LongCat-Flash: Deploying Meituan's Agentic Model with SGLang
1. Introduction: Deploying Meituan's Agentic Open-Source MoE Model
LongCat-Flash, Meituan's open-source Agentic Mixture-of-Experts (MoE) model is now available from huggingface LongCat-Flash-Chat. Released by Meituan LongCat Team, it features:
- 560B total params
- 18.6B–31.3B (27B on average) per token activation
- 512 FFN experts and 256 zero-computation experts
- Shortcut-Connected Structure(ScMoE) for computation-communication overlap
- Multi-head Latent Attention (MLA)
Based on multiple benchmark tests, LongCat-Flash, as a non-thinking foundational model, performs comparably to leading mainstream models by activating only a small number of parameters. It particularly excels in agent tasks. Additionally, due to its inference efficiency-oriented design and innovations, LongCat-Flash demonstrates significantly faster inference speed, making it more suitable for complex, time-intensive agent applications.
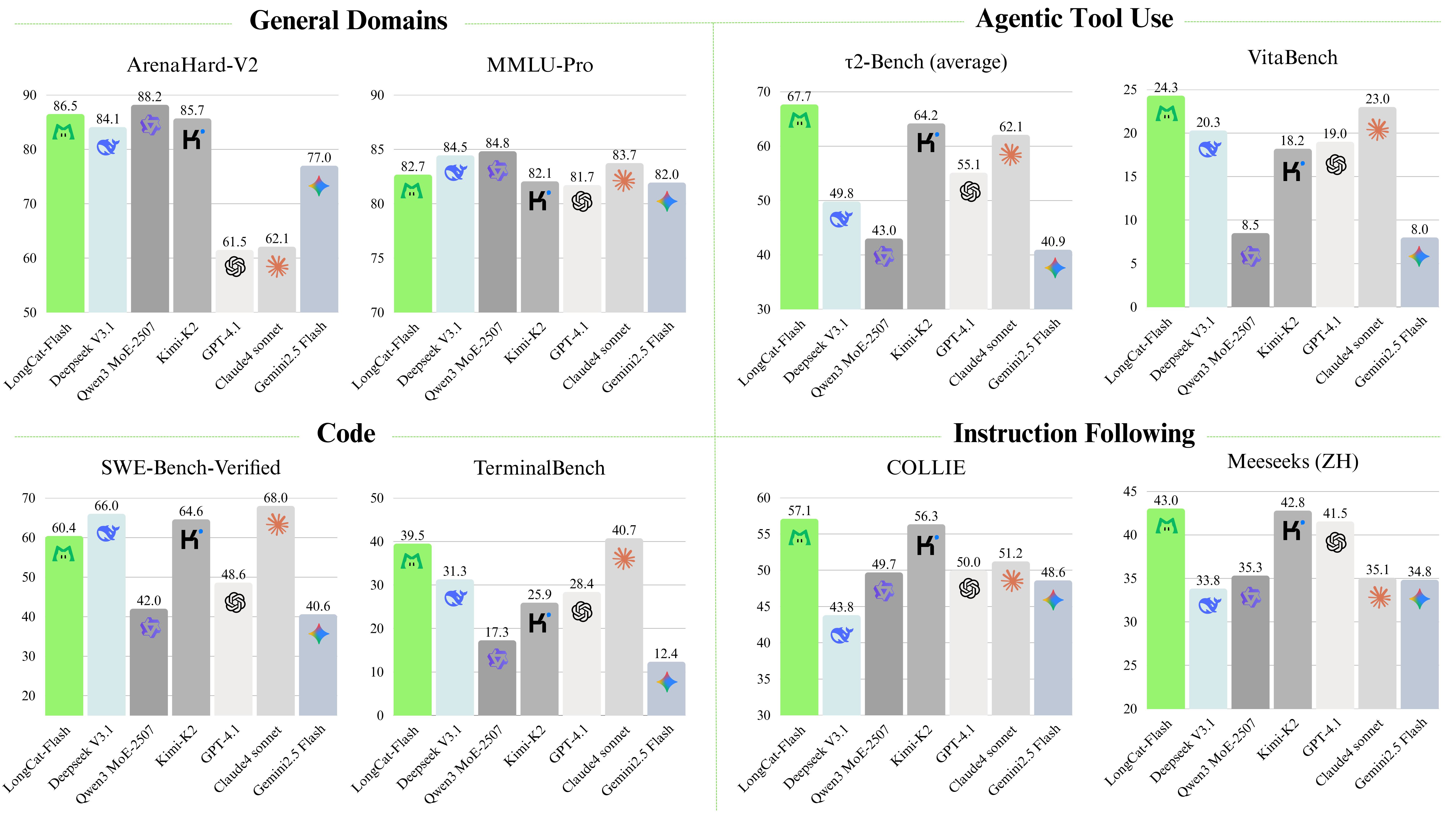
For more details, please refer to the our tech report LongCat-Flash-Technical-Report.
2. Why model-system co-design matters?
As noted in our tech report, a typical ReACT-based agent system imposes extreme requirements on both Prefill and Decode speeds due to its multi-round dialogue nature.
For Prefill, we observe that not every token in the model requires equal activation parameters. Based on this, we designed a dynamic activation feature that maintains model performance while controlling per-token activated parameters within 18.6B–31.3B (27B on average), which is crucial for reducing Prefill computation.
For decode, high sparsity of MoE models necessitates large batches to increase GEMM (General Matrix Multiply) compute intensity. While wide Expert Parallelism (EP) frees up HBM for larger KV caches—effectively increasing batch size, communication becomes the bottleneck. Overlapping computation/communication is key to performance. TBO (Two Batch Overlap) from DeepSeek V3/SGLang reduces latency via batch overlap but fails for small batches or single request. Throughput (large batch) and latency (small batch) are inherently conflicting objectives and often need trade-off for online applications. Through model-system co-design, ScMoE breaks this trade-off by optimizing both throughput and latency. Another advantage from ScMoE is that intra-node Tensor Parallelism communication (via NVLink) on the dense FFN can be fully overlapped with inter-node Expert Parallelism communication (via RDMA), thereby maximizing total network utilization.
3. Our Solution:SGLang + PD Disaggregation + SBO + Wide Expert Parallelism
3.1 PD Disaggregation
To enable independent optimization of prefilling and decoding phases, PD-Disaggregated architecture is adopted. Based on SGLang's PD Disaggregation, we developed our solution featuring layer-wise transmission, which significantly reduces Time-To-First-Token (TTFT) under high QPS workloads.
3.2 Single Batch Overlap (SBO)
SBO is a four-stage pipeline execution that uses module-level overlap to fully unleash LongCat-Flash’s potential. SBO differs from TBO by hiding communication overhead within a single batch. In SBO,
- Stage 1 requires separate execution because the MLA output serves as input for subsequent stages.
- Stage 2 is all-to-all dispatch overlapped with Dense FFN and Attn 0 (QKV Projection). This overlap is crucial because communication overhead is excessive, prompting us to split the attention process.
- Stage 3 independently executes MoE GEMM. The latency of this stage will benefit from the wide EP deployment strategy.
- Stage 4 overlaps Attn 1 (Core Attention and Output Projection) and Dense FFN with the all-to-all combine.
This orchestration effectively mitigates the communication overhead, ensuring efficient inference for LongCat-Flash. Since all overlap occurs within a single batch, SBO simultaneously improves throughput and reduces latency.
3.3 Wide Expert Parallelism
Expanding EP size and increasing batch size lead to higher communication overhead, but through SBO, the communication is overlapped by dense path computation. In SBO, the MoE computation remains exposed. Before reaching the compute-bound regime of MoE computation, scaling up EP size and batch size reduces MoE computation time. Consequently, SBO can achieve performance gains from wider EP configurations. By the way, we adopted DeepEP for MoE's dispatch and combine communication, similar to SGLang's implementation.
3.4 Other Optimization
Multi-step overlapped scheduler
To improve GPU utilization, SGLang implements an overlapped scheduler. However, experimental results reveal that the low latency of LongCat-Flash’s forward pass renders a single-step pre-schedule strategy insufficient to fully eliminate scheduling overhead. As a result, we implemented a multi-step overlapped scheduler to launch the kernels for multiple forward steps in a single schedule iteration. This approach effectively hides CPU scheduling and synchronization within the GPU forward process, ensuring continuous GPU occupancy.
Multi-Token Prediction
For optimal inference performance, we employ a single dense layer rather than a MoE layer as the MTP head. This feature has already been supported in SGLang. Because of LongCat-Flash’s lightweight MTP, separate scheduling of verification kernels and draft forward passes introduces significant overhead. To mitigate this, we adopted a TVD fusing strategy to fuse Target forward, Verification, and Draft forward into a single CUDA graph.
4. Performance
Cost & Latency Implications:
- Throughput-Optimized Scenarios: LongCat-Flash’s theoretical cost is <50% of comparable (or smaller) models.
- Latency-Optimized Scenarios: SBO’s intra-batch optimization enables minimal latency.
Benchmarks:
- Comparable throughput to DeepSeek V3: Outperforms in generation speed.
- Balanced throughput-latency: Tested on the NVIDIA H800 platform, achieves 100 tps with competitive cost.
| Model | Attention | Context | GPU | TGS | TPS/u |
|---|---|---|---|---|---|
| DeepSeek-V3-Profile | BF16 | 4096 | 128 | 2324 | 20 |
| LongCat-Flash | BF16 | 5000 | 128 | 2205 | 68.9 |
| LongCat-Flash | BF16 | 5000 | 128 | 804 | 100.5 |
5. Deploying LongCat-Flash with SGLang
We recommend deploying the LongCat-Flash using SGLang. Through close collaboration with the SGLang community, LongCat-Flash is supported on SGLang starting from day one. Due to its size of 560 billion parameters (560B), LongCat-Flash requires at least one node with 8xH20-141G node to host the model weights in FP8 format, and at least two nodes with 16xH800-80G for BF16 weights. Detailed launch configurations are provided below.
Install SGLang
pip install --upgrade pip
pip install uv
uv pip install "sglang[all]>=0.5.2.rc0"
Single-Node Deployment( 8xH20-141G)
The model can be served on a single node using a combination of Tensor Parallelism and Expert Parallelism.
python3 -m sglang.launch_server \
--model meituan-longcat/LongCat-Flash-Chat-FP8 \
--trust-remote-code \
--attention-backend flashinfer \
--enable-ep-moe \
--tp 8
Multi-Node Deployment( 16xH800-80G )
In a multi-node setup, Tensor Parallelism and Expert Parallelism are employed, with additional parallel strategies planned for future implementation.
Replace $NODE_RANK and $MASTER_IP with the specific values for your cluster.
python3 -m sglang.launch_server \
--model meituan-longcat/LongCat-Flash-Chat \
--trust-remote-code \
--attention-backend flashinfer \
--enable-ep-moe \
--tp 16 \
--nnodes 2 \
--node-rank $NODE_RANK \
--dist-init-addr $MASTER_IP:5000
Enabling Multi-Token Prediction (MTP)
To enable MTP with SGLang, you can add the following arguments to your launch command.
--speculative-draft-model-path meituan-longcat/LongCat-Flash-Chat \
--speculative-algorithm NEXTN \
--speculative-num-draft-tokens 2 \
--speculative-num-steps 1 \
--speculative-eagle-topk 1
6. Conclusion
By leveraging capabilities such as SGLang, PD Disaggregation, Wide Expert Parallelism, and SBO, we have achieved extremely low cost and fast generation speed for LongCat-Flash. The efficient inference of LongCat-Flash also relies on works from the SGLang team, Mooncake team, NVIDIA TensorRT-LLM, and other open-source communities. Moving forward, we plan to collaborate with the SGLang team to gradually upstream our SGLang-based optimizations to further support the open-source ecosystem.
Acknowledgments
We would like to express our heartfelt gratitude to the following teams and collaborators:
- SGLang Team and community: for their work on SGLang framework.
- Mooncake Team for their earliest opensource work in the industry on PD Disaggregation architecture and TransferEngine.
- NVIDIA TensorRT-LLM: for efficient kernels on Hopper GPUs.
- Meituan LongCat Team: for our Model-System co-design.