read below for the technical details. We also controlled not just for length, but also a few other style features. As a first version, we propose controlling
- Answer token length
- Number of markdown headers
- Number of markdown bold elements
- Number of markdown lists
We publicly release our data with vote and style elements and code on google colab! You can try out experimenting with style control now. More improvements to come, and please reach out if you want to help contribute!
Background. To produce the results above, we controlled for the effect of style by adding extra “style features” into our Bradley-Terry regression. This is a standard technique in statistics, and has been recently used in LLM evaluations [1]. Additionally, there are studies suggesting potential bias for “pretty” and more detailed responses in humans [2, 3]. The idea is that, by including any confounding variables (e.g. response length) in the regression, we can attribute any increase in strength to the confounder, as opposed to the model. Then, the Bradley-Terry coefficient will be more reflective of the model’s intrinsic ability, as opposed to possible confounders. The definition of a confounder is to some extent up to our interpretation; as our style features, we use the (normalized) difference in response lengths, the number of markdown headers, and the number of lists.
More formally, consider vectors and , where is the number of battles and is the number of models.
For every , We have that only if model is the model shown in the left-hand side in Chatbot Arena, and only if it is shown on the right. That is, is a vector with two nonzero elements. The outcome takes the value if the left-hand model wins, and otherwise.
The standard method for computing the Arena Score (i.e., the Bradley-Terry coefficients, which we formerly called the Elo score) is to run a logistic regression of onto . That is, for every model , we associate a scalar that describes its strength, and the vector is determined by solving the following logistic regression:
where represents the binary cross-entropy loss. (In practice, we also reweight this objective to handle non-uniform model sampling, but let’s ignore that for now.)
Style Control
Now, for every battle , let’s say that in addition to that we observe some additional style features, . These style features can be as simple or complicated as you want. For example, could just be the difference in response lengths of the two models, in which case . Or, we could have and include other style-related features, for example, the number of markdown headers, common words associated with refusal, or even style features that are automatically extracted by a model!
Here, we define each style feature as
For example, the first new feature, token length difference between answer A and answer B, would be expressed as
We divide the difference by the sum of both answers' token length to make the length difference proportional to the pairwise answer token lengths. An answer with 500 tokens is roughly equal in length to an answer with 520 tokens, while an answer with 20 tokens is very different from an answer with 40 tokens, even though the difference is 20 tokens for both scenarios. Alternatively, AlpacaEval LC uses the following normalization technique.
.
The idea of style control is very basic. We perform the same logistic regression as before, but with some extra, additive style coefficients: We refer to the results and as the “model coefficients” and the “style coefficients” respectively. The model coefficients have the same interpretation as before; however, they are controlled for the effect of style, which is explicitly modeled by the style coefficients!
When the style coefficients are big, that means that the style feature has a big effect on the response. To define “big”, you need to properly normalize the style coefficients so they can be compared. All in all, when analyzing the style coefficients, we found that length was the dominant style factor. All other markdown effects are second order.
We report the following coefficient for each style attribute across different methods of controlling the style.
| Length | Markdown List | Markdown Header | Markdown Bold | |
|---|---|---|---|---|
| Control Both | 0.249 | 0.031 | 0.024 | 0.019 |
| Control Markdown Only | - | 0.111 | 0.044 | 0.056 |
| Control Length Only | 0.267 | - | - | - |
Ablation
Next, we compare the ranking changes between controlling for answer length only, markdown element only, and both. We present the Chatbot Arena Overall table first.
| Model | Rank Diff (Length Only) | Rank Diff (Markdown Only) | Rank Diff (Both) |
|---|---|---|---|
| chatgpt-4o-latest | 1->1 | 1->1 | 1->1 |
| gemini-1.5-pro-exp-0827 | 2->2 | 2->2 | 2->2 |
| gemini-1.5-pro-exp-0801 | 2->2 | 2->2 | 2->2 |
| gpt-4o-2024-05-13 | 5->3 | 5->3 | 5->2 |
| claude-3-5-sonnet-20240620 | 6->5 | 6->4 | 6->4 |
| gemini-advanced-0514 | 7->5 | 7->8 | 7->6 |
| grok-2-2024-08-13 | 2->4 | 2->4 | 2->5 |
| llama-3.1-405b-instruct | 6->6 | 6->4 | 6->6 |
| gpt-4o-2024-08-06 | 7->6 | 7->8 | 7->6 |
| gpt-4-turbo-2024-04-09 | 11->8 | 11->8 | 11->9 |
| claude-3-opus-20240229 | 16->14 | 16->8 | 16->10 |
| gemini-1.5-pro-api-0514 | 10->8 | 10->13 | 10->10 |
| gemini-1.5-flash-exp-0827 | 6->8 | 6->9 | 6->9 |
| gpt-4-1106-preview | 16->14 | 16->8 | 16->11 |
| gpt-4o-mini-2024-07-18 | 6->8 | 6->11 | 6->11 |
| gpt-4-0125-preview | 17->14 | 17->12 | 17->13 |
| mistral-large-2407 | 16->14 | 16->13 | 16->13 |
| athene-70b-0725 | 16->16 | 16->17 | 16->17 |
| grok-2-mini-2024-08-13 | 6->15 | 6->15 | 6->18 |
| gemini-1.5-pro-api-0409-preview | 11->16 | 11->21 | 11->18 |
We also perform the same comparison on Chatbot Arena Hard Prompt Category.
| Model | Rank Diff (Length Only) | Rank Diff (Markdown Only) | Rank Diff (Both) |
|---|---|---|---|
| chatgpt-4o-latest | 1->1 | 1->1 | 1->1 |
| claude-3-5-sonnet-20240620 | 2->2 | 2->1 | 2->1 |
| gemini-1.5-pro-exp-0827 | 2->2 | 2->2 | 2->1 |
| gemini-1.5-pro-exp-0801 | 2->3 | 2->3 | 2->3 |
| gpt-4o-2024-05-13 | 2->2 | 2->2 | 2->3 |
| llama-3.1-405b-instruct | 4->4 | 4->2 | 4->3 |
| grok-2-2024-08-13 | 2->3 | 2->3 | 2->4 |
| gemini-1.5-flash-exp-0827 | 4->4 | 4->6 | 4->4 |
| gemini-1.5-pro-api-0514 | 7->6 | 7->7 | 7->7 |
| gpt-4o-2024-08-06 | 4->4 | 4->6 | 4->4 |
| gemini-advanced-0514 | 9->7 | 9->7 | 9->7 |
| claude-3-opus-20240229 | 14->7 | 14->7 | 14->7 |
| mistral-large-2407 | 7->7 | 7->6 | 7->7 |
| gpt-4-1106-preview | 11->10 | 11->7 | 11->7 |
| gpt-4-turbo-2024-04-09 | 9->7 | 9->7 | 9->7 |
| athene-70b-0725 | 11->7 | 11->8 | 11->7 |
| gpt-4o-mini-2024-07-18 | 4->7 | 4->7 | 4->11 |
| gpt-4-0125-preview | 15->14 | 15->10 | 15->13 |
| grok-2-mini-2024-08-13 | 5->12 | 5->8 | 5->13 |
| deepseek-coder-v2-0724 | 16->14 | 16->13 | 16->14 |
Limitations and Future Work
We want to continue building a pipeline to disentangle style and substance in the arena. Although controlling for style is a big step forward, our analysis is still observational. There are possible unobserved confounders such as positive correlation between length and substantive quality that are not accounted for by our study. For example, well-known example of a possible unobserved confounder that might positively impact both length and quality is a chain-of-thought explanation for a reasoning question.
To address these limitations, we are looking forward to implementing causal inference in our pipeline, and running prospective randomized trials to assess the effect of length, markdown, and more. Our pipeline for style control will be changing as we continue to improve our system and refine the analysis. Stay tuned, and let us know if you want to help!
Reference
[1] Dubois et al. “Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators”, arXiv preprint
[2] Chen et al. “Humans or LLMs as the Judge? A Study on Judgement Bias”, arXiv preprint
[3] Park et al. “Disentangling Length from Quality in Direct Preference Optimization”, arXiv preprint
Citation
@misc{chiang2024chatbot,
title={Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference},
author={Wei-Lin Chiang and Lianmin Zheng and Ying Sheng and Anastasios Nikolas Angelopoulos and Tianle Li and Dacheng Li and Hao Zhang and Banghua Zhu and Michael Jordan and Joseph E. Gonzalez and Ion Stoica},
year={2024},
eprint={2403.04132},
archivePrefix={arXiv},
primaryClass={cs.AI}
}