Accelerating SGLang with Multiple Token Prediction
TL;DR
SGLang now supports smooth combination of these advanced features: Multiple Token Prediction (MTP), Large-Scale Expert Parallelism (EP), and Prefill-Decode disaggregation. This integration delivers up to 60% higher output throughput through a new decoding paradigm, better parallelism, and more efficient resource utilization without sacrificing generation quality. If you are serving models, e.g., DeepSeek V3, SGLang now supports MTP as a plug-and-play feature, unlocking immediate performance gains. You can find instruction for reproduction here.
SGLang’s inference framework running on NVIDIA GPUs enables AI practitioners to easily deliver inference at scale, empowering end users to “think smart” and harness the reasoning capabilities of state-of-the-art language models at the highest performance.
Introduction
While large language models continue to grow in capability, their token-by-token decoding process remains fundamentally sequential, creating a critical bottleneck for inference throughput. This limitation becomes especially apparent in high-demand applications, where maximizing GPU utilization is crucial for achieving high performance and cost-efficient deployment.
To address this, SGLang brings Multiple Token Prediction (MTP) to the open-source inference ecosystem, an advanced speculative decoding technique that accelerates generation by predicting multiple draft tokens with a lightweight draft model and verifying them in parallel using a single pass of the full model. In our benchmarks, MTP unlocks up to 60% higher output throughput for DeepSeek V3 without any loss in generation quality. With MTP now fully integrated, SGLang continues to push the frontier of open-source LLM serving, offering advanced decoding capabilities previously confined to proprietary systems, and making them accessible and production-ready.
What is Multiple Token Prediction (MTP)?
Traditional autoregressive decoding generates one token at a time, depending on all previous tokens. This serial process limits parallelism and speed.
MTP is a form of speculative decoding technique that accelerates generation by using a lightweight draft model to rapidly propose multiple future tokens, which are then verified in parallel by the full target model in a single pass.
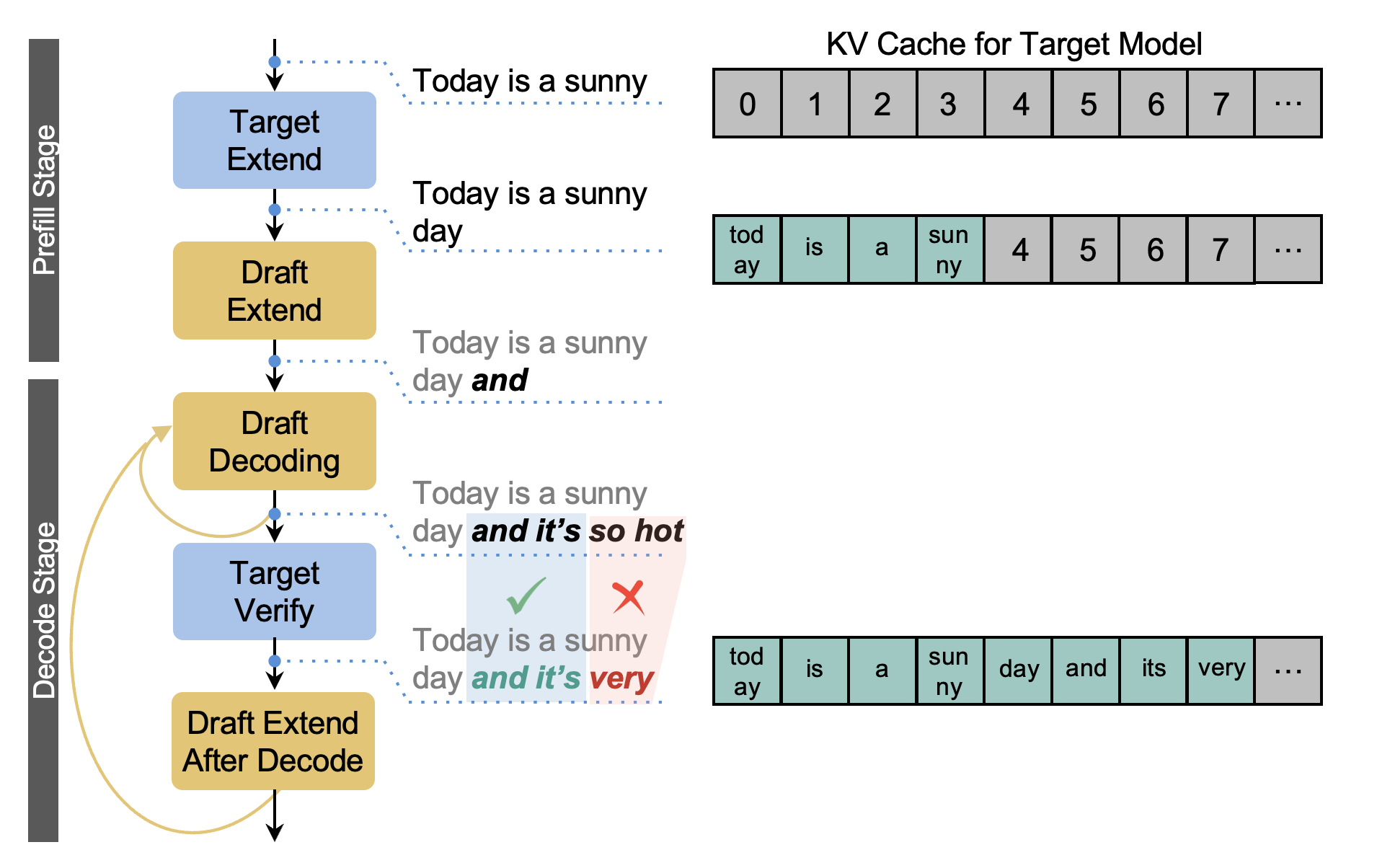
MTP works by dividing the generation into two stages:
-Drafting: The lightweight draft model predicts one or more short sequence candidate(s) of n tokens in a single fast pass. Here we use one sequence candidate as an example.
(1) “Today is a sunny” is the current prefix produced by the target model.
(2) “day” is first generated by the target model's extend/prefill stage.
(3) “and” is the first draft token generated by the draft model's extend/prefill stage.
(4) “it’s so hot” are the three extra draft tokens generated by the draft model decoding iterations; In the example case, n=4 for “and it’s so hot”.
-Verification: The full target model then verifies all n draft tokens in parallel, accepting the longest prefix that matches its own output and resampling the rest if needed.
Let’s walk through an example with n = 4:
- The target model first generates the initial token after the extend/prefill stage:
→ “day” - The draft model then speculates the next token after extend/prefill and 3 more tokens after autoregressive decoding:
→ “and it’s so hot” - The target model verifies the full sequence:
→ it agrees with “and it’s”
→ It rejects “so hot”, and instead resamples “very”
Why MTP is Fast
The key to MTP’s speedup is parallelism. Crucially, the verification step is fully parallelized on GPUs, replacing n sequential decode steps with a single parallel verification pass.
The effectiveness of MTP depends on how many draft tokens are accepted per verification step, a metric known as the acceptance length. For instance, an average acceptance length of 2.4 means that, on average, 2.4 decode steps are skipped every time, resulting in substantial cumulative speedup during long sequences.
MTP does not compromise on generation quality or determinism. Every speculative token is still verified and approved by the same full model, ensuring identical outputs to standard decoding without any approximation or fine-tuning.
This new capability is fully integrated with SGLang’s advanced features, including:
- Data-Parallel Attention (DP Attention)
- Expert Parallelism Load Balancer (EPLB)
- DeepEP MoE
- Two Batch Overlap
- Prefill-Decode (PD) Disaggregation
- CUDA Graph
- Various Attention Backends
Performance Evaluation
We present a comprehensive evaluation of the performance gains enabled by fully integrating MTP into the SGLang serving framework, using the DeepSeek V3 model as the testbed. This analysis includes two case studies designed to highlight improvements under both small-scale and large-scale deployment settings.
Deployment Scenarios and Design Motivation
The small-scale deployment configuration was selected based on production requirements from a high-profile generative AI company that operates a latency-sensitive, developer-facing product. Specifically, the company required a minimum sustained output of 60.4 tokens/sec per rank to meet application-level service-level agreements (SLAs). This requirement guided the configuration used in our first case study. To assess scalability under heavier loads, we also evaluate MTP in a large-scale cluster setup.
Case Study 1: Small-Scale Deployment
In this scenario, we deploy two decoding nodes across a total of 16 H200 GPUs, running 2 concurrent requests per rank with input sequence length of 65,536 tokens and output sequence length of 4,096 tokens. As baseline, we tested the case with no MTP and no overlap scheduling, and the system achieves an output throughput of 51 tokens/sec per rank. Using overlap scheduling alone, a feature introduced in SGLang v0.4, we achieved 60.4 tokens/sec per rank, meeting the production threshold without the need for MTP. When MTP is enabled, the system significantly surpasses this benchmark:
- With a 3-token MTP window and topk=1, the system achieves a throughput of 81.5 tokens/sec per rank, with an average acceptance length of 2.18 tokens.
- With a 4-token MTP window and topk=1, throughput increases to 82.0 tokens/sec per rank, with an average acceptance length of 2.44 tokens.
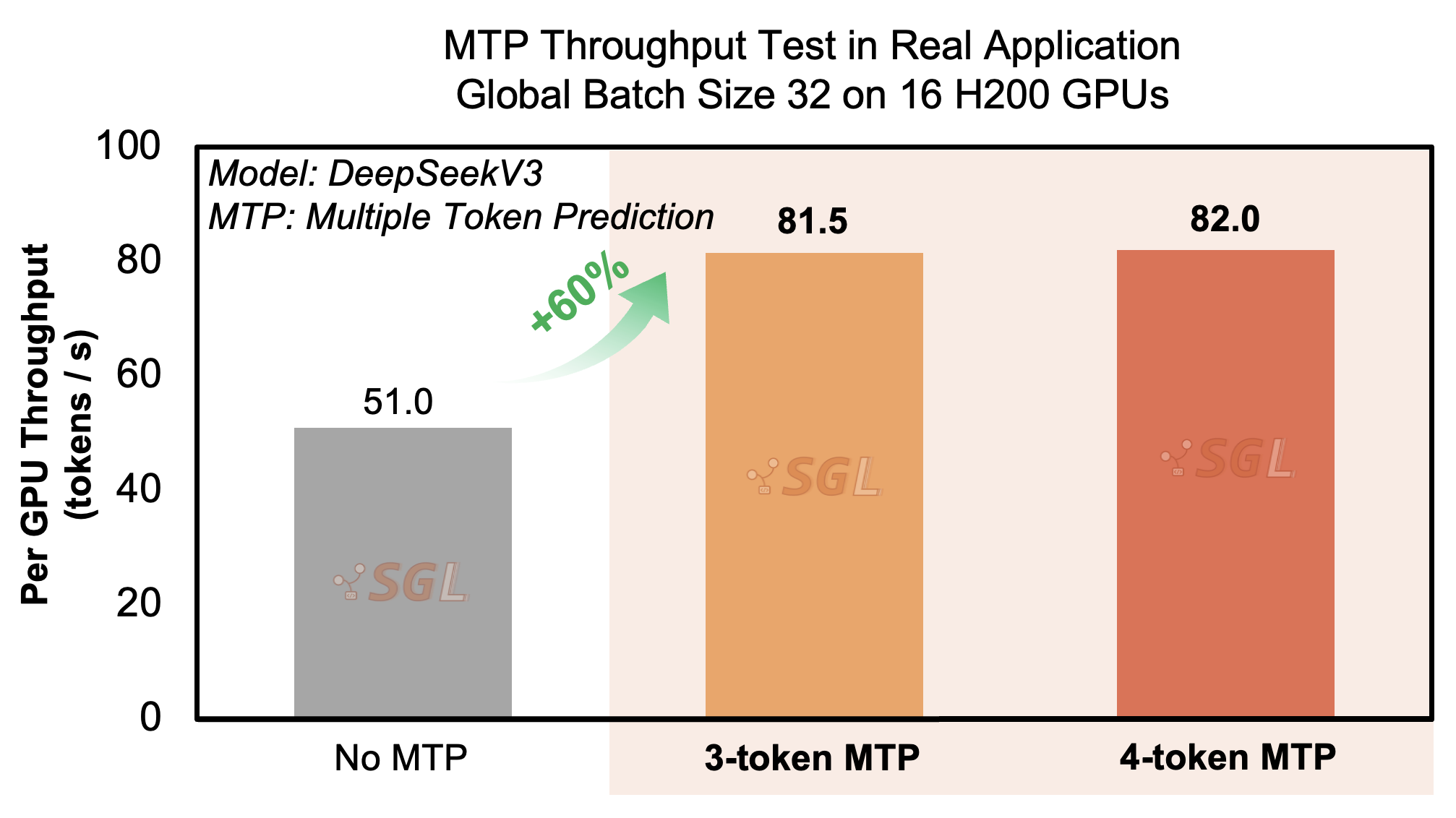
These results represent a +60% improvement in output throughput compared to the baseline (i.e., no overlap scheduling and no MTP). This case demonstrates that MTP yields substantial performance gains even in smaller cluster settings with modest concurrency levels, allowing for scalable performance even within constrained GPU resource budgets.
| Overlap Scheduling | MTP | Throughput (tokens/sec) Per Rank |
|---|---|---|
| ❌ | ❌ | 51.0 (baseline) |
| ✅ | ❌ | 60.4 (+20.4% ↑) |
| ❌ | ✅ 3-token | 81.5 (+59.8% ↑) |
| ❌ | ✅ 4-token | 82.0 (+60.8% ↑) |
Case Study 2: Large-Scale Deployment
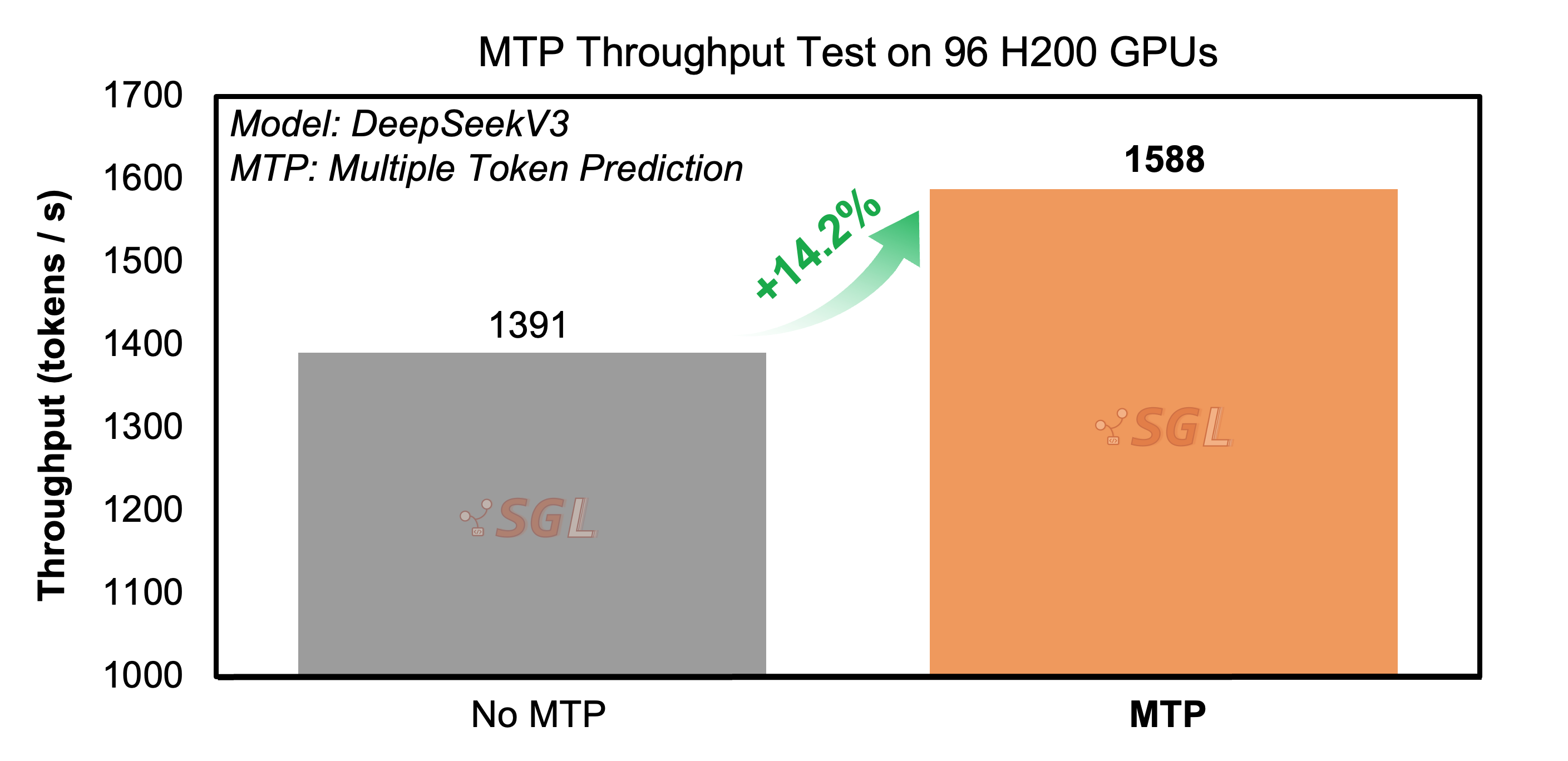
To evaluate scalability as well as demonstrate MTP support with large scale EP and Prefill-Decode disaggregation, we expand to a 16-node cluster comprising 128 H200 GPUs with 4 prefill nodes and 12 decoding nodes, running 128 concurrent requests per rank with input sequence length of 2,000 tokens and output sequence length of 100 tokens. In this high-throughput environment, we configure decoding with topk = 1, step size = 1, and draft_token_num = 2.
When comparing MTP-enabled decoding to the baseline (i.e., no overlap scheduling and no MTP), we observe a +14.2% increase in output throughput, confirming that MTP provides measurable performance gains even at large scale under production-like workloads.
MTP Best Practices
To get started with Multiple Token Prediction in SGLang, enable it in your configuration and set draft_token_num to 2, a balanced, low-risk choice that provides reliable performance gains across most workloads. For setups with available GPU headroom, you can increase draft_token_num to 4 or even larger to further boost throughput, though the returns may taper off depending on how well the system maintains token acceptance rates. On the other hand, if your GPUs are already handling large batches or running near capacity, keeping the draft size at 2 or 3 is generally more efficient and avoids introducing additional load.
You can monitor acceptance rates in logs to fine-tune this parameter over time. If you're seeing average acceptance lengths consistently above 2, there's room to experiment with longer drafts. But if acceptance begins to drop, consider dialing it back to stay within your system’s comfort zone.
Future Work
-Large-Scale Optimization We are continuing to optimize performance for large-scale MTP deployments, focusing on scheduling efficiency and memory bandwidth utilization across multi-node systems.
-Overlap Scheduling Compatibility The current MTP implementation does not yet support overlap scheduling. We anticipate additional performance gains once MTP and overlap scheduling are integrated. Development on this feature is ongoing.
Acknowledgment
We would like to express our heartfelt gratitude to the following teams and collaborators. In particular, we extend our sincere thanks to the NVIDIA DGX Cloud team for providing powerful GPUs and for their exceptional support in ensuring operational excellence:
Eigen AI Team - Jinglei Cheng, Yipin Guo, Zilin Shen, Ryan Hanrui Wang, Wei-Chen Wang and many others.
SGLang Team and Community - Kavio Yu, Ke Bao, Qiaolin Yu, Boxin Zhang, Shangming Cai, Jinfu Deng, Jiaqi Gu, Di Jin, Uill Liu, Junyao Zhang, Yineng Zhang and many others.
xAI Team - Sehoon Kim, Ying Sheng, Lianmin Zheng, Sangbin Cho, Hanming Lu, Byron Hsu, Pranjal Shankhdhar, Cheng Wan and many others.
NVIDIA Team - Pen Chung Li from Enterprise Products, Carl Nygard, Lee Ditiangkin, Nathan Fisher from DGX Cloud and many others.