How to support new VLMs into SGLang: A Case Study with NVILA
The world of LLMs is evolving at a remarkable pace, with Visual Language Models (VLMs) at the forefront of this revolution. These models power applications that can understand and reason about both images and text. There are tons of new VLM models emerging daily, and we want to integrate them into SGLang to leverage its high-speed throughput. Today, we’ll provide a step-by-step walkthrough for integrating new VLMs into the SGLang ecosystem, using the recent NVILA model as a real-world case study.
Accelerating the NVILA Visual Language Model with SGLang
The benchmarks below compare the original VILA implementation against SGLang with different levels of concurrency
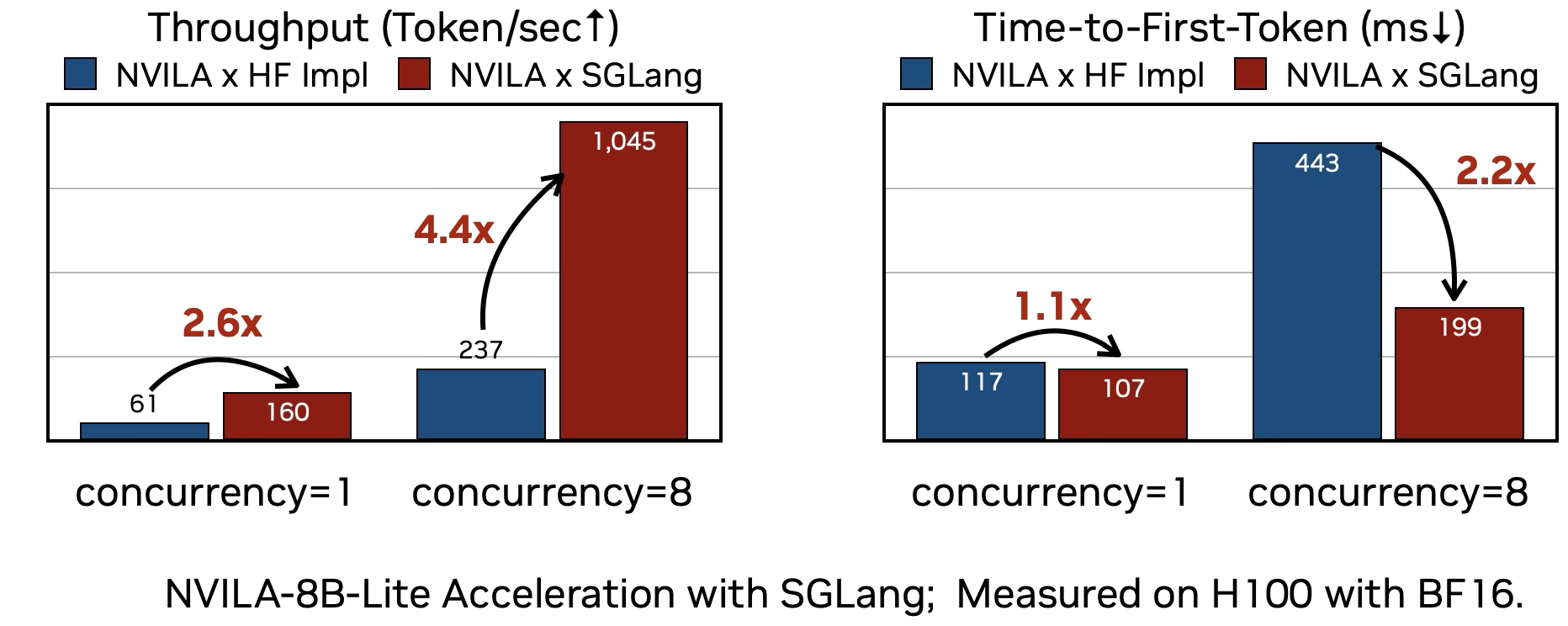
In real world VLM development, we focus on two important metrics to evaluate a serving systems’ performance: Throughput (Token per Second, TPS) and and Time to First Token (TTFT).
- For TPS, higher throughput means the system can generate more tokens simultaneously . SGLang's
RadixAttentionallows for efficient batching of requests, dramatically increasing the number of tokens generated per second. With a concurrency of 8, SGLang achieves over 4.4x higher throughput. - For TTFT, a lower value means users get a faster response to receive the first token. SGLang's memory optimizations and efficient kernel implementations significantly reduce prefill latency. The benchmark shows SGLang responses up to 2.2x faster when concurrency is 8.
These performance gains make SGLang an excellent choice for deploying demanding VLMs like NVILA in production environments, and now can be easily deployed for sglang version ≥ 0.4.8
python3 -m sglang.launch_server \
--model-path Efficient-Large-Model/NVILA-Lite-2B-hf-0626 \
--host 0.0.0.0 --port 30000 --trust-remote-code \
--attention-backend fa3
The Big Picture: How VLMs like NVILA Work
Before diving into code, it helps to understand what is happening under the hood. Most Vision–Language Models (llava-based) share a three-component architecture:
- Vision encoder – a convolutional network or, more commonly, a Vision Transformer (ViT) that converts pixels into a sequence of visual tokens.
- Projector – a lightweight adapter (often an MLP) that aligns those tokens with the embedding space of a pretrained language model.
- Token processor – the language model itself, which mixes visual and textual tokens and autoregressively generates the answer.
NVILA follows the paradigm while pushing the efficiency frontier through its scale-then-compress strategy. It first scales the spatial and temporal resolution so the vision tower sees high-fidelity images or long videos, then compresses the resulting token stream so the language model only attends to a handful of high-information tokens:
- High-resolution SigLIP vision tower captures fine-grained details from images and multi-frame clips.
- Spatial token pooling reduces dense patches to a much smaller grid, preserving text and structure while cutting quadratic attention cost.
- Temporal pooling keeps just the most informative frames, so video inputs add only a few extra tokens.
- Two-layer MLP projector maps the compressed visual embeddings into LLM’s embedding space.
- FP8 training, dataset pruning, and memory-efficient fine-tuning trim training cost by up to 5× and deliver sub-second prefilling on a single 4090 GPU.

NVILA Architecture
This blueprint is generic enough to cover most modern VLMs, yet the compression blocks highlighted in green are what make NVILA both accurate and fast at scale.
Supporting New Models in SGLang
SGLang has a streamlined process for adding new models, which centers on creating a single model definition file that utilizes SGLang’s core components. The key is to replace standard Hugging Face components with their SGLang-optimized counterparts. For VLMs, this involves a few steps.
Step 1: Register the Model as Multimodal
First, SGLang needs to identify your model as multimodal. This is handled in sglang/srt/configs/model_config.py. SGLang determines this by checking if the model’s architecture class name is present in the multimodal_model_archs list.
For NVILA, we add "VILAForConditionalGeneration" to this list. This tells SGLang that any model with this architecture should be treated as a multimodal model.
# python/sglang/srt/configs/model_config.py
# ... existing code ...
multimodal_model_archs = [
# ... existing code ...
"VILAForConditionalGeneration",
]
# ... existing code ...
Step 2: Register a New Chat Template
VLMs often require specific chat templates to handle prompts containing both images and text. SGLang allows you to either define a new template or, more conveniently, match your model to an existing one.
For NVILA, which uses a format similar to ChatML, we can reuse the existing chatml conversation template. To associate our model with this template, we register a matching function in python/sglang/srt/conversation.py. This function, match_vila, inspects the model path and returns "chatml" if it finds a match, telling SGLang to apply the ChatML format for NVILA models.
# python/sglang/srt/conversation.py
# ... existing code ...
@register_conv_template_matching_function
def match_vila(model_path: str):
# ... existing code ...
if re.search(r"vila", model_path, re.IGNORECASE):
return "chatml"
This registration instructs SGLang on how to format the input string and where to expect image data.
To make this concrete, let’s examine the template structure that chatml provides and how it aligns with NVILA’s needs.
Understanding the ChatML Template for NVILA
The ChatML format, which NVILA uses, employs special tokens to structure the conversation. For a multimodal prompt, the template ensures that both text and images are correctly placed.
A typical conversation is a sequence of messages, each with a role (system, user, or assistant) and content. Here’s how a user’s query with an image is formatted:
Example User Message:
{
"role": "user",
"content": [
{ "type": "text", "text": "What is in this image?" },
{ "type": "image" }
]
}
Resulting Prompt String:
The template processor converts this into a single string for the model:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
What is in this image?<image><|im_end|>
<|im_start|>assistant
Here’s a breakdown of the components:
<|im_start|>{role}and<|im_end|>: These tokens define the boundaries of each message.- A default system prompt is automatically added if not provided.
- Text content is included as-is.
- Image content is replaced with a special
<image>placeholder token.
By matching NVILA to the chatml template, SGLang automatically handles this formatting. The engine knows to replace the <image> placeholder with the actual image features during processing, a process we will cover in Step 3.
If your model requires a completely new chat template, you can define it directly in the same file. For example, if NVILA had used a unique format, we would create a new conversation template:
# python/sglang/srt/conversation.py
# ... existing code ...
register_conv_template(
Conversation(
name="vila",
system_template="<|im_start|>system\\n{system_message}",
system_message="You are a helpful assistant.",
roles=("<|im_start|>user", "<|im_start|>assistant"),
sep_style=SeparatorStyle.CHATML,
sep="<|im_end|>",
stop_str=["<|endoftext|>", "<|im_end|>"],
)
)
Step 3: Building the Multimodal Data Processor
The data processor is the heart of the multimodal integration. It acts as the bridge that takes a user’s raw input—a mix of text and images—and meticulously prepares it for the model. For our NVILA integration, we’ll create a VILAMultimodalProcessor in python/sglang/srt/managers/multimodal_processors/vila.py. See here for the full diff.
This class inherits from SGLang’s BaseMultimodalProcessor, and its main workhorse is the process_mm_data_async method. Let’s build this method step-by-step to see how it transforms raw data into a model-ready format.
The Processor’s Skeleton
First define the class. A crucial component is the models class attribute, which links the processor to its corresponding SGLang model class. This registration allows SGLang to to recognize the associated processor of the model when loading VILAForConditionalGeneration. The __init__ method is also updated to cache special token IDs like image_token_id directly from the model's configuration. The processor's main method, process_mm_data_async, then takes the raw request details and returns the processed data that the SGLang engine can understand.
# python/sglang/srt/multimodal/processors/vila.py
# ... imports ...
class VILAMultimodalProcessor(BaseMultimodalProcessor):
models: List[Type[nn.Module]] = [VILAForConditionalGeneration]
# This holds the Hugging Face processor
_processor: VILAProcessor
def __init__(
self,
hf_config: PretrainedConfig,
server_args: ServerArgs,
_processor: VILAProcessor,
) -> None:
super().__init__(hf_config, server_args, _processor)
# Store special token IDs
self.IM_TOKEN_ID = hf_config.image_token_id
self.VIDEO_TOKEN_ID = hf_config.video_token_id
async def process_mm_data_async(
self,
image_data: Optional[ImageDataItem | List[ImageDataItem]],
input_text: str | List[int],
request_obj: GenerateReqInput | EmbeddingReqInput,
max_req_input_len: int,
**kwargs,
) -> Optional[Dict[str, Any]]:
# ... implementation below ...
From Raw Input to Processed Data
Inside process_mm_data_async, a streamlined pipeline handles the inputs.
- Load and Process: The logic consolidates data handling. We first call
self.load_mm_datafrom the base class to load image files and locate the special<image>tokens in the prompt. This output is then passed toself.process_and_combine_mm_data, a method that encapsulates the logic for tokenizing text, transforming images, and packaging the data. - Assemble the Final Package: This process directly produces the final dictionary for the SGLang engine. This dictionary contains the tokenized
input_ids, the assembledmm_items(which include processed image data and their locations), and explicitly includes theim_token_idandvideo_token_id.
Here’s the complete implementation of process_mm_data_async:
# (Inside VILAMultimodalProcessor)
async def process_mm_data_async(
self,
image_data: Optional[ImageDataItem | List[ImageDataItem]],
input_text: str | List[int],
request_obj: GenerateReqInput | EmbeddingReqInput,
max_req_input_len: int,
**kwargs,
) -> Optional[Dict[str, Any]]:
# Load image data and find special tokens
base_output = self.load_mm_data(
prompt=input_text,
multimodal_tokens=MultimodalSpecialTokens(
image_token=self._processor.tokenizer.image_token
),
max_req_input_len=max_req_input_len,
image_data=image_data,
)
# Process images and text, then combine into final format
mm_items, input_ids = self.process_and_combine_mm_data(base_output)
# Return the complete package for the engine
return {
"input_ids": input_ids.tolist(),
"mm_items": mm_items,
"im_token_id": self.IM_TOKEN_ID,
"video_token_id": self.VIDEO_TOKEN_ID,
}
And that’s it! This clean design centralizes the core processing logic, making the processor more maintainable and easier to extend.
Step 4: Create the Core Model Definition
The final major step is to define the model’s main class in a new file, python/sglang/srt/models/vila.py. This involves porting the Hugging Face model by replacing standard layers with SGLang’s high-performance equivalents.
Adapting Attention Mechanisms
To unlock maximum performance, standard attention layers are replaced:
- Language Model Attention: Original
Attentionlayers are replaced with SGLang’sRadixAttention. This is the key to SGLang’s high-performance batching and memory management. - Vision Model Attention:
Attentionlayers in the Vision Transformer (ViT) are replaced with SGLang’sVisionAttentionto manage the vision tower’s KV cache.
NVILA uses Qwen2 as its language model, thus we directly adapt SGLang’s Qwen2ForCausalLM class and do not need to manually replace the attention layers. See the diff here.
Handling Multimodal Inputs with pad_input_ids
The pad_input_ids function is a critical component for handling multimodal inputs in SGLang. Its primary role is to prepare the input token sequence for RadixAttention. It achieves this by replacing placeholder tokens for images (or other modalities) with unique multimodal data hashes. These hashes, or pad_value, allow RadixAttention to correctly associate segments of the input with the corresponding image data, even when processing multiple requests in a single batch. This is essential for efficient multi-user serving.
SGLang provides different padding strategy tool classes to accommodate various ways models represent multimodal inputs. The choice of pattern depends on how the model’s tokenizer and chat template are designed.
Pattern 1: Contiguous Multimodal Tokens
Some models like NVILA and Kimi-VL represent an image with a contiguous block of special tokens (e.g., <image><image>...<image>). For these models, we use MultiModalityDataPaddingPatternMultimodalTokens. The pad_input_ids function signature is generalized to accept mm_inputs, which can contain various modalities. For NVILA, the implementation is straightforward and concise:
# python/sglang/srt/models/vila.py
# ...
def pad_input_ids(
self,
input_ids: List[int],
mm_inputs: MultimodalInputs,
) -> List[int]:
# Use a pattern that finds contiguous blocks of the image token
pattern = MultiModalityDataPaddingPatternMultimodalTokens()
return pattern.pad_input_tokens(input_ids, mm_inputs)
Pattern 2: Token Pairs
Other models like InternVL and MiniCPM-o use a pair of special tokens to mark the start and end of a region where image features should be inserted (e.g., <image>...</image>). In this case, MultiModalityDataPaddingPatternTokenPairs is the correct choice. This pattern identifies the content between the start and end tokens and replaces it with the image’s unique hash.
If a model used this pattern, the implementation would look like this:
# python/sglang/srt/models/some_other_model.py
# ...
def pad_input_ids(
self,
input_ids: List[int],
image_inputs: MultimodalInputs,
) -> List[int]:
# Use a pattern that finds regions enclosed by start/end token pairs
pattern = MultiModalityDataPaddingPatternTokenPairs(
data_token_pairs=[
(self.config.image_start_token_id, self.config.image_end_token_id)
],
)
return pattern.pad_input_tokens(input_ids, image_inputs)
By selecting the appropriate padding pattern, you ensure that SGLang’s engine can correctly interpret the multimodal structure of your model’s input.
Handling Image Features
Once the input sequence is padded, SGLang’s engine must fetch the actual image features to substitute for the placeholder hashes. This is handled by the get_image_feature method. Its job is to take the raw image data (pixel_values) and generate embeddings that can be combined with the text embeddings.
This process for VILA involves a few steps:
- The
pixel_valuesare sent to thevision_tower, which is a pre-trained vision encoder (e.g., a Vision Transformer). This extracts a rich feature representation from the image. - The features are then passed through the
mm_projector, a small network that aligns the vision features with the language model’s embedding space. The resultingimage_embeddingis then ready to be used by the model.
This function is called by mm_utils.general_mm_embed_routine, a utility in SGLang that manages the process of replacing placeholder hashes with these computed image embeddings before feeding them to the main language model.
Here is the implementation in python/sglang/srt/models/vila.py:
# python/sglang/srt/models/vila.py
def get_image_feature(self, mm_input: List[MultimodalDataItem]) -> Tensor:
pixel_values = cast(Tensor, mm_input[0].pixel_values)
vision_tower_output: BaseModelOutputWithPooling = self.vision_tower.__call__(
pixel_values.to(
device=self.vision_tower.device, dtype=self.vision_tower.dtype
),
output_hidden_states=True,
)
mm_projector_input = self._vision_tower_output_to_mm_projector_input(
vision_tower_output
)
image_embedding: Tensor = self.mm_projector.__call__(
mm_projector_input.to(
device=self.mm_projector.device, dtype=self.mm_projector.dtype
)
)
return image_embedding
This modular design ensures that image features are computed and seamlessly integrated into the language model’s input stream.
Defining the forward pass
The forward method is adapted to work with SGLang’s batching strategy. It takes the combined text and images and processes them through the decoder layers using RadixAttention.
# python/sglang/srt/models/vila.py
def forward(
self,
input_ids: Tensor,
positions: Tensor,
forward_batch: ForwardBatch,
get_embedding: bool = False,
) -> LogitsProcessorOutput:
output = mm_utils.general_mm_embed_routine(
input_ids=input_ids,
forward_batch=forward_batch,
language_model=self.llm,
image_data_embedding_func=self.get_image_feature,
get_embedding=get_embedding,
positions=positions,
)
return cast(LogitsProcessorOutput, output)
Implementing load_weights
Because SGLang uses custom-optimized layers, the load_weights function is responsible for carefully mapping and sometimes transforming weights from a Hugging Face checkpoint to fit the new model structure. This process is highly dependent on the model’s implementation in Transformers.
To load weights incrementally, we recommend using the load_weights method on the submodules. For other weights, weight_utils.default_weight_loader can be used.
# python/sglang/srt/models/vila.py
def load_weights(self, weights: Iterable[Tuple[str, Tensor]]) -> None:
params_dict = dict(self.named_parameters())
for name, loaded_weight in weights:
if name.startswith("llm."):
self.llm.load_weights([(name[len("llm.") :], loaded_weight)])
else:
param = params_dict[name]
weight_loader = getattr(
param, "weight_loader", weight_utils.default_weight_loader
)
weight_loader(param, loaded_weight)
Finally, an EntryClass is added at the end of the file to tell the SGLang server which class is the main entry point for the model.
# python/sglang/srt/models/vila.py
# ... model definition ...
# Entry class for the SGLang server
EntryClass = [VILAForConditionalGeneration]
Step 5: Add Integration Tests
No integration is complete without thorough testing. It is a best practice to validate the new model implementation in two key ways. For NVILA, we added a test case in test/srt/test_vision_openai_server_b.py.
Conclusion
Integrating a cutting-edge VLM like NVILA into a high-performance serving engine like SGLang is a detailed yet well-defined process. By replacing key components with SGLang’s optimized versions like RadixAttention, you can serve these powerful models with maximum efficiency and unlock advanced features like multi-user batching.
The key steps are:
- Configuration: Registering the model’s multimodal nature and its chat template.
- Data Handling: Creating a dedicated processor to manage image and text inputs.
- Model Definition: Porting the architecture, replacing standard layers with SGLang’s optimized versions, and correctly handling multimodal inputs.
- Testing: Rigorously verifying the implementation against reference outputs and adding integration tests.
We hope this detailed walkthrough has demystified the process and encourages you to contribute to the exciting open-source development happening at SGLang.
Acknowledgements
We thank all contributors for their efforts in developing and integrating NVILA into SGLang.
NVILA Team: Zijian Zhang, Ligeng Zhu
SGLang Community: Mick Qian, Xinyuan Tong, Qiujiang Chen, Xinpeng Wei, Chenyang Zhao
Further Reading: