Deploying DeepSeek with PD Disaggregation and Large-Scale Expert Parallelism on 96 H100 GPUs
by: The SGLang Team, May 05, 2025
DeepSeek is a popular open-source large language model (LLM) praised for its strong performance. However, its large size and unique architecture, which uses Multi-head Latent Attention (MLA) and Mixture of Experts (MoE), require an advanced system for efficient serving at scale. In this blog, we explain how we match DeepSeek's inference system performance with SGLang.
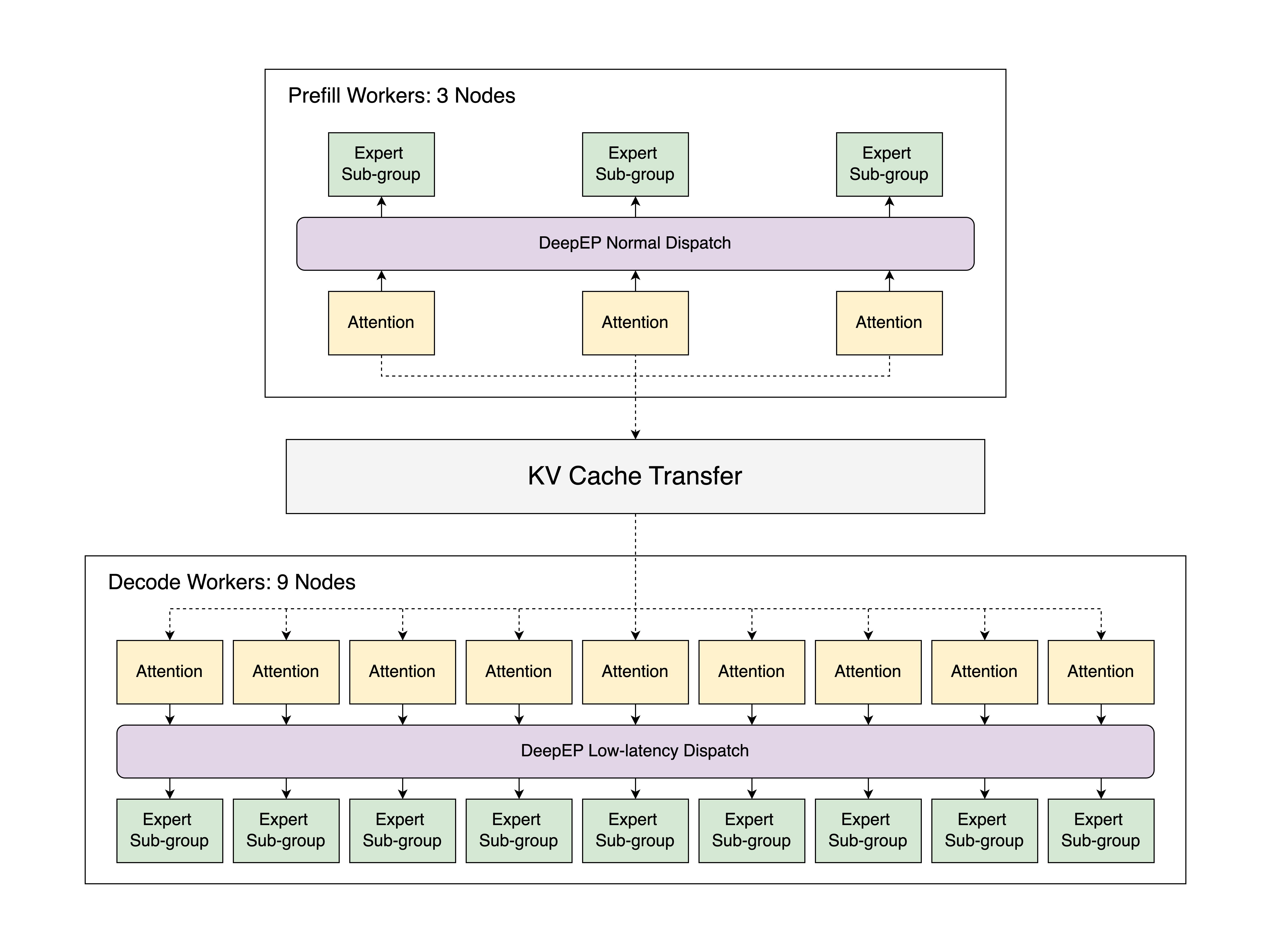
Our implementation, shown in the figure above, runs on 12 nodes in the Atlas Cloud, each equipped with 8 H100 GPUs. It uses prefill-decode disaggregation and large-scale expert parallelism (EP), achieving a speed of 52.3k input tokens per second and 22.3k output tokens per second per node for 2000-token input sequences. To the best of our knowledge, this represents the first open-source implementation to nearly match the throughput reported in the official DeepSeek blog at large scale. By deploying this implementation locally, it translates to a cost of $0.20/1M output tokens, which is about one-fifth the cost of the official DeepSeek Chat API. Compared to vanilla tensor parallelism using the same resources, this optimized strategy improves the output throuhgput by up to 5x. This blog dives into our parallelism design, optimization methods, and results. All components of our work are fully open-source, allowing others to explore and build on our efforts. The instructions for reproducing our experiments are fully available here.
Highlight
✅ SGLang now supports prefill-decode (PD) disaggregation and large-scale EP, including the full functionality of DeepEP, DeepGEMM, and EPLB.
✅ Leveraging these new features, our team successfully replicated DeepSeek's inference system using 12 nodes, each with 8 H100 GPUs. In total, SGLang achieves a throughput of 52.3k input tokens per second and 22.3k output tokens per second per node for input sequences of 2000 tokens.
✅ This blog explains technical details of our approach, focusing on optimizations for efficiency, peak memory usage reduction, and workload balancing. The profile results show that our implementation achieves nearly on-par performance with the official DeepSeek’s report.
✅ All experiments and code are fully open-sourced for community access and further development.
Outline
- Parallelism Design
- Prefill and Decode Disaggregation
- Large-scale Expert Parallelism
- Evaluation
- Toolkits
- Limitations and Future Work
- Conclusion
- Acknowledgment
Parallelism Design
Efficient parallelism is essential to manage the computational complexity and memory demands of DeepSeek's architecture. This section outlines our approach to optimizing key components: attention layers, dense feed-forward networks (FFNs), sparse FFNs, and the language model (LM) head. Each component leverages tailored parallelism strategies to enhance scalability, memory efficiency, and performance.
Attention Layers
DeepSeek employs Multi-head Latent Attention (MLA) to effectively model complex dependencies within input sequences. To optimize this mechanism, we implement DP Attention, a data parallelism strategy that eliminates KV cache duplication across devices, significantly reducing memory overhead. Introduced in SGLang v0.4, this approach has been extended to support hybrid data and tensor parallelism, offering flexibility for processing small batch sizes efficiently.
Dense FFNs
Despite using only three dense FFN layers, DeepSeek-V3's computation can significantly increase peak memory usage, potentially leading to system crashes if not carefully managed. To address this, we adopt Data Parallelism (DP) over tensor parallelism (TP), leveraging the following advantages:
- Enhanced Scalability: With an intermediate dimension of 18,432, high TP degrees (e.g., TP32) result in inefficient fragmentation into small-unit segments (e.g., 576 units), which are not divisible by 128—a common alignment boundary for modern GPUs such as H100. This misalignment hampers computational efficiency and memory utilization. DP provides a more scalable solution by avoiding fragmentation, ensuring balanced workload distribution across devices.
- Optimized Memory Efficiency: Traditionally, TP reduces memory usage as worker size increases, but this advantage diminishes under DP attention. In a pure TP setup, memory demand for a single-layer Transformer model scales with DP size as: $$\text{Memory}=\frac{N_{\text{param}}}{\text{TP}}+(1+k)N_{\text{hidden_state}}\cdot \text{DP}\notag$$ Here, $N_{\text{hidden_state}}=n_\text{token}\times n_\text{hidden_size}$ is the size of the hidden state on each device (DP rank), $N_{\text{param}}=n_\text{intermediate_size}\times n_\text{hidden_size}$ is the number of model parameters, and $k$ is a coefficient representing extra memory overhead from CUDA Graph duplication. By assuming $\text{DP}=\text{TP}$, this memory usage function is minimized when $\text{TP}=\sqrt{\frac{N_{\text{param}}}{(1+k)N_{\text{hidden_state}}}}$. DeepSeek-V3 uses an intermediate size of 18,432. During the prefill phase, CUDA Graph is typically disabled, so $k = 0$. However, the token size per device can easily exceed 2,048, resulting in an optimal TP size of 3 or less. In the decode phase, a practical configuration might use 128 tokens per device and set $k = 3$. In this case, the memory-optimal TP size is 6. In both phases, a lower TP degree minimizes memory usage per device. As a result, DP may offer a more memory-efficient approach for scaling compared to relying solely on TP.
- Minimized Communication Overhead: In pure TP, each FFN necessitates two all-reduce operations, resulting in substantial communication overhead. By leveraging DP, we optimize this process to a single reduce-scatter following the prior attention layer and an all-gather before the next, reducing communication costs by 50%. Furthermore, when attention is also computed under pure DP, inter-device communication is entirely eliminated, significantly enhancing overall efficiency.
The integration of DP dense FFN with DP attention is illustrated in the left figure below. Users can enable this feature by setting --moe-dense-tp-size=1.
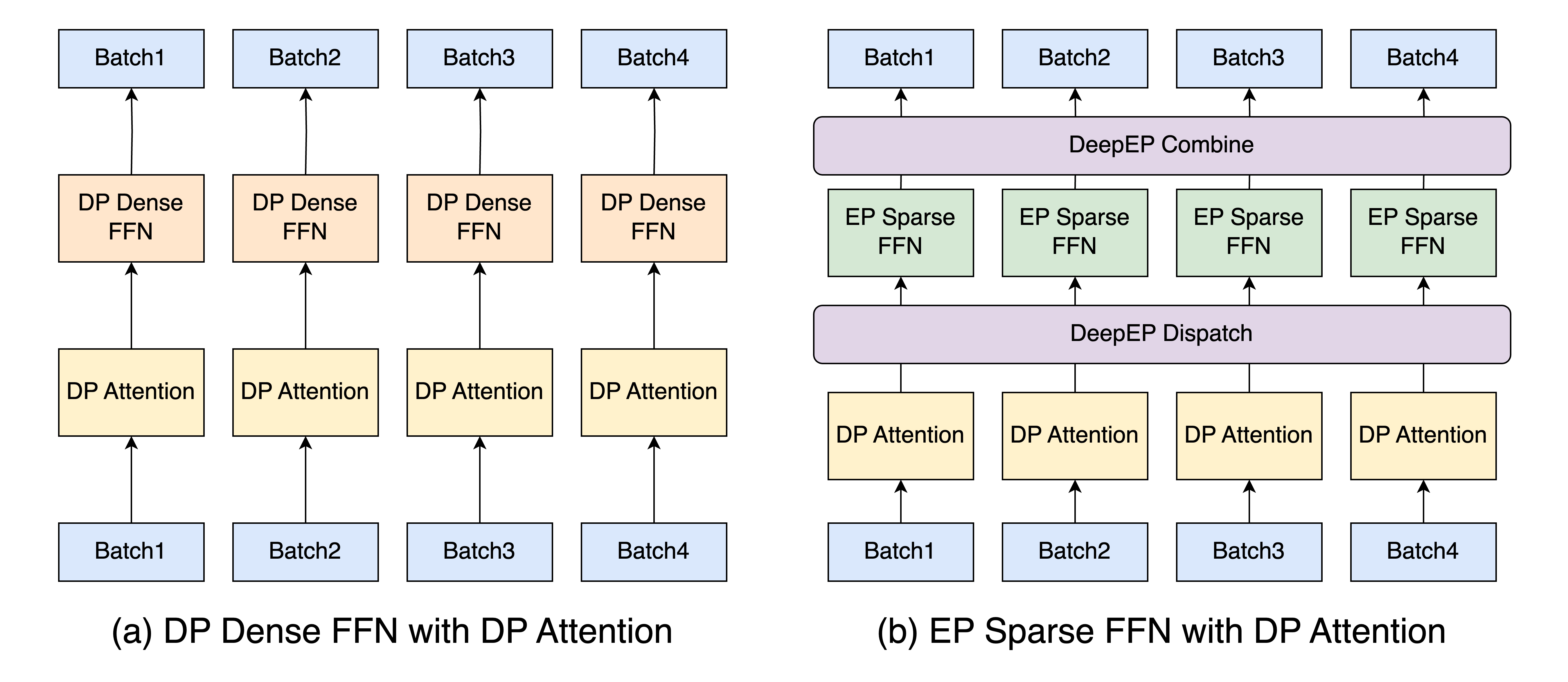
Sparse FFNs
In DeepSeek-V3's Mixture of Experts (MoE) architecture, sparse FFNs require substantial expert weights, creating a significant memory bottleneck. To address this, we implement Expert Parallelism (EP), which distributes expert weights across multiple devices. This approach effectively scales memory capacity while maintaining high performance, though it does introduce challenges like irregular all-to-all communication and workload imbalance.
The figure in the right figure above illustrates our EP implementation using the DeepEP framework, with further details on our EP design and optimizations provided in the following sections.
LM Head
The LM head computes output probabilities over a large vocabulary, a resource-intensive operation traditionally handled with vocabulary parallelism to aggregate token logits from TP groups. To enhance scalability and efficiency, we adopt Data Parallelism (DP), mirroring our dense FFN strategy. This reduces memory overhead and simplifies communication across devices, delivering a more streamlined solution.
Prefill and Decode Disaggregation
LLM inference comprises two distinct phases: Prefill and Decode. The Prefill phase is computation-intensive, processing the entire input sequence, while the Decode phase is memory-intensive, managing the Key-Value (KV) cache for token generation. Traditionally, these phases are handled within a unified engine, where combined scheduling of prefill and decode batches introduces inefficiencies. To address these challenges, we introduce Prefill and Decode (PD) Disaggregation in SGLang.
Issues with Unified Scheduling
The conventional unified engine, which processes prefill and decode batches together, results in three significant problems:
- Prefill Interruption: Incoming prefill batches frequently interrupt ongoing decode batches, causing substantial delays in token generation.
- DP Attention Imbalance: In DP attention, one DP worker may process a prefill batch while another handles a decode batch simultaneously, leading to increased decode latency.
- Incompatible with DeepEP: As we will discuss in a later section, DeepEP executes different dispatch modes for prefill and decode, making unified scheduling imcompatible with DeepEP.
PD Disaggregation resolves these by separating the two stages, enabling tailored optimizations for each.
Implementation Details
The PD Disaggregation design in SGLang, depicted in the diagram below, interleaves execution between a Prefill Server and a Decode Server:
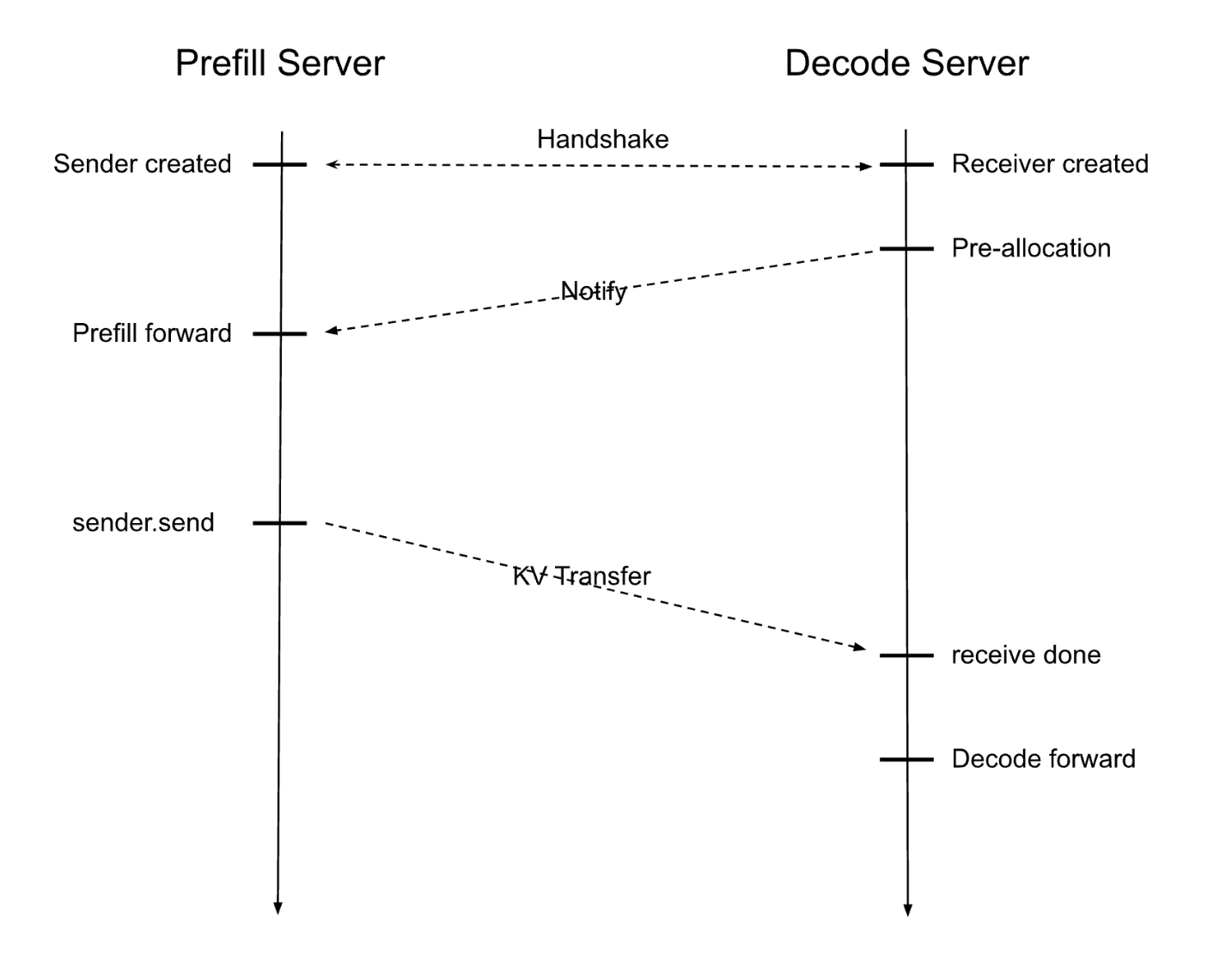
Upon receiving an input request, the workflow proceeds as follows:
- A Prefill Server and a Decode Server pair via a handshake, establishing a local sender and receiver, respectively.
- The Decode Server pre-allocates the KV cache, signaling the Prefill Server to begin the model forward pass and compute the KV caches.
- Once computed, the data transfers to the Decode Server, which handles iterative token generation.
This separation ensures each phase operates under optimal conditions, maximizing GPU resource utilization. To further enhance performance, our implementation incorporates:
- Non-blocking Transfer: Data send and receive operations run in a background thread, keeping the scheduler’s event loop uninterrupted.
- RDMA-Based Transfer: Remote Direct Memory Access (RDMA) leverages queue pairs for connections and scatter-gather elements (SGE) for efficient transfer of non-contiguous memory chunks.
- Flexible API Integration: SGLang offers adaptable APIs that integrate high-performance RDMA libraries like Mooncake and NIXL, streamlining data transfers.
More details can be found in our design document.
Large-scale Expert Parallelism
Expert Parallelism with DeepEP
DeepEP, implemented by the DeepSeek team, is a communication library designed to streamline EP in MoE models. It tackles the challenge of efficiently routing tokens to specific experts across multiple GPUs. By providing optimized communication kernels, DeepEP reduces latency and boosts throughput, making it ideal for large-scale inference tasks.
DeepEP provides two specialized dispatch modes to address varying workload demands:
- Normal Dispatch: Optimized for handling long input sequences, such as during the prefill phase, this mode prioritizes maximum computational throughput. However, it generates symbolic shapes that are incompatible with CUDA Graph, rendering it less effective for the decode phase, where kernel launch overhead becomes a significant bottleneck.
- Low-Latency Dispatch: Tailored for generating output tokens during the decode phase, this mode prioritizes minimal delay to ensure real-time performance. It supports CUDA Graph but requires preallocating a fixed memory size. If the memory demand exceeds this preallocation, a runtime error occurs.
In SGLang, the integration of DeepEP provides auto mode that dynamically selects between these two dispatch modes based on the workload. However, without PD disaggregation, the auto mode faces a limitation: it cannot simultaneously support both normal dispatch (for prefill) and low-latency dispatch (for decode) within the same communication group. This restriction hinders its compatibility with DP attention, which is crucial for memory-efficient inference. The compatibility of each mode is outlined in the table below:
| Mode | Long Input | Long Output | DP Attention | CUDA Graph |
|---|---|---|---|---|
| Normal | ✅ | ❌ | ✅ | ❌ |
| Low-Latency | ❌ | ✅ | ✅ | ✅ |
| Auto | ✅ | ✅ | ❌ | ✅ |
PD disaggregation addresses this by separating prefill and decode phases, allowing normal dispatch for the prefill phase and low-latency dispatch for the decode phase, both under DP attention. This integration optimizes resource utilization and enhances overall performance by aligning the dispatch mode with the specific needs of each phase.
DeepGEMM Integration
DeepGEMM is another high-efficient library developed by the DeepSeek team, specifically designed to optimize computations in MoE models. It provides two specialized functions for handling MoE-related matrix multiplications (Grouped GEMMs), each tailored to different phases of the inference process.
- Grouped GEMMs (contiguous layout): This kernel is designed for dynamic input shapes, making it ideal for the prefill phase of MoE inference. It processes inputs where the data for different experts is concatenated contiguously, allowing for flexible handling of varying input sizes.
- Grouped GEMMs (masked layout): This kernel assumes a fixed input shape and uses a mask tensor to compute only the valid portions of the input. It is compatible with CUDA Graph, which optimizes kernel launches, making it well-suited for the decode phase where reducing overhead is critical.
DeepGEMM integrates smoothly with the dispatch modes of DeepEP:
- For the contiguous layout kernel, which is used with normal dispatch in the prefill phase, an additional step is required. Since normal dispatch outputs a symbolic shape, a permutation is needed to transform the output into the contiguous format expected by the kernel. We referred to the LightLLM project and implemented a custom Triton kernel for efficient permutation. This kernel ensures that the output from normal dispatch is correctly rearranged, enabling smooth integration with the contiguous GEMM kernel.
- The masked layout kernel pairs seamlessly with DeepEP’s low-latency dispatch, as both are optimized for the decode phase and support CUDA Graph.
SGLang also integrates DeepGEMM for MoE computation under tensor parallelism. Additionally, DeepGEMM provides a highly efficient general GeMM kernel, which can be activated in SGLang by setting the environment variable SGL_ENABLE_JIT_DEEPGEMM to 1, offering even greater computational efficiency for non-MoE operations.
Two-batch Overlap
In multi-node environments, limited communication bandwidth can significantly increase overall latency. To tackle this challenge, we implemented Two-batch Overlap (TBO) following DeepSeek's system design. TBO splits a single batch into two micro-batches, allowing computation and communication to overlap, which also lowers peak memory usage by halving the effective batch size. However, putting TBO into practice introduces specific implementation difficulties.
Implementation Challenges
Although DeepSeek released the design framework of TBO, there are two slight implementation challenges.
- Code Complexity: Directly coding TBO can lead to duplicated logic for managing multiple micro-batches. This increases the complexity of the codebase, making it harder to maintain and prone to errors, especially as the number of micro-batches or overlapping scenarios grows.
- Synchronization Issues in the Prefill Phase: Achieving effective overlap between computation and communication needs consideration when the normal dispatch in DeepEP block the CPU. This blocking behavior can stall the pipeline, leaving the GPU idle and undermining the performance benefits of TBO.
Abstraction for Clean Implementation
To create a more maintainable and reusable codebase, we use an abstraction layer consisting of operations and yield points. This method simplifies development by allowing us to write code as if handling a single micro-batch, while strategically pausing execution by inserting yield points to let other micro-batches proceed. It eliminates code duplication, reduces the potential need for variable postfixes, and efficiently manages cases where some executions complete at a layer's end while others have not. Additionally, it supports easy adaptation to different overlapping region choices or future enhancements, like a three-batch overlap, with minimal code changes. Below is a concise demonstration of this approach:
operations = [
self._forward_attn,
YieldOperation(), # Pause execution for other micro-batches
self._forward_dispatch,
self._forward_mlp,
YieldOperation(), # Another pause point
self._forward_combine,
]
# Process a single micro-batch without duplicating code
def _forward_attn(self, state):
state.hidden_states = self.self_attn(state.hidden_states, ...)
Prefill Overlapping Implementation
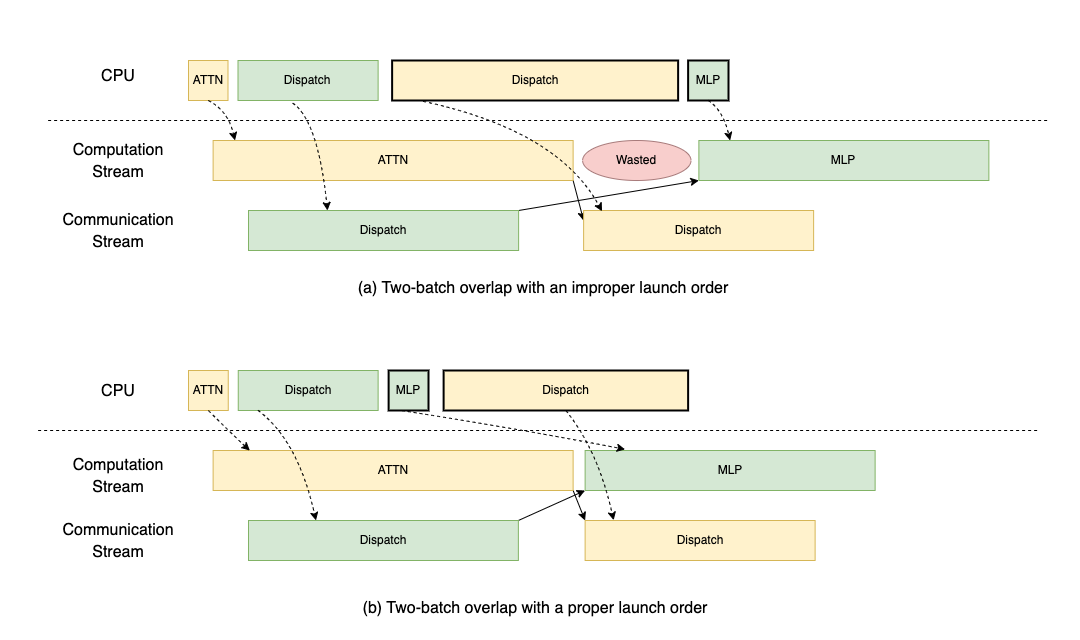
We refine the launch order during the prefill phase to avoid CPU-blocking via the dispatch operation in DeepEP, even though we are using its asynchronous mode. Specifically:
- The dispatch operation blocks the CPU until the GPU receives metadata from other ranks to allocate correctly sized tensors.
- An improper implementation would leave the computation stream idle during this period, as no computation tasks are submitted to the GPU.
To optimize, we prioritize submitting computation tasks to the GPU before launching CPU-blocking communication. This ensures the GPU remains active during communication. As illustrated in the figure below, TBO with a proper launch order, indicated by bolded borders, avoids bubble caused by a CPU-blocking operation (i.e., normal dispatch).
Expert Parallelism Load Balancer
In MoE models, EP often leads to uneven workload distribution across GPUs. This imbalance forces the system to wait for the slowest GPU computation or communication, wasting compute cycles and increasing memory usage due to expert activations. As the number of GPUs (EP size) increases, the imbalance issue gets more severe.
To address this, DeepSeek developed the Expert Parallelism Load Balancer (EPLB). EPLB takes expert distribution statistics as input and computes an optimal arrangement of experts to minimize imbalance. Users can allocate redundant experts (e.g., 32 additional experts), which, when combined with the original 256, create a pool of 288 experts. This pool allows EPLB to strategically place or replicate experts—for instance, duplicating the most frequently used expert multiple times or grouping a moderately used expert with rarely used ones on a single GPU.
Beyond balancing workloads, EPLB offers greater flexibility in parallelism design. With the original 256 experts, parallelism sizes are restricted to powers of two. EPLB’s use of 288 experts enables more diverse configurations, such as parallelism sizes of 12 or 72.
In the figure below, we demonstrate the effects of scale and EPLB algorithm to the imbalance issue via simulation. We compute GPU balancedness as the ratio between mean computation time and maximum computation time for a MoE layer among GPUs, and we use the number of tokens for a GPU to estimate the computation time for it. As can be seen, utilization rate decreases when the system scales with the number of nodes, and enabling EPLB significantly improves the utilization.
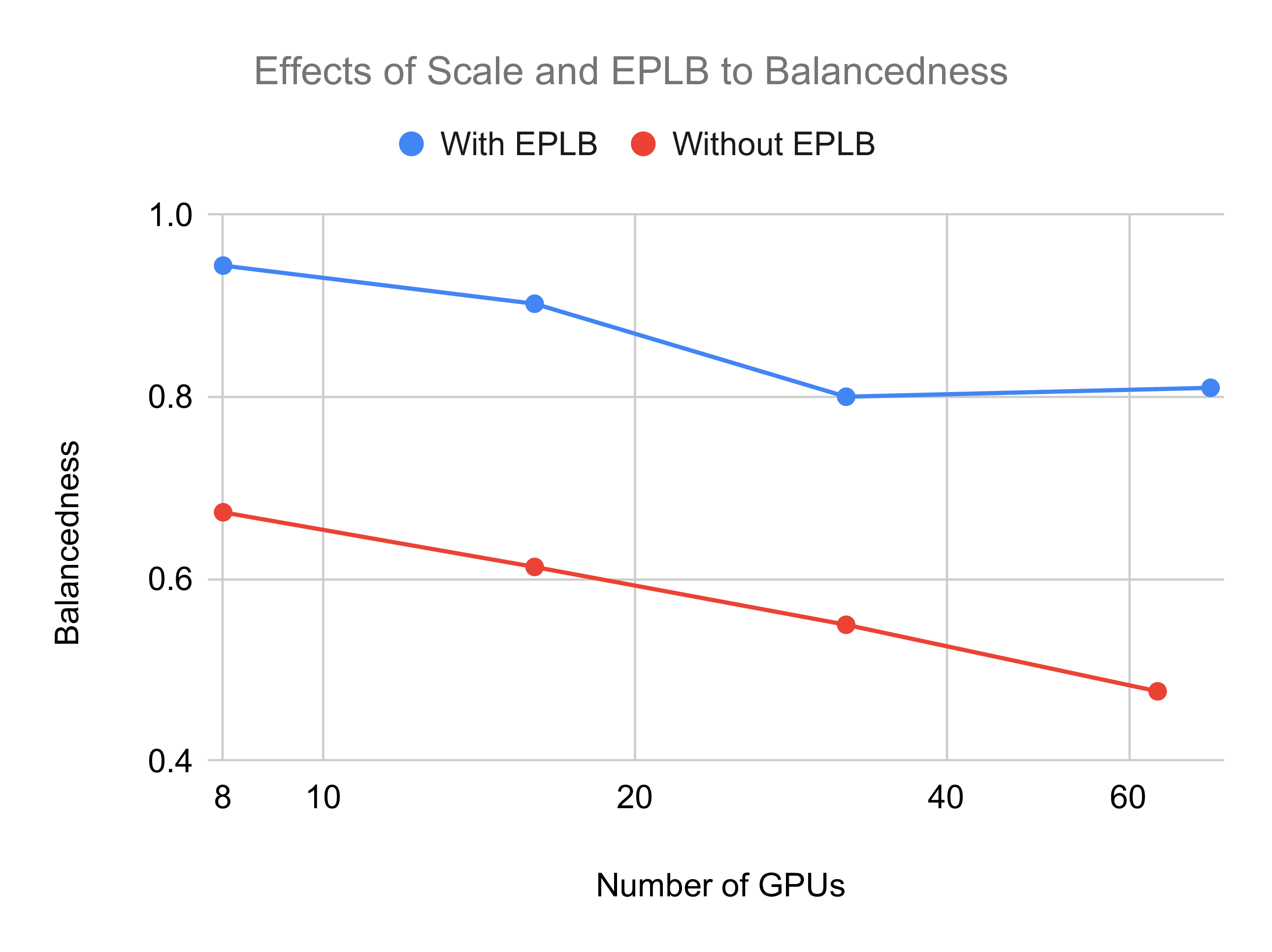
EPLB for Real-World Serving
For EPLB to be effective, the input distribution must closely match the actual serving workload. Two strategies enhance this alignment:
- Increasing Batch Size: Larger batches reduce random fluctuations in expert usage, which improves balance, which can be achieved by scaling the cluster or using techniques like Multi-Token Prediction (MTP).
- Periodic Rebalancing: Regularly updating the expert arrangement leverages temporal locality but requires efficient reloading of experts. This necessitates minimizing the cost of expert reloading operations.
Even with EPLB, some imbalance is inevitable, making further optimization a valuable future direction.
Implementation of Rebalancing
SGLang implements expert rebalancing in three stages to ensure efficiency and minimal disruption:
- System Loading Stage: Weights are optionally preloaded from disk to main memory for faster rebalancing or kept on disk with memory mapping (mmap) for reduced memory usage.
- Rebalance Preparation Stage: Required weights are asynchronously transferred to device memory in the background, utilizing free DMA hardware engines without interrupting ongoing GPU operations.
- Rebalance Execution Stage: A device-to-device copy updates the weights. This step can be further optimized through physical memory rebinding techniques.
This staged approach ensures that rebalancing is both efficient and non-disruptive, maintaining system performance during updates.
Evaluation
End-to-end Performance
Experimental Setup
We evaluated the end-to-end performance of different configurations of SGLang using DeepSeek-V3 on a cluster of 12 nodes, connected via InfiniBand and each equipped with 8 H100 GPUs. This evaluation highlights the throughput improvements enabled by our advanced optimization techniques. We compared the following four settings:
- SGLang with TP16 x 6: Every two nodes are paired with an independent group, running DeepSeek-V3 inference with a TP size of 16 and DP attention.
- SGLang with PD Disaggregation: This version incorporates PD disaggregation and full EP optimization. For the EPLB, we adopt a distribution matching the input/output data, as real-time serving statistics are unavailable.
- SGLang with PD Disaggregation and simulated MTP: To simulate MTP’s effects, we firstly double the batch size and halve the Key-Value KV cache length to maintain the same workload for GroupedGeMM computation and memory access. Moreover, we insert dummy kernels after the real attention computation to ensure the attention phase takes the same time as in DeepSeek’s profile, accurately reflecting the slowdown caused by MTP’s attention mechanism. We conservatively assume a 70% acceptance rate under MTP.
- DeepSeek Profile Results: Throughput estimates are derived from DeepSeek’s official profiling data.
Performance Analysis of Prefill and Decode Phases
To accommodate varying workload demands, we independently evaluated the prefill (P) and decode (D) phases, assuming unlimited resources for the non-tested phase to isolate and maximize the load on the tested nodes—mirroring the setup used by DeepSeek. The results are summarized below:
- Prefill Phase: On 4 nodes (4×8×H100, EP32), the system achieved per-node throughputs of 57,674, 54,543, and 50,302 tokens per second for prompt lengths of 1K, 2K, and 4K, respectively. As shown in the bar chart below, this represents up to a 3.3× improvement over the TP16 baseline, largely attributable to the optimized GroupedGeMM kernel (DeepGEMM) and two-batch overlap. Assuming a perfectly balanced workload, our system’s throughput is within 5.6% of DeepSeek's official profile.
- Decode Phase: Evaluated on 9 nodes (9×8×H100, EP72; half the scale of DeepSeek), the system achieved 22,282 tokens/sec per node for 2K inputs—representing a 5.2× speedup over the TP16 baseline. Under simulated MTP conditions—with attention kernels intentionally slowed to reflect real-world latency—the system sustained a high throughput of 17,373 tokens/sec per node for 4K inputs, just 6.6% below DeepSeek’s official profile. As shown in the figure on the right, these performance gains are largely attributed to 4× larger batch sizes enabled by EP, which enhances scalability by significantly reducing per-GPU memory consumption of model weights.
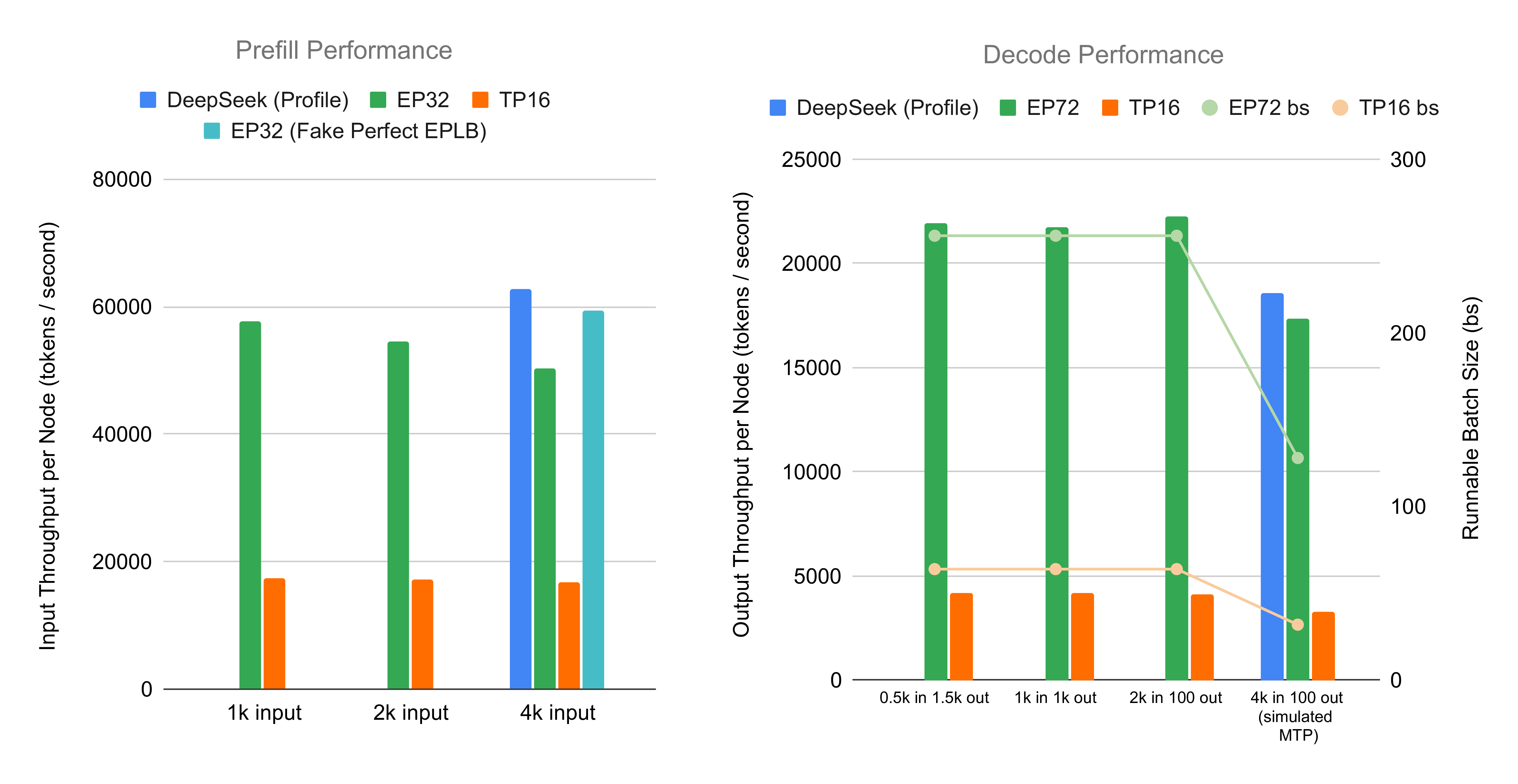
Profile Results
This section compares SGLang’s performance with DeepSeek’s inference system, aligning our experimental setup as closely as possible to DeepSeek’s production environment. We analyze overall throughput and detailed kernel breakdowns, benchmarking against DeepSeek’s blog and public profile data.
Overall Throughput
For prefill, we tested a scenario with 16,384 tokens per device and an input length of 4,096. Due to uncertainty in DeepSeek’s expert distribution, we evaluated two cases: one with default expert distribution and another with simulated perfect EPLB (random expert selection following group-limited routing semantics) as a performance upper bound.
The results are presented below:
| DeepSeek Blog (excl. cache hit) | DeepSeek Profile | SGLang (Default) | SGLang + Simulated Perfect EPLB | |
|---|---|---|---|---|
| Batch Size | N/A | 16,384 | 16,384 | 16,384 |
| Input Length | N/A | 4,096 | 4,096 | 4,096 |
| Throughput (per node) | 32,206 | 62,713 | 50,302 | 59,337 |
DeepSeek’s profile reports a throughput roughly twice that of its production environment. SGLang with default expert imbalance is 20% slower than DeepSeek’s profile, while the simulated perfect EPLB case narrows the gap to 6%.
For decode, the results are shown below:
| DeepSeek Blog | DeepSeek Profile | SGLang (Default) | SGLang + Simulated MTP (Slow Attention) | |
|---|---|---|---|---|
| Batch Size | N/A | 128 | 256 | 128 |
| KV Cache Length | 4,989 | 4,096 | 2,000 | 4,000 |
| Number of Nodes | 18 | 16 | 9 | 9 |
| Throughput (per node) | 14,800 | 18,598 | 22,282 | 17,373 |
Using half the nodes of DeepSeek, SGLang with simulated MTP is only slightly slower than DeepSeek’s profile. In a higher batch size setting (256 sequences, 2,000 input length), SGLang achieves 22,282 tokens per second per node, demonstrating strong scalability.
Detail Breakdown
The figure below breaks down kernel execution times for prefill, including unit test results as a theoretical upper bound:
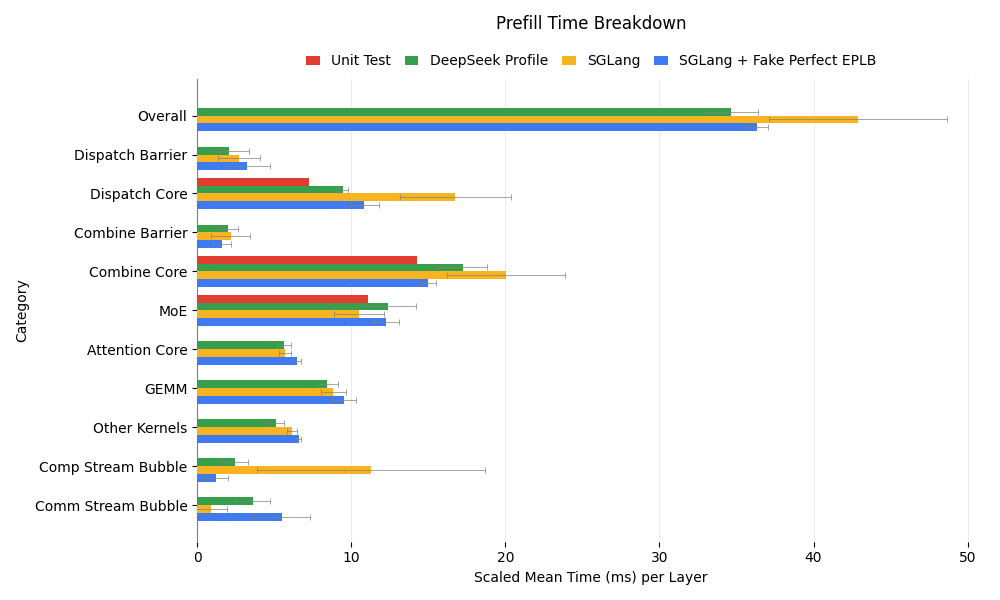
- Default EPLB: Communication kernels exhibit longer execution times and higher variance compared to DeepSeek’s profile, likely due to greater expert imbalance. This leads to extended computation stream bubbles, slowing down overall performance.
- Simulated Perfect EPLB: This setup aligns more closely with DeepSeek’s profile, though discrepancies remain, indicating potential areas for optimization.
- Comparison with Unit Tests: Both DeepSeek and SGLang have a communication time slower than unit test results, while the latter is achievable when disabling TBO, revealing a potential optimization direction if communication is the bottleneck.
SGLang’s decode kernel breakdown aligns closely with DeepSeek’s, as shown below:
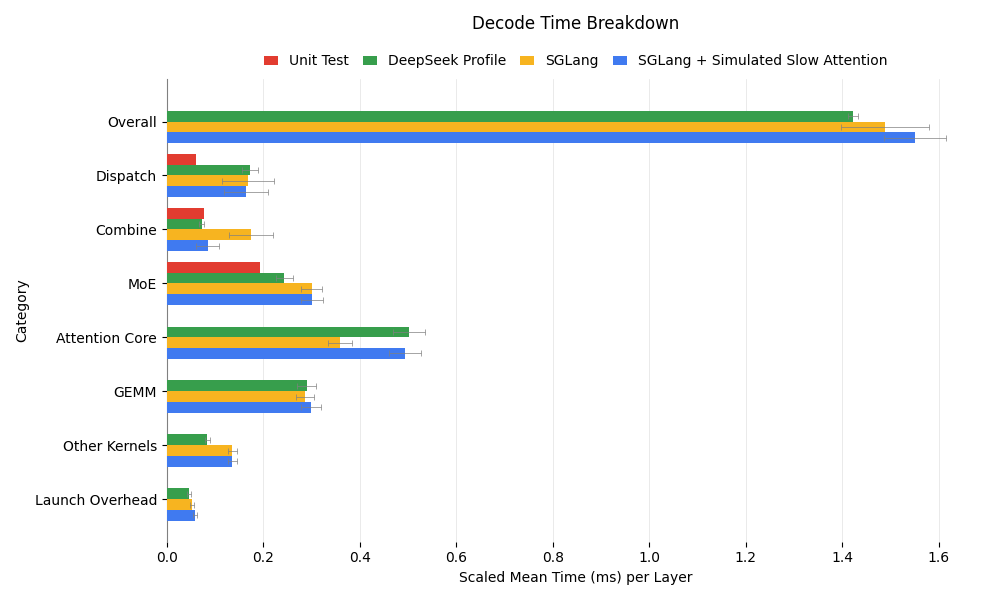
Key observations include:
- Combine Time Discrepancy: SGLang’s combine operation appears 2x slower than DeepSeek’s due to shorter attention computation, causing communication kernels to busy-wait. In the simulated slow attention experiment, combine time matches DeepSeek’s, confirming this hypothesis.
- MoE Performance: SGLang’s MoE kernels are 25% slower, possibly because DeepSeek’s 18 nodes (versus our 9) distribute experts more efficiently, reducing memory access overhead for GEMM operations.
- Dispatch Optimization Potential: Both DeepSeek and SGLang show dispatch times of ~0.17ms per layer, but unit tests with DeepEP reveal a potential of 0.06ms occupying SMs. Currently, dispatch spends significant time busy-waiting for data. Inserting slow dummy kernels between send/receive operations reduces dispatch time to 0.09ms, and in-flight duration analysis using unit test data suggests further improvements are possible.
While minor enhancements remain—primarily in kernel fusion under "Other Kernels"—SGLang’s decode performance is largely aligned with DeepSeek’s, with prefill optimization as the next focus.
Ablation Study: Two-batch Overlap
Impact of Batch Size and Attention Time
This section investigates TBO performance across varying batch sizes and simulated MTP scenarios.
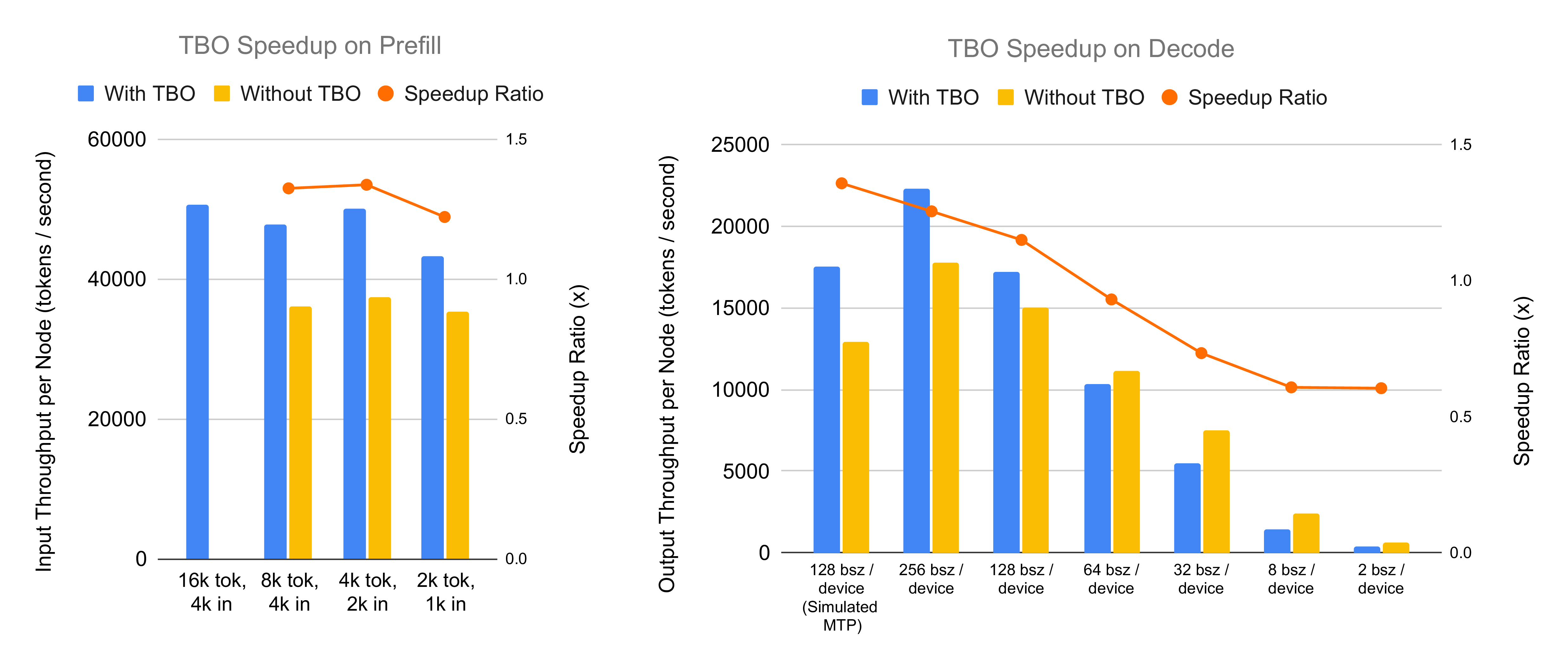
TBO delivers two significant benefits in the prefill phase, as evidenced by throughput comparisons and memory usage optimizations:
- Support for Larger Batch Sizes: In the vanilla configuration, each device processes up to 8,192 tokens before encountering out-of-memory (OOM) errors at 16,384 tokens. TBO mitigates this by optimizing memory usage for input tokens, enabling inference with batches as large as 16,384 tokens per device. This further boosts performance to 40.5% increase when comparing the TBO flag with all other configurations made optimal.
- Enhanced Throughput: By overlapping computation (e.g., attention and MLP phases) with communication (e.g., DeepEP Combine and Dispatch), TBO achieves a 27% to 35% throughput increase compared to the vanilla setup, even when processing the same token count per device.
TBO’s impact in the decode phase varies by scenario, with performance tied to batch size and attention processing time:
- Real Test Cases: Speedup in practical scenarios is contingent on batch size exceeding a threshold between 64 and 128 tokens. Below this, TBO yields minimal or negative gains (e.g., -27% at 32 tokens/device), as small decode batch sizes hinder kernel efficiency. The speedup reaches 25.5% at 256 tokens with a performance of 22,310 tokens per second.
- Simulated MTP Scenario: TBO provides the most substantial speedup in simulated MTP cases when processing 128 requests to generate 256 tokens per decode step. This is due to prolonged attention processing time, which aligns computation (e.g., DP Attention layers) with DeepEP communication overhead (e.g., combine and dispatch steps). The evaluation shows a 35% speedup at 128 sequences/device, with throughput 17,552 tokens per second compared to 12,929 without TBO.
Detail Breakdown
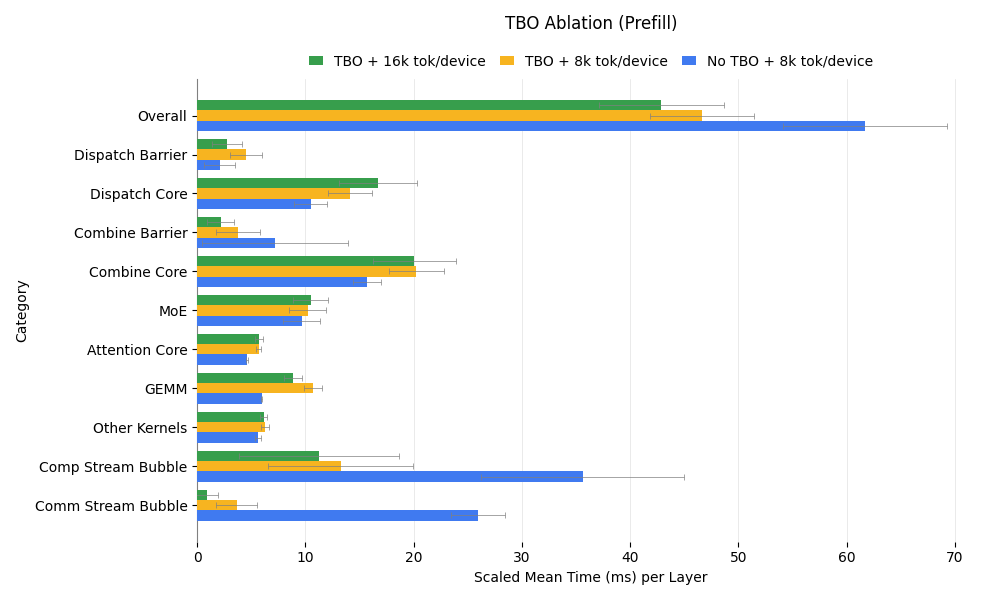
We evaluated three prefill scenarios: TBO with 16k tokens per batch, TBO with 8k tokens, and no-TBO with 8k tokens. The figure below reveals key insights:
- TBO Efficiency: Comparing the 8k cases, TBO improves overall efficiency by overlapping computation and communication, as expected.
- Batch Size Impact: Reducing the batch size from 16k to 8k with TBO results in a slight slowdown, reflecting diminished kernel efficiency with smaller batches.
- Kernel Performance: Interestingly, the no-TBO 8k case outperforms the TBO 16k case in per-kernel speed, despite both having an effective batch size of 8k for kernels. This may stem from reduced streaming multiprocessors (SMs) with TBO, potential noisy neighbor effects during overlap, or kernel incompatibility between computation and communication. These findings suggest future optimization directions for SGLang.
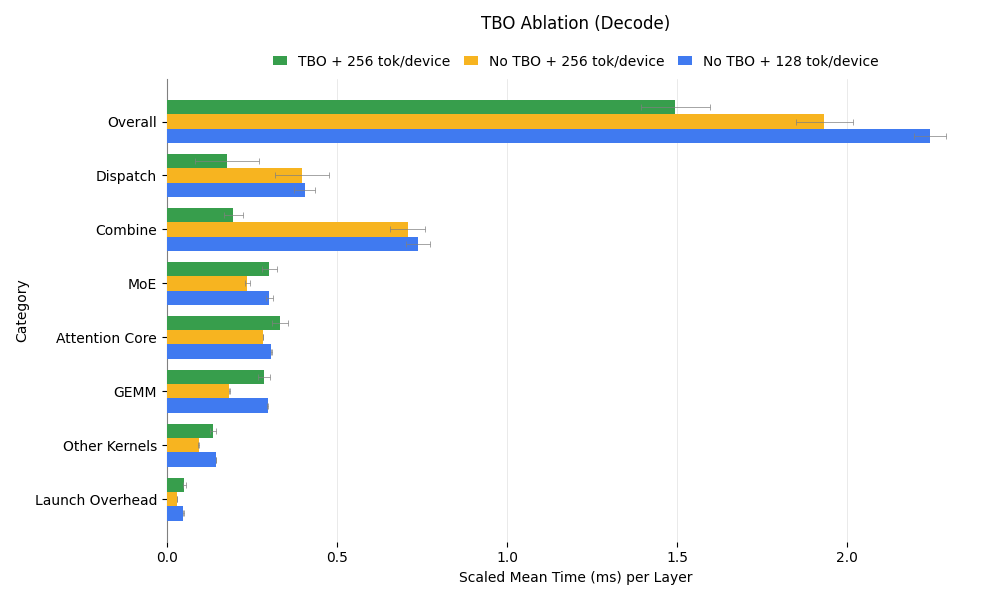
For the decode phase, we analyzed three configurations: TBO with a batch size of 256, no-TBO with 256, and no-TBO with 128. The time breakdown is shown below:
- TBO vs. No-TBO (Batch Size 256): Without TBO, communication time increases significantly due to the lack of overlap. However, computation kernels, particularly GEMM, benefit from a larger effective batch size, resulting in faster execution.
- TBO (256) vs. No-TBO (128): Comparing cases with the same kernel batch size, only non-overlapped communication slows down in the no-TBO setup, while computation remains consistent. Unlike prefill, decode communication kernels either fully utilize SMs (during send/receive) or none (during inflight waiting), avoiding resource contention with computation kernels.
Ablation Study: EPLB
This section evaluates the impact of the EPLB on system performance through overall throughput analysis and detailed case studies. Given EPLB's sensitivity to workload distribution and distribution shifts in production environments, we focus on qualitative and generalizable insights rather than real-world performance, which requires production data.
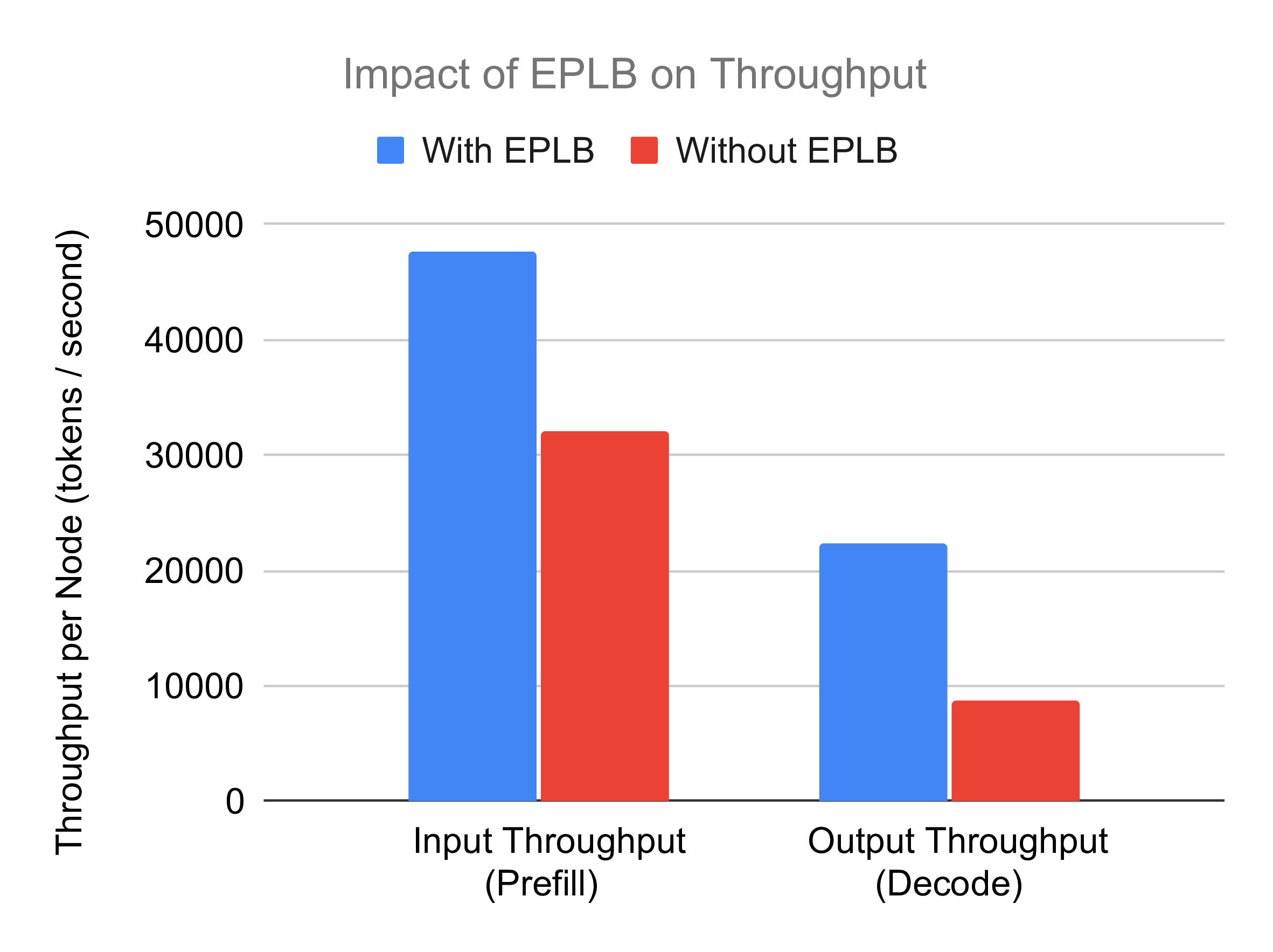
Overall Results
The figure below illustrates EPLB's effect on throughput in large-scale settings. EPLB delivers a significant speedup of 1.49x (prefill) and 2.54x (decode), as expected, due to its ability to mitigate workload imbalances across GPUs. As the number of ranks scales, imbalances grow, and EPLB effectively addresses this in our large-scale experiments, leading to notable throughput improvements.
Case Study: Workload Imbalance Versus Overall Throughput
To explore the relationship between workload imbalance and throughput, we conducted a case study using a decode experiment with 1800 input tokens, 100 output tokens, and a batch size of 256. Throughput and balancedness (average token count divided by maximum token count across experts) were plotted against decoding steps:
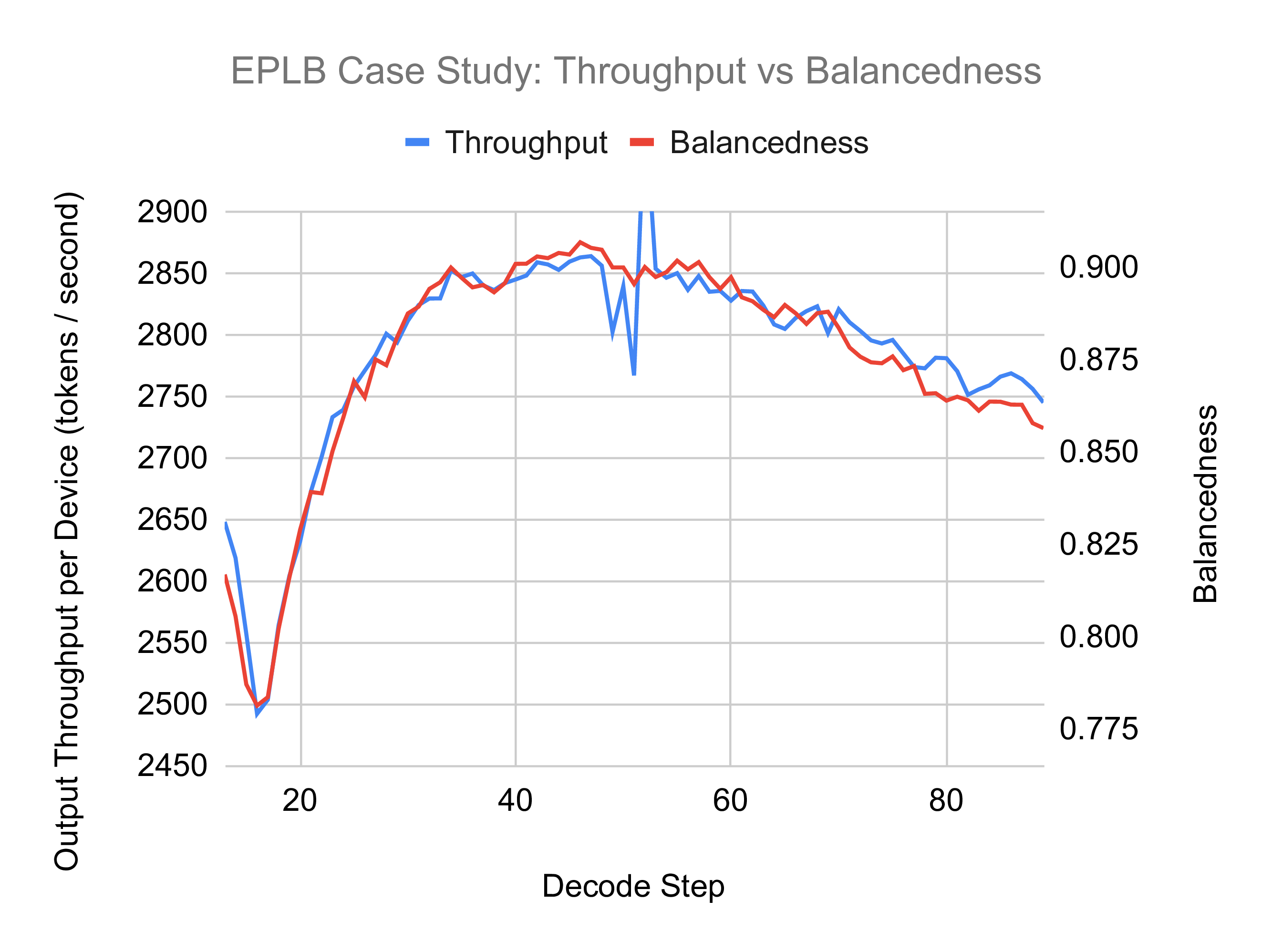
The results reveal a strong correlation between balancedness and throughput, emphasizing the importance of maintaining high balancedness for optimal performance.
Case Study: Expert Distribution Statistics
The following figure presents expert distribution statistics for prefill and decode sample data:
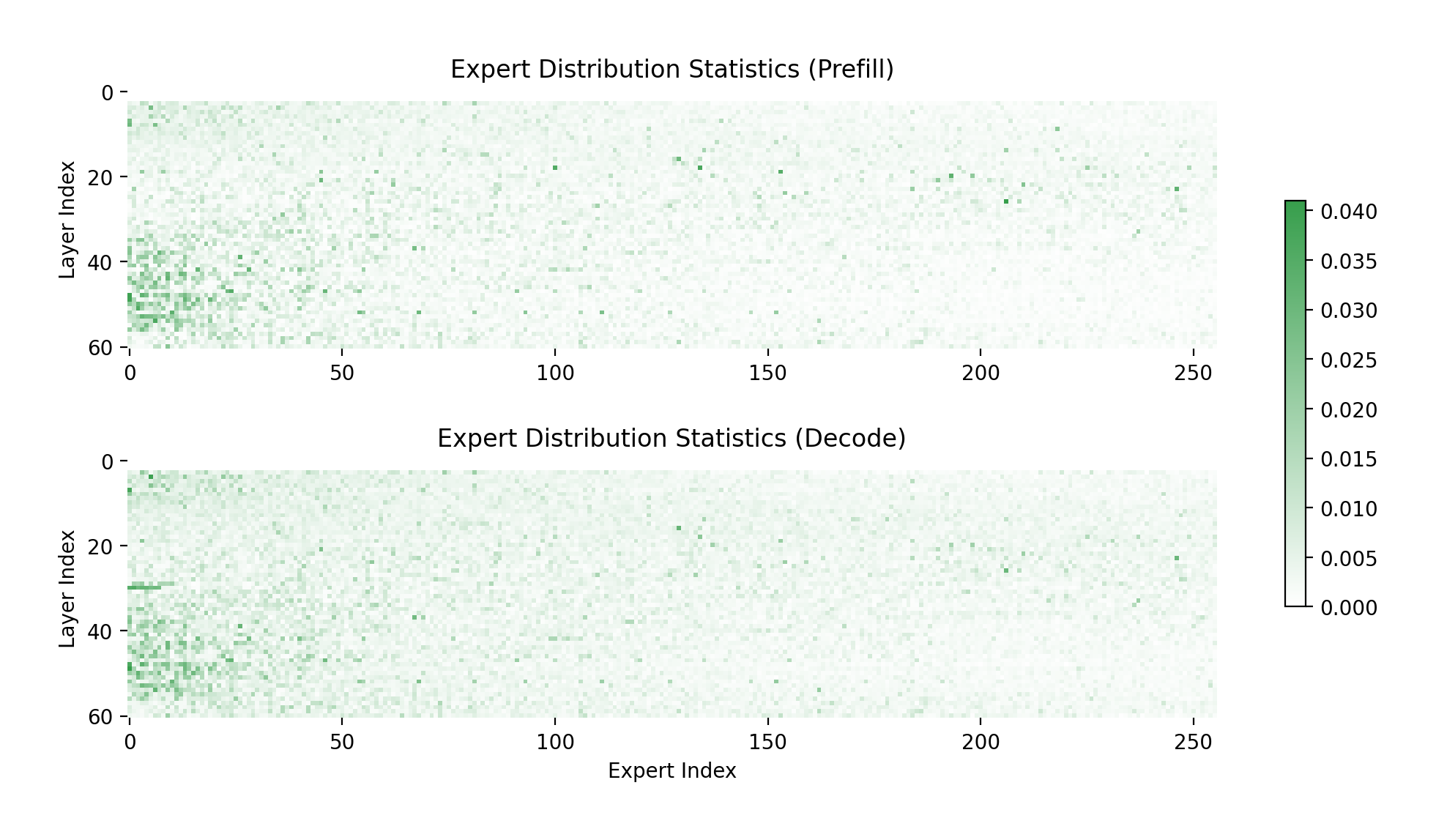
Key observations include:
- Imbalance in Expert Usage: Most experts are infrequently used, while a small subset is heavily utilized, underscoring the inherent imbalance in MoE models.
- Prefill vs. Decode Differences: Although prefill and decode distributions share similarities, notable differences exist. This supports the use of PD disaggregation, which enables distinct expert placements for each phase, optimizing performance.
These findings highlight EPLB's role in addressing workload imbalances and the value of tailoring expert placement to phase-specific demands.
Toolkits
Disposable Tensor
Memory management in PyTorch can be challenging due to persistent object references, especially in GPU-intensive workflows where CUDA memory is a scarce resource. Consider the following example:
def ffn(hidden_state: torch.Tensor, linear1: nn.Linear, linear2: nn.Linear):
intermediate_state = linear1(hidden_state)
del hidden_state # Attempt to free memory, but no effect due to external reference
return linear2(nn.ReLU(intermediate_state))
hidden_state = ffn(hidden_state, linear1, linear2)
In this code, del hidden_state is intended to release the memory occupied by hidden_state after intermediate_state is computed. However, as hidden_state is still referenced outside the function, the del operation has no effect. This increases peak memory usage, risking performance slowdowns or out-of-memory errors.
SGLang addresses this with the DisposableTensor class, a subclass of torch.Tensor which introduces a dispose() method to explicitly and immediately release a tensor’s memory, circumventing Python’s reference counting limitations. Here’s how it works:
def ffn(hidden_state: torch.Tensor, linear1: nn.Linear, linear2: nn.Linear):
intermediate_state = linear1(hidden_state)
hidden_state.dispose() # Immediately releases CUDA memory
return linear2(nn.ReLU(intermediate_state))
# Wrap the tensor in DisposableTensor
hidden_state = DisposableTensor(hidden_state)
hidden_state = ffn(hidden_state, linear1, linear2)
By wrapping hidden_state in a DisposableTensor and calling dispose() when it’s no longer needed, the CUDA memory is freed right away. This ensures that memory is released as soon as the tensor’s role in the computation is complete, reducing peak memory usage and improving overall efficiency.
Expert Workload Extraction and Simulation
SGLang also includes a toolset for analyzing and simulating expert workload distribution in MoE models. This feature enables users to:
- Dump Expert Workload Statistics: Extract either accumulated statistics or per-batch workload data. Accumulated stats support the EPLB manager for real-time optimization, while per-batch data provides granular insights for analysis and simulation.
- Simulate Expert Utilization: Model expert balance across various configurations without requiring costly hardware or repeated trials. For instance, users can gather workload data from a modest setup (e.g., 2x8xH100 or 8xH200) and simulate the performance for a large-scale 22-node deployment.
This simulation capability allows users to evaluate how factors like rebalancing frequency, node count, or batch size impact system performance. It’s a cost-effective way to fine-tune configurations before scaling up.
Limitations and Future Work
While our implementation of SGLang for DeepSeek-V3 inference demonstrates significant throughput improvements, several limitations and areas for future enhancement remain:
- Latency Optimization: The current focus on throughput leaves Time to First Token (TTFT) at 2–5 seconds and Inter-Token Latency (ITL) at approximately 100ms, requiring further optimizations for real-time use cases.
- Sequence Length Constraints: Limited to shorter sequences due to the use of 96 GPUs. Expanding GPU resources would support longer sequences, essential for specific applications.
- Multi-Token Prediction (MTP) Integration: SGLang supports MTP but lacks full integration with DP attention, reducing efficiency in mixed parallelism configurations.
- EPLB Distribution: The experiments in this blog utilizes in-distribution data for Expert Parallelism Load Balancer (EPLB), which may not reflect real-world variability. Future work should experiment performances when having distribution shifts.
- Flexible Tensor Parallelism (TP) Sizes: For DeepSeek-V3, memory-optimal TP sizes for dense FFNs are small but larger than 1. Currently, SGLang only supports pure TP or DP, leading to suboptimal memory use. Flexible TP options are needed.
- Blackwell Support: Currently, our implementation supports only the NVIDIA Hopper architecture. We are actively working to extend compatibility to the next-generation Blackwell architecture. If you are interested in supporting or sponsoring this development, welcome to contact lmsys.org@gmail.com.
Conclusion
By leveraging PD disaggregation, EP, and a carefully crafted parallelism design, we’ve reproduced DeepSeek’s inference framework in SGLang with exceptional performance. Our open-source efforts—achieving 52.3k input tokens per second and 22.3k output tokens per second—demonstrate SGLang’s power for large-scale LLM inference. We invite the community to explore, replicate, and extend this work to push the boundaries of efficient AI deployment.
Acknowledgment
We would like to express our heartfelt gratitude to the following teams and collaborators:
- SGLang Core Team and Community Contributors — Jingyi Chen, Cheng Wan, Liangsheng Yin, Baizhou Zhang, Ke Bao, Jiexin Liang, Xiaoyu Zhang, Yanbo Yang, Fan Yin, Chao Wang, Laixin Xie, Runkai Tao, Yuhong Guo, Kaihong Zhang, Lei Yu, Yu-Hsuan Tseng, Qilin Tian, Peng Zhang, Yi Zhang, Yineng Zhang, Byron Hsu, and many others.
- Atlas Cloud Team — Jerry Tang, Wei Xu, Simon Xue, Harry He, Eva Ma, and colleagues — for providing a 96-device NVIDIA H100 cluster and offering responsive engineering support.
- NVIDIA Solution Architect Team — Xuting Zhou, Jinyan Chen, and colleagues — for their work on the seamless integration of expert parallelism.
- NVIDIA Enterprise Product Team — Trevor Morris, Elfie Guo, Kaixi Hou, Kushan Ahmadian, and colleagues — for optimizing the DeepSeek R1 kernels.
- LinkedIn Team — Biao He, Qingquan Song, Chunan Zeng, Yun Dai, Yubo Wang, and colleagues — for optimizing the Flash-Attention 3 backend.
- Mooncake Team — Shangming Cai, Teng Ma, Mingxing Zhang, and colleagues — for their collaboration on PD disaggregation in SGLang.
- FlashInfer Team — Zihao Ye, Yong Wu, Yaxing Cai — for additional DeepSeek R1 kernel optimizations.
- Dynamo Team - Kyle Kranen, Vikram Sharma Mailthody, and colleagues - for extra support on PD disaggregation in SGLang.
Thank you all for your invaluable support and collaboration.
Appendix
Related PRs: #1970 #2925 #4068 #4165 #4232 #4390 #4435 #4521 #4654 #4767 #4770 #4836 #4880 #4957 #5068 #5085 #5295 #5415 #5432 #5435 #5530 #5558 #5561 #5626 #5657 #5805 #5819 #5890 DeepEP#142