Cost Effective Deployment of DeepSeek R1 with Intel® Xeon® 6 CPU on SGLang
The impressive performance of DeepSeek R1 marked a rise of giant Mixture of Experts (MoE) models in Large Language Models (LLM). However, its massive model size and unique architecture have posed new challenges on deployment. The significant memory requirements will normally require 8x or even 16x high-end AI accelerators to deploy.
Intel PyTorch Team contributed to CPU backend for SGLang for the past few months and we proposed a high-performance CPU only solution using 6th generation of Intel® Xeon ® Scalable Processor with only fractional cost. In this blog, we explain the technical details of achieving high efficiency for deploying DeepSeek on a single node with Xeon® 6 CPU.
Highlights
- SGLang now supports native CPU backend on Intel® Xeon® CPUs with Intel® Advanced Matrix Extensions (AMX).
- Support BF16, INT8 and FP8 for both Dense FFNs and Sparse FFNs (MoE).
- Achieve 6-14x speedup for TTFT and 2-4x for TPOT v.s. llama.cpp.
- Achieve 85% memory bandwidth efficiency with highly optimized MoE kernels.
- Multi-Numa Parallelism via Tensor Parallelism (TP).
CPU Optimization Strategy
In this blog, we will explain the technical details of kernel level optimization, including task partition strategy, memory access efficiency and effective utilization of Intel® AMX for highly optimized GEMM implementations. This section focuses on 4 performance hotspots: Extend Attention and Decode Attention which are backends for RadixAttention of SGLang; MoE which contributes to the majority of weights in DeepSeek R1; and FP8 GEMM in which we utilized an emulated approach on existing x86 platform without native FP8 support.
Extend Attention
We implemented a native C++ backend with Intel® AMX based on interface of RadixAttention which consists of two major components: a) Extend Attention that handles prefill phase for Multi-Head Attention (MHA); b) Decode Attention for decoding phase. Taking GPU kernels as a reference, we mapped flash attention algorithm to CPU intrinsics, as illustrated in Fig-1 below:
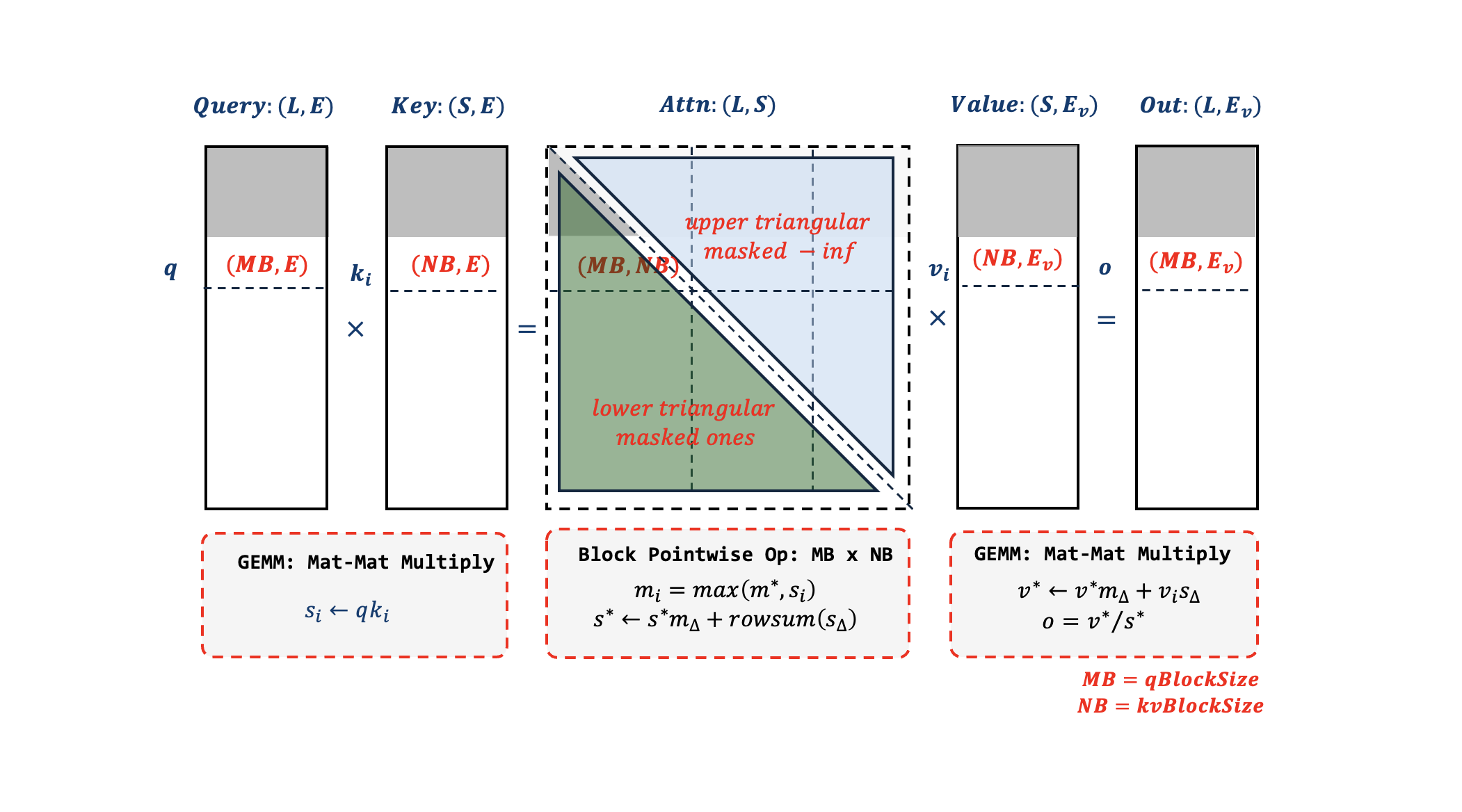
To remove redundant computation, SGLang divides query sequence into two parts:
- prefix – historical sequence in which attention is a rectangle;
- extend – newly added prompt in which attention is a lower triangle.
The CPU kernel exactly maps to Flash Attention V2 algorithm, and we carefully choose the block size for Query sequence and KV sequence to make sure that the immediate values of attention Si and momentums mi, S* fit in L1/L2 cache. The GEMM parts are computed by AMX, and the Block Pointwise OPs are computed by AVX512. Due the fact that AMX does accumulation in FP32 (e.g. A: BF16; B:BF16; C: FP32), we fuse data type conversion with the momentum updates, keeping Si in FP32 which is the result of 1st GEMM and S∆ in BF16 which is the input for 2nd GEMM, reducing rounding error to minimal level while achieving high computation efficiency.
Decode Attention
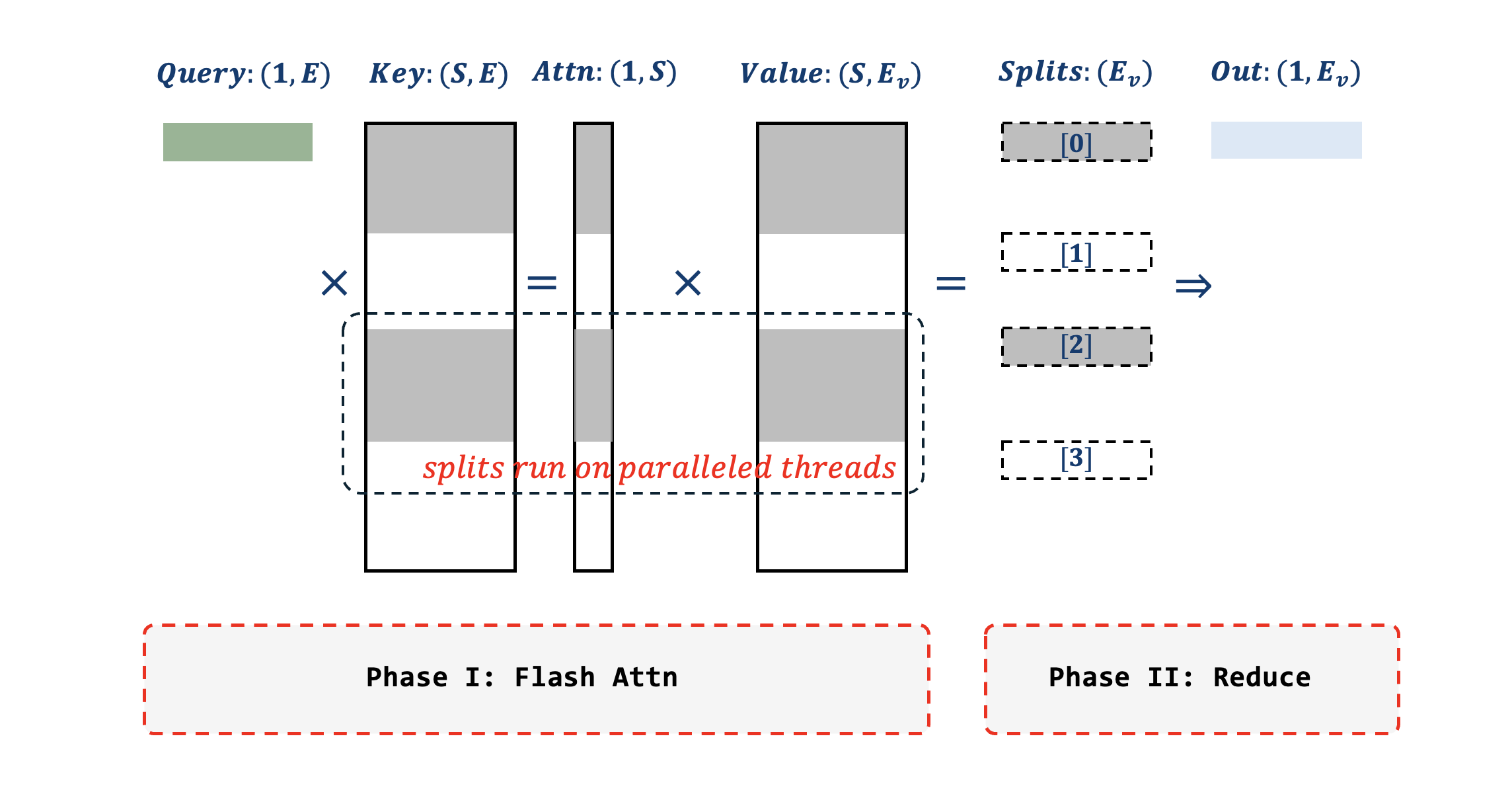
Decoding faces more pressure on parallelization compared with prefilling, due to fact that query sequence length reduced to one. To be specific, in Multi-Head Attention we can parallel the kernel on dimensions of [Batches, Heads, qBlocks], which will be simplified to [1, Heads, 1] for single request decoding, leading to insufficient parallelism. We implemented Flash Decoding algorithm that chunks KV sequence into multiple splits to increase the degree of parallelism, as shown in Fig-2. The implementation takes two phases to complete: first compute attention for each of KV split; then reduce immediate results from all splits to final output.
Multi-head Latent Attention (MLA) Optimization
MLA is one of the core features of the DeepSeek series of models. We provide several critical optimizations on MLA CPU implementation aside from Flash Decoding. We referenced FlashMLA that exploits the fact key and value share the same tensor storage, and pipelines memory load and computation.
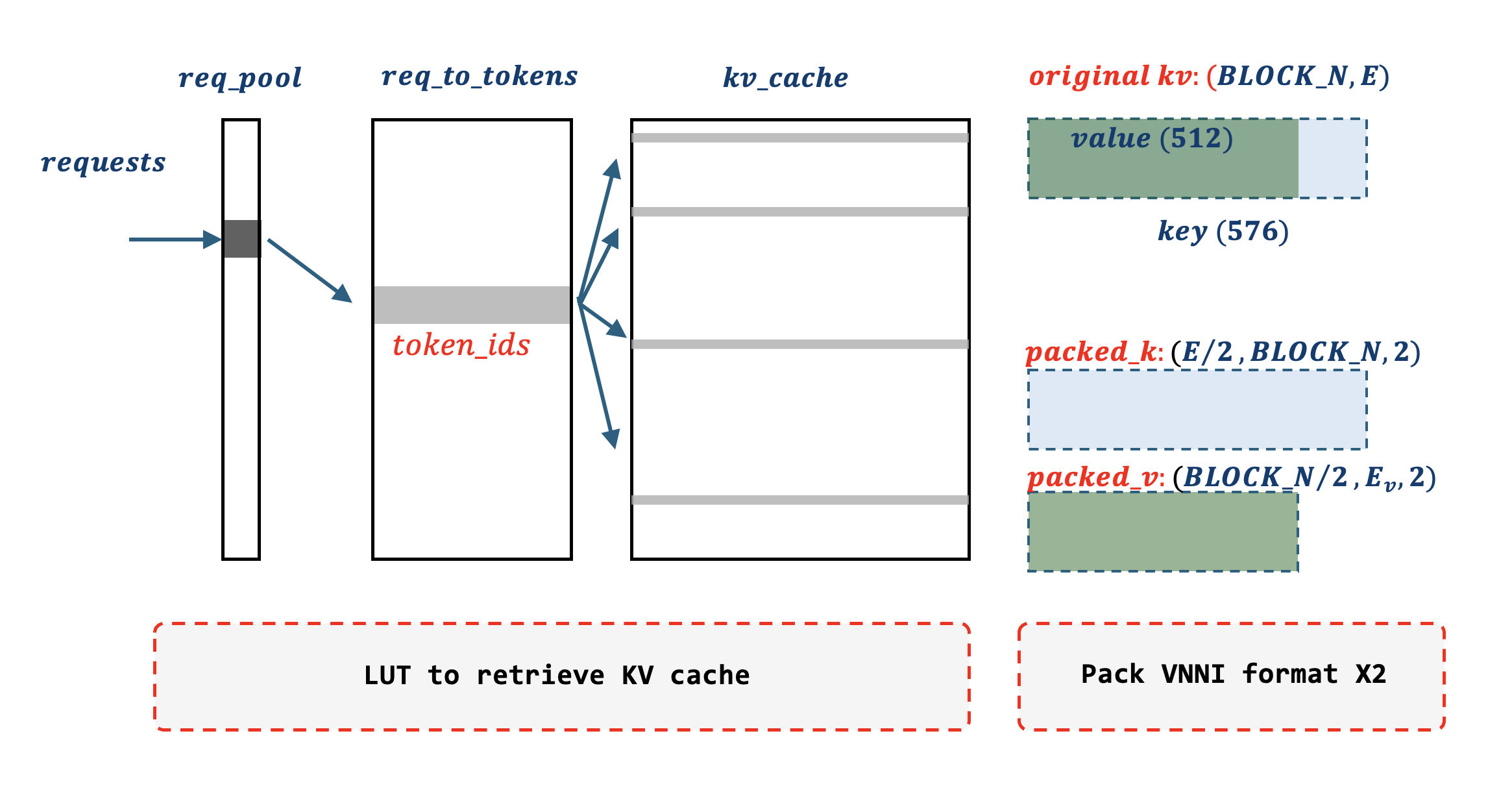
- Load Once Pack Twice: AMX requires tile data in VNNI format, additionally key and value need to be packed differently since the 1st GEMM is NT and the 2nd GEMM is NN. We implemented a fully vectorized packing logic as indicated in Fig-3, KV caches are fetched through 2 LUTs with prefetch; with every 32 lanes loaded (
BLOCK_Nequals 32), simultaneously packed into two thread local immediate buffers, one for key in format of[E/2, BLOCK_N, 2], the other for value in format of[BLOCK_N/2, Ev, 2]. - Head Folding: MLA employs weight absorption in decode phase, which reduces the number of heads to 1 for both key and value. Therefore, we can fold Head dimension into GEMM to increase computation intensity, shown as below. And we balanced parallelism when blocking Head dimension: with a Head dimension of 22 in DeepSeek R1, we use a
BLOCK_SIZE6 for single request and gradually increase to 22 for more requests.
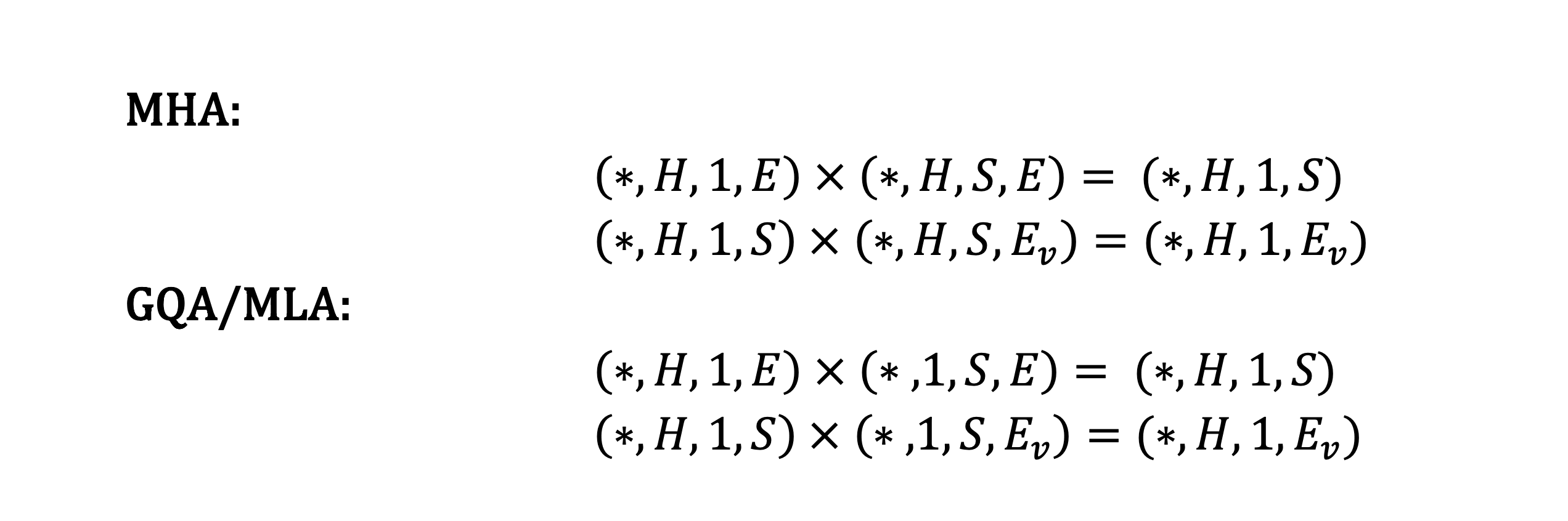
Overall, the kernel level optimizations on MLA provide approximately 1.9x performance speedup against vanilla implementation. Notably, we also fuse the KV buffer setting with decoding kernels, which yields 12% improvement as it removes several inefficiencies from torch: implicit data type conversion for indexing, creating TensorImpl for slicing a tensor, and mapping copy with TensorIterator, etc.
MoE
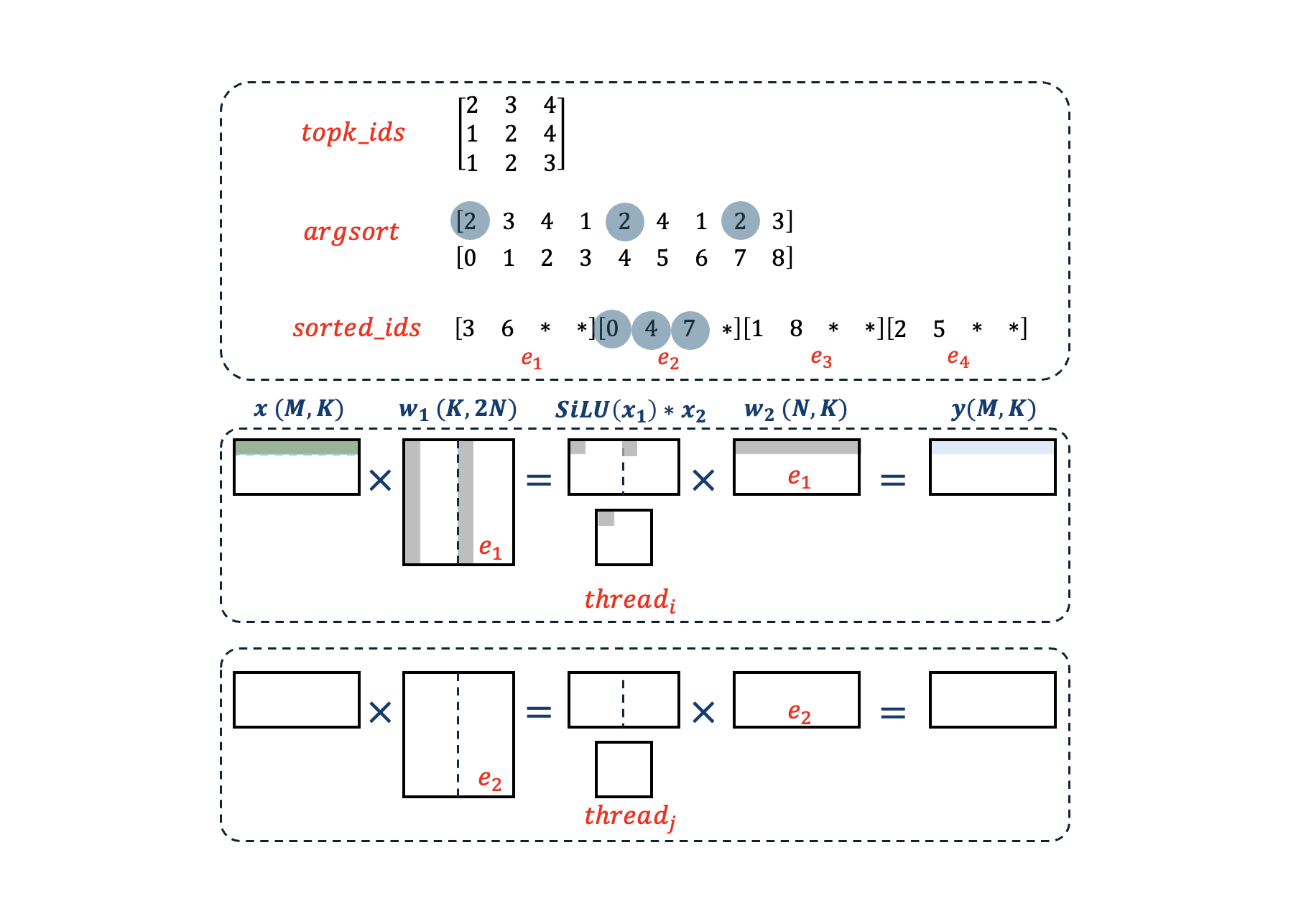
A naïve implementation of MoE with torch would involve looping through experts sequentially, and gather (mask) activations for each of the expert before linear projection. To improve efficiency, a common strategy is to sort the index for activation and chunk them into blocks. We followed the implementation from existing GPU kernels on SGLang, as shown in Fig-4, run argsort on topk_ids and keep indices of activations in sorted_ids according to expert ids.
We made several additional optimizations for the CPU kernel:
- SiLU Fusion: to fuse
up_projandSiLU, we implemented GEMM kernel that operates in the pattern ofA×[B1, B2]=[C1, C2]. WithB1from left half andB2from right half, we can fuseSiLU(C1 ) * C2together, eliminate additional load/store for the output ofup_proj. - Dynamic Quant Fusion: in our INT8 dynamic quant kernels for MoE, we fuse the quantization from BF16 to UINT8 with fetching of activation. We implement both AVX512 and AMX kernels and choose in between according to input configurations. Unlike AMX that supports both U8S8 and S8S8, AVX512-VNNI only supports U8S8 (UNIT8 for A and INT8 for B), we have to make a compromise to align the weights to U8S8 pattern, which indicates a compensation factor of
-128×Bis needed to convert S8S8 to U8S8:A × B=(A + 128) × B - 128 × B.
With these optimizations combined, we achieve 85% memory bandwidth efficiency for INT8 MoE, or 1.45TB/s effective memory bandwidth on Multiplexed Rank Dual Inline Memory Modules (MRDIMMs).
FP8 Inference
DeepSeek R1 employs FP8 hybrid training, which is a great challenge for CPU devices, due to an obvious reason that existing x86 devices don’t have native support for FP8. However, providing FP8 support is essential since it represents the original user experience. We made a couple of optimizations for FP8 MoE and GEMM:
- Weight Only FP8: we followed a weight-only pattern for FP8 MoE/GEMM, in which FP8 is converted to BF16 (same as activation), and make the computation.
- Effective Vectorized Conversion: the data type conversion from FP8 to BF16 is major performance bottleneck on CPU, we experimented with two approaches: a) LUT that gather BF16 data from a 2^8 table; b) intrinsics vectorized conversion. Notably both approaches are equally slow, take 60 to 70 cycles to accomplish, unacceptable for any performance critical scenario. We made a trade-off for b) and skipped the NaN checks and DENORM handling, which reduce the conversion time by half.
- WOQ Aware Cache Blocking: To reduce the data type conversion overhead to minimal level, we take weight unpacking from WOQ in cache blocking during GEMM. To be specific, for each weight blocks assigned to each thread, we visit the weight blocks in a zigzag pattern, and cache the unpacked BF16 blocks in L2, make sure that the slow data type conversion for each block only happens once. We validated on GSM8K and MMLU, our emulated FP8 implementation gave identical accuracy compared to GPU results. And with these optimization tricks above, FP8 implementation achieves approximately 80% to 90% of INT8 implementation.
Multi Numa Parallelism
Non-uniform memory access (NUMA) is a computer memory design used in multiprocessing, commonly seen on server CPUs, where the memory access time depends on the memory location relative to the processor. Under NUMA, a processor can access its own local memory faster than remote memory (memory local to another processor or memory shared between processors). To reduce remote memory access to minimal level, we mapped the Tensor Parallel (TP) for multi-GPU to multi-numa on a CPU server.
We also implemented communication primitives, e.g. all reduce, all gather, based on a shared memory approach, skipping the use of torch.distributed with tedious calling stack. Overall, the communication overhead contributes to merely 3% of end-to-end time.
Evaluation
Our test platform is a state of art dual socket Intel® Xeon® 6980P CPU server, 128 cores each socket. We take another popular LLM tool llama.cpp as the performance baseline to compare against SGLang CPU backend. We evaluated 4 models range from 3B to 671B: DeepSeek-R1-671B, Qwen3-235B, DeepSeek-R1-Distilled-70B and Llama3.2-3B.
Benchmarking notes:
- Socket Setting: We used single socket for Llama3.2-3B and dual sockets for the other three models, as running a 3B small LLM on dual sockets leads to performance downgrade.
- Sub-NUMA Clustering (SNC) Setting: SGLang data are collected with SNC on and llama.cpp data with SNC off, as llama.cpp can’t guarantee local NUMA access with SNC on.
- Multi Instance: As llama.cpp does not implement Multi Numa Parallelism we mentioned above, running 1 instance on dual sockets is even slower than on a single socket. To be fair, we use 2 instances for llama.cpp on dual sockets, 1 for each, and collect metrics of TTFT and TPOT.
- Data Type for Baseline: We compare INT8 with GGUF Q8 format. As llama.cpp does not have FP8 optimized, we also compare FP8 with GGUF Q8.
Table 1: Performance Evaluation of SGLang v.s. llama.cpp
| MODEL | DATA TYPE | SOCKETS | llama.cpp TTFT (ms) | llama.cpp TPOT (ms) | SGLang TTFT (ms) | SGLang TPOT (ms) | Speedup TTFT | Speedup TPOT |
|---|---|---|---|---|---|---|---|---|
| DeepSeek-R1-671B | INT8 | 2 | 24546.76 | 172.01 | 1885.25 | 67.99 | 13.0x | 2.5x |
| DeepSeek-R1-671B | FP8 | 2 | N/A | N/A | 2235.00 | 77.72 | 11.0x | 2.2x |
| Qwen3-235B-A22B | INT8 | 2 | 16806.34 | 214.9 | 1164.29 | 51.84 | 14.4x | 4.1x |
| Qwen3-235B-A22B | FP8 | 2 | N/A | N/A | 1340.62 | 55.88 | 12.5x | 3.8x |
| DeepSeek-R1-Distill-Llama-70B | INT8 | 2 | 20306.85 | 194.97 | 2637.84 | 76.53 | 7.7x | 2.5x |
| Llama-3.2-3B-Instruct | BF16 | 1 | 1659.94 | 55.35 | 268.2 | 16.98 | 6.2x | 3.3x |
(Request=1, INPUT/OUTPUT=1024/1024)
Detail Breakdown
- TTFT achieved a 6-14x performance speedup. MoE models have larger improvements since experts are computed sequentially in llama.cpp and we parallel among experts by realigning expert indices.
- TPOT achieved a 2-4x performance speedup. Since the decoding phase tends to be memory bandwidth bound, the speedup ratio in TPOT is much smaller than TTFT.
- In general, our emulated FP8 implementation already achieved the best efficiency within the hardware capacities.
Limitations and Future Work
While our current work on SGLang CPU backend demonstrates significant throughput improvements, several limitations and areas for future enhancement remain:
- Graph Mode Enabling: Python overhead contributes to a considerable amount of time when the number of concurrent requests is low, we are experimenting with removing the python overhead though graph mode with
torch.compile. The preliminary results indicate an additional 10% improvement in TPOT, the work is still in progress. - Data Parallel MLA: The current Multi Numa Parallelism follows Tensor Parallel pattern which yields duplicate access for KV cache in different ranks, a more efficient solution already exists on GPUs that utilizes DP Attention.
- GPU/CPU Hybrid Execution: KTransformers innovatively uses a hybrid execution pattern for large MoE model inference, in which the MoE layers run on CPU and Attention layers run on GPU. We are experimenting with a similar approach with SGLang and further pipeline the computation stages from heterogeneous hardware.
Summary
In this blog, we explained the technical details of achieving high performance with CPU only deployment based on SGLang. And the work has been fully open-sourced and upstreamed into SGLang main branch. We will continue to bring more performance optimizations for not only CPU backend but also other Intel® platforms.
Acknowledgements
The enabling and optimization of Intel® Xeon® in SGLang is a big milestone as provided new alternative solution of LLM inference in industry, it would not have been possible without the deep collaboration and contributions from the community.
We extend our heartfelt thanks to:
- SGLang Core Team and Community Contributors: Yineng Zhang, Jiexin Liang, Mick, Thien – for sharing their invaluable ideas, meticulously reviewing PRs, providing insightful feedback on RFCs, and solid code contributions.
- KTransformers Team: Mingxing Zhang – for sharing insights and innovative ideas for GPU/CPU hybrid execution.
Also, we, as Intel PyTorch team, pressed forward in the face of adversity to contribute to this taskforce: Mingfei Ma, Chunyuan Wu, Yanbing Jiang, Guobing Chen, Beilei Zheng, Jianan Gu, Zaili Wang, Hengyu Meng, Weiwen Xia, E Cao, Mingxu Zhang, Diwei Sun.
Appendix
Related RFCs and PRs
#2807, #5150, #6216, #6339, #6404, #6405, #6408, #6419, #6452, #6456, #6458, #6493, #6549, #6614, #6641, #6657, #6769, #6770, #6771, #6833, #7390, #7462, #7486, #7647, #7818, #7838, #7885.
Install SGLang with CPU Backend
# Clone the SGLang repository
git clone https://github.com/sgl-project/sglang.git
cd sglang/docker
# Build the docker image
docker build -t sglang-cpu:main -f Dockerfile.xeon .
# Initiate a docker container
docker run \
-it \
--privileged \
--ipc=host \
--network=host \
-v /dev/shm:/dev/shm \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 30000:30000 \
-e "HF_TOKEN=<secret>" \
sglang-cpu:main /bin/bash
Run SGLang with CPU backend
# Launch_server cmd:
# DeepSeek-R1-671B INT8:
SGLANG_CPU_OMP_THREADS_BIND='0-42|43-85|86-127|128-170|171-213|214-255' python3 -m sglang.launch_server --model meituan/DeepSeek-R1-Channel-INT8 --trust-remote-code --device cpu --disable-overlap-schedule --quantization w8a8_int8 --disable-radix-cache --tp 6 --mem-fraction-static 0.8 --max-total-tokens 63356
# DeepSeek-R1-671B FP8:
SGLANG_CPU_OMP_THREADS_BIND='0-42|43-85|86-127|128-170|171-213|214-255' python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1 --trust-remote-code --device cpu --disable-overlap-schedule --disable-radix-cache --tp 6 --mem-fraction-static 0.8 --max-total-tokens 63356
# Qwen3-235B-A22B-INT8:
SGLANG_CPU_OMP_THREADS_BIND='0-42|43-85|86-127|128-170|171-213|214-255' python3 -m sglang.launch_server --model Qwen3-235B-A22B-INT8 --trust-remote-code --device cpu --disable-overlap-schedule --quantization w8a8_int8 --disable-radix-cache --tp 6 --mem-fraction-static 0.8 --max-total-tokens 63356
# Qwen3-235B-A22B-FP8:
SGLANG_CPU_OMP_THREADS_BIND='0-42|43-85|86-127|128-170|171-213|214-255' python3 -m sglang.launch_server --model Qwen/Qwen3-235B-A22B-FP8 --trust-remote-code --device cpu --disable-overlap-schedule --disable-radix-cache --tp 6 --mem-fraction-static 0.8 --max-total-tokens 63356
# RedHatAI--DeepSeek-R1-Distill-Llama-70B-quantized.w8a8:
SGLANG_CPU_OMP_THREADS_BIND='0-42|43-85|86-127|128-170|171-213|214-255' python3 -m sglang.launch_server --model RedHatAI/DeepSeek-R1-Distill-Llama-70B-quantized.w8a8 --trust-remote-code --device cpu --disable-overlap-schedule --quantization w8a8_int8 --disable-radix-cache --tp 6 --mem-fraction-static 0.8 --max-total-tokens 63356
# meta-llama--Llama-3.2-3B-Instruct:
SGLANG_CPU_OMP_THREADS_BIND='0-42|43-85|86-127' python3 -m sglang.launch_server --model meta-llama/Llama-3.2-3B-Instruct --trust-remote-code --device cpu --disable-overlap-schedule --disable-radix-cache --tp 3 --mem-fraction-static 0.8 --max-total-tokens 63356
# Serving cmd:
python3 -m sglang.bench_serving --dataset-path ShareGPT_V3_unfiltered_cleaned_split.json --dataset-name random --random-input 1024 --random-output 1024 --num-prompts 1 --request-rate inf --random-range-ratio 1.0 --max-concurrency 1 --host 127.0.0.1 --port 3000
[NOTEs]: The current CPU native backend only supports CPUs with Intel® AMX support, slow performance are expected for other x86 platforms.
Product and Performance Information
Measurement on Intel(R) Xeon(R) 6980P, HT On, Turbo On, NUMA 6, Integrated Accelerators Available [used]: DLB [8], DSA [8], IAA[8], QAT[on CPU, 8], Total Memory 1536GB (24x64GB DDR5 12800 MT/s [8800 MT/s]), BIOS BHSDCRB1.IPC.3544.D02.2410010029, microcode 0x11000314, CentOS Stream 9 Test by Intel on July 7th 2025.
Notices and Disclaimers
Performance varies by use, configuration and other factors. Learn more on the Performance Index site. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation. Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.