GLM-4.5 Meets SGLang: Reasoning, Coding, and Agentic Abilities
Today, we are excited to introduce our latest flagship models GLM-4.5 and GLM-4.5-Air, along with their FP8 variants. All models are now available with day-one support on SGLang. GLM-4.5 and GLM-4.5-Air are both powerful models designed to unify reasoning, coding, and agentic capabilities, with 355B total parameters (32B active) and 106B total parameters (12B active) respectively.
Deploying GLM-4.5 with SGLang
We recommend deploying the GLM-4.5 series of models using SGLang for optimal performance. Through close collaboration with the SGLang community, all GLM-4.5 models are fully supported on SGLang starting from day one.
Basic Usage
Install SGLang
pip install --upgrade pip
pip install "sglang[all]>=0.4.9.post6"
355B Model
python3 -m sglang.launch_server --model zai-org/GLM-4.5 --tp 8
106B Model
python3 -m sglang.launch_server --model zai-org/GLM-4.5-Air --tp 8
355B FP8 Quantized Model
python3 -m sglang.launch_server --model zai-org/GLM-4.5-FP8 --tp 8
106B FP8 Quantized Model
python3 -m sglang.launch_server --model zai-org/GLM-4.5-Air-FP8 --tp 4
Tool Call
Append the following parameter to the command:
--tool-call-parser glm45
Reasoning Parser
Append the following parameter to the command:
--reasoning-parser glm45
Speculative Decoding with MTP
Append the following parameters to the command:
--speculative-algorithm EAGLE \
--speculative-num-steps [number of steps] \
--speculative-eagle-topk [top k] \
--speculative-num-draft-tokens [number of draft tokens]
GLM 4.5 Model Architecture and Highlights
GLM-4.5 adopts a MoE architecture with loss-free balance routing and sigmoid gates, enhancing compute efficiency. Compared to models like DeepSeek-V3 and Kimi K2, we prioritize depth over width—fewer experts and smaller hidden dimensions, but more layers—resulting in better reasoning performance.
Key architectural designs and highlights:
- Grouped-Query Attention with partial RoPE
- 96 attention heads for 5120 hidden size (2.5× more than typical), improving reasoning on MMLU/BBH despite similar training loss
- QK-Norm for stabilized attention logits
- Muon optimizer, enabling faster convergence and larger batch sizes
- MTP (Multi-Token Prediction) head for speculative decoding
- RL training is powered by the open-source framework slime, which was earlier open-sourced by THUDM.
Performance
We compare GLM-4.5 with various models from OpenAI, Anthropic, Google DeepMind, xAI, Alibaba, Moonshot, and DeepSeek on 12 benchmarks covering agentic (3), reasoning (7), and Coding (2). Overall, GLM-4.5 is ranked at the 3rd place and GLM-4.5 Air is ranked at the 6th.
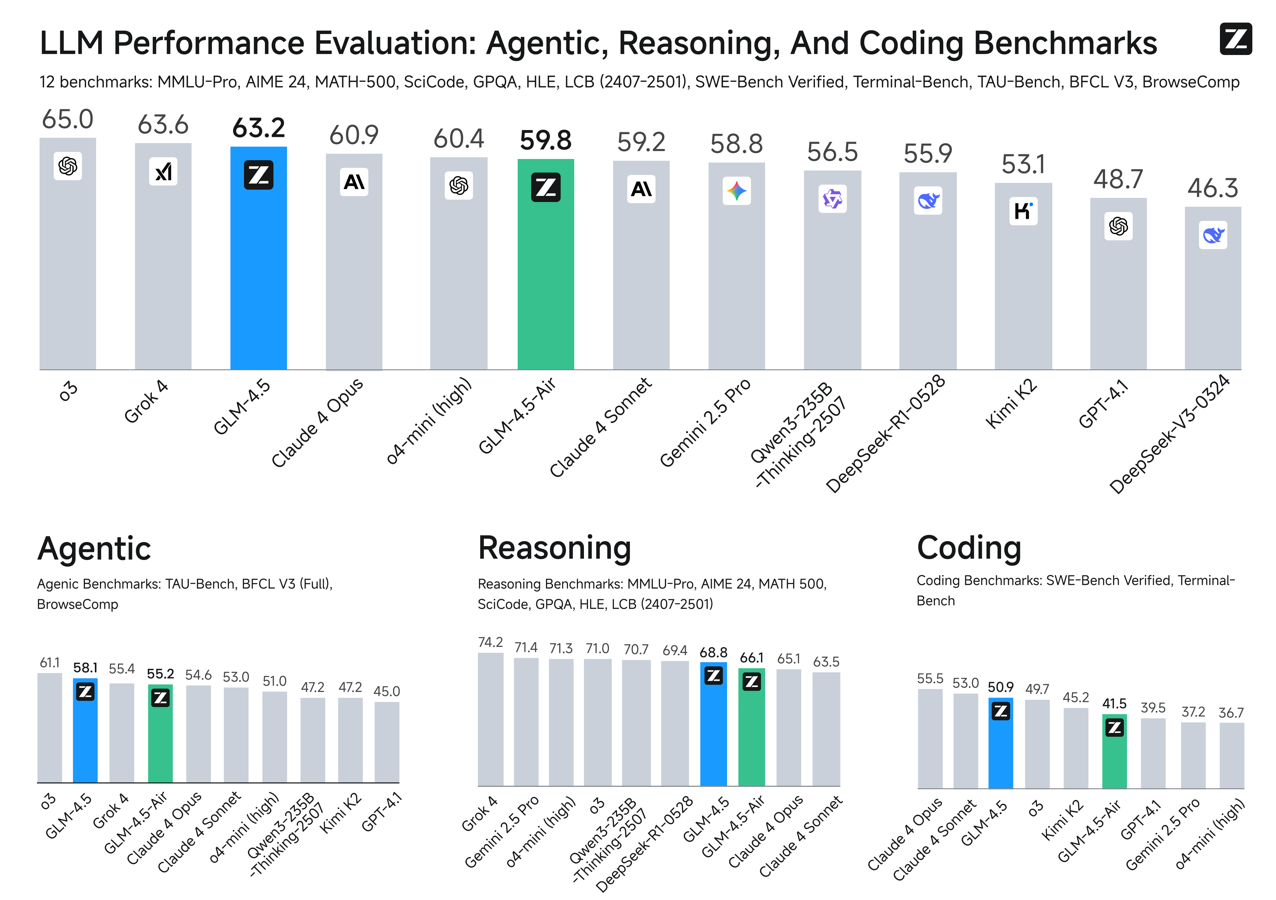
Agentic Abilities GLM-4.5 supports 128k context and native function calling. On both -bench and BFCL-v3, it matches Claude 4 Sonnet, and on the BrowseComp web browsing benchmark, it surpasses Claude 4 Opus (26.4% vs. 18.8%) and approaches GPT o4-mini-high (28.3%). Its high tool-calling success rate (90.6%) highlights its reliability in agent-based workflows.
Reasoning GLM-4.5 excels in mathematical and logical reasoning. It scores competitively on MMLU Pro (84.6), AIME-24 (91.0), and MATH500 (98.2), and demonstrates strong generalization across benchmarks like GPQA, LCB, and AA-Index.
Coding GLM-4.5 shows comprehensive full-stack development ability and ranks among the top models on SWE-bench Verified (64.2) and Terminal-Bench (37.5). In head-to-head evaluations, it achieves a 53.9% win rate over Kimi K2 and 80.8% over Qwen3-Coder. Its high agentic reliability, multi-round coding task performance, and visual interface quality demonstrate its strength as an autonomous coding assistant.
Conclusion
The GLM-4.5 series represents a new wave of large language models, excelling in long-context reasoning, agentic workflows, and coding tasks. Its hybrid MoE architecture—enhanced by techniques like grouped-query attention, MTP, and RL training—offers both efficiency and strong capability.
SGLang provides a production-ready, high-performance inference stack, enabling seamless deployment through advanced memory management and request batching.
Together, GLM-4.5 and SGLang form a robust foundation for next-generation AI—powering intelligent, scalable solutions across code, documents, and agents.
Acknowledgement
We would like to express our heartfelt gratitude to the following teams and collaborators in this PR:
- GLM Team: Yuxuan Zhang, Chenhui Zhang, Xin Lv, Zilin Zhu and colleagues.
- SGLang Team and community: Biao He, Lifu Huang, Binyao Jiang, Minglei Zhu, Cheng Wan, Chang Su, Xinyuan Tong and many others.