SGLang HiCache: Fast Hierarchical KV Caching with Your Favorite Storage Backends
From the community:
In a coding agent scenario using Qwen3-Coder-480B, the observed dialogues often stretched past 25K tokens around 8 turns per session. Without full KV cache retention, nearly every request required costly re-computation. By integrating SGLang HiCache with DeepSeek 3FS KVStore for large-scale historical KV caching, the session’s average TTFT dropped by 56%, inference throughput doubled, and the cache hit rate jumped from 40% to 80%.”
– Novita AI
Effective KV caching significantly reduces TTFT by eliminating redundant and costly re-computation. Integrating SGLang HiCache with the Mooncake service enables scalable KV cache retention and high-performance access. In our evaluation, we tested the DeepSeek-R1-671B model under PD-disaggregated deployment using in-house online requests sampled from a general QA scenario. On average, cache hits achieved an 84% reduction in TTFT compared to full re-computation.
– Ant Group
We also provide instructions to reproduce the performance gains on both a long-context benchmark and a multi-turn conversation benchmark at the end of this blog. In our measurements, HiCache achieved up to 6× throughput improvement and up to 80% reduction in TTFT, closely mirroring the results reported by the community. In addition to the 3FS and Mooncake storage backends mentioned above, SGLang also supports NIXL as well as a local file backend.
Why Hierarchical KV Caching Matters
Reusing historical KV caches has been proven to be critical for high-performance LLM serving systems. Our previously introduced RadixAttention achieved state-of-the-art performance by reusing KV caches stored in GPU memory. However, the caching benefit is inevitably limited by a capacity bottleneck: as contexts grow longer and more clients engage in more rounds of conversations, the cache hit rate declines because most historical KV caches must be evicted to make room for new data.
To address this challenge, we present SGLang HiCache, which extends RadixAttention with a HiRadixTree that acts as a page table for referencing KV caches residing locally in GPU and CPU memory. Alongside, a cache controller automatically manages loading and backing up KV cache data across hierarchies, including GPU and CPU memory pools as well as external layers such as disks and remote memory. Following figure presents an overview of SGLang HiCache.
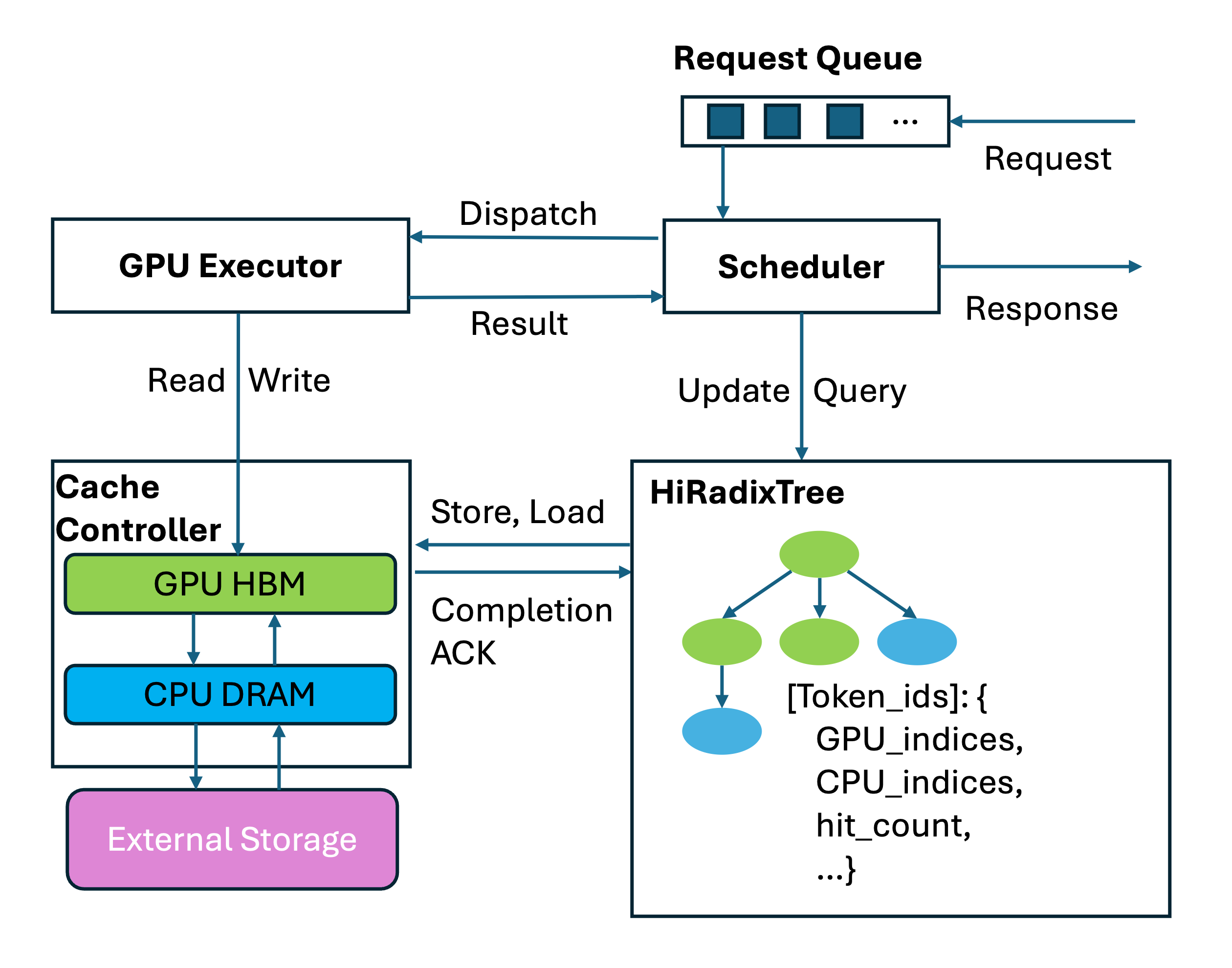
Design of SGLang HiCache:
Optimized data plane
The key bottleneck in hierarchical memory systems is the latency of moving data from slower to faster tiers. Beyond the standard cudaMemcpyAsync, we developed a set of GPU-assisted I/O kernels that deliver up to 3× higher throughput for CPU–GPU transfers.
To further accelerate data movement between CPU memory and storage layers, enabled by the implemented kernels, we decoupled the host memory pool’s layout from the GPU layout as illustrated in Figure 1. While the GPU memory pool remains unchanged as a “layer-first” style for compatibility with computation kernels, HiCache uses a “page-first” layout for other layers to prioritize IO efficiency. This enables larger transfer sizes per transaction, and when combined with a zero-copy mechanism, achieves up to 2× higher throughput in typical deployments. You can refer to the PRs (Mooncake, 3FS) for more details.
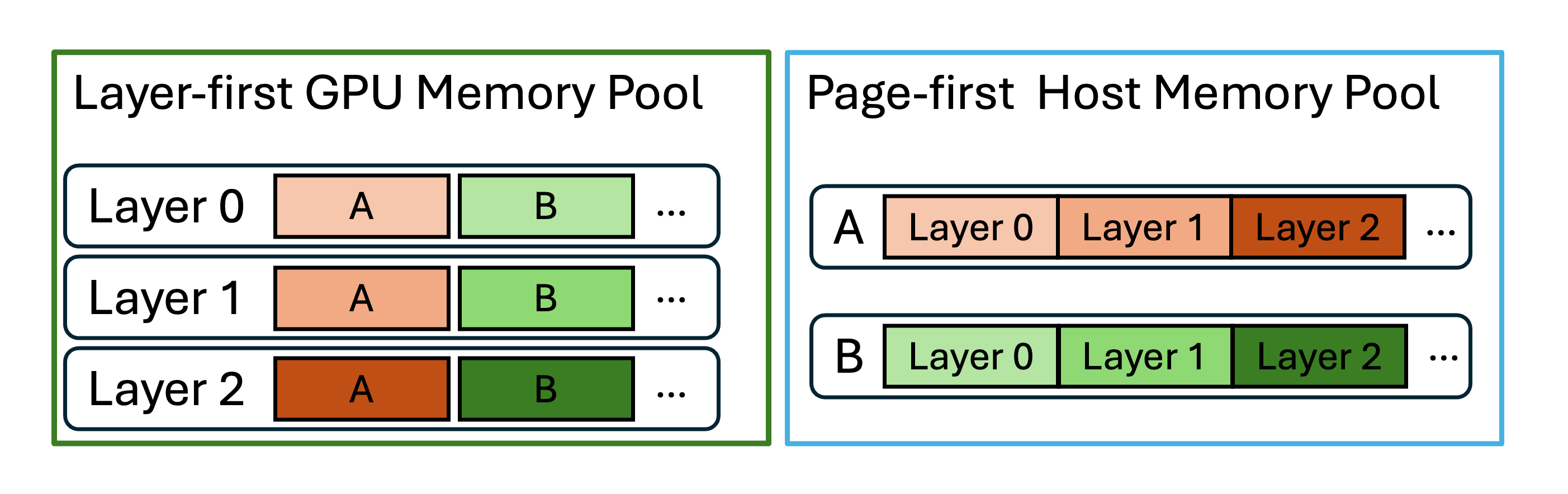
Versatile control plane
When a cache miss happens on the GPU but hits the CPU memory, since the bandwidth between the two layers is typically high, we apply a layer-wise overlapping mechanism to load the data. This enables concurrent KV cache loading for layer N+ while layer N is executing, effectively hiding data transfer latency behind computation. When external storage is involved, the cache controller opportunistically prefetches data from storage into host memory once a cache hit is detected at the storage tier. The prefetch strategy is configurable: it can operate in best-effort mode, terminate in-flight prefetching if a request becomes due for scheduling to minimize TTFT, or stage requests more aggressively to improve cache reuse and potentially raise overall throughput.
This different design choice for storage layers is motivated by the often significantly higher and less predictable latency of storage compared to host–GPU transfers, and we remain open to techniques such as GPU Direct Storage when the performance tradeoffs are favorable. SGLang HiCache also supports multiple cache write policies for moving data from faster to slower tiers. A write-through policy provides the strongest caching benefits if bandwidth permits, while a write-through-selective mode leverages hit-count tracking to back up only hot spots, reducing I/O load. In cases where even the slower memory tiers become capacity-constrained, a write-back policy can effectively mitigate the pressure.
Pick your favorite storage backend or bring your own!
The best part of SGLang HiCache is how simple it is to plug in a new storage backend. Thanks to our clean, generic interfaces, integration requires implementing only three functionalities in your backend: get(key), exist(key), set(key, value). Everything else, including heavy-lifting tasks such as scheduling and synchronization coordination, is handled by the central cache controller.
This design has already enabled us to integrate three performant backends—Mooncake, 3FS, and NIXL—with more on the way. For demonstration purposes, we also provide a simple HiCacheFile backend to serve as a reference. We are also working on the co-design and performance optimization of HiCache and PD Disaggregation. We warmly welcome contributions and community feedback, whether it’s about new scheduling policies, refactoring existing designs, observability features, compatibility of parallel strategies, or support for additional backends.
Benchmark
Try experience the performance gain on your own! You can find various benchmark about HiCache here. Following we highlight two benchmark results using the provided benchmark scripts and you can find the config instructions of backends here. If you have any questions about benchmarking or deployment, feel free to open an issue on GitHub or post in our slack channel.
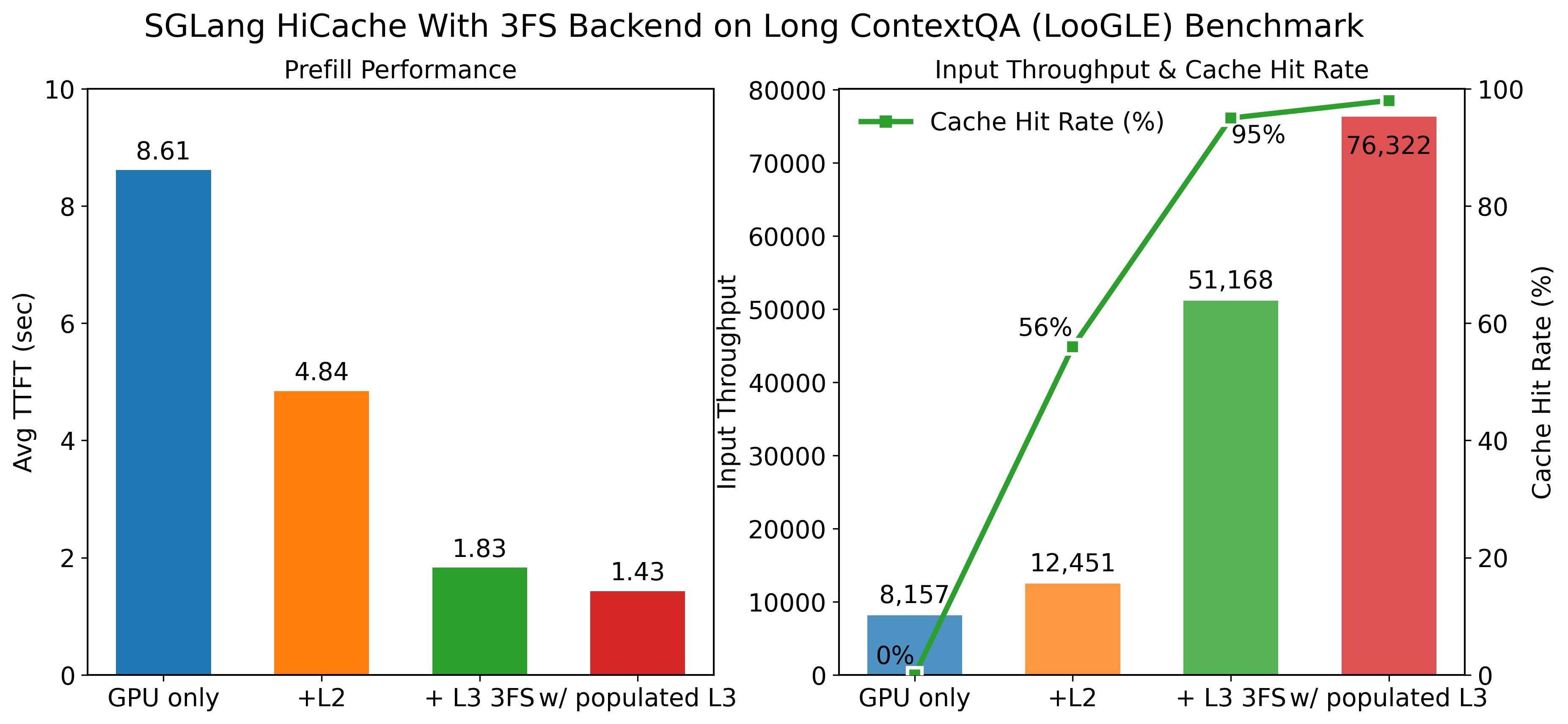
# DeepSeek R1 on 8 * H20-3e using 3FS
python3 -m sglang.launch_server --model-path /DeepSeek-R1/ --tp 8 --page-size 64 \
--context-length 65536 --chunked-prefill-size 6144 --mem-fraction-static 0.85 \
--enable-hierarchical-cache --hicache-ratio 2 \
--hicache-io-backend kernel --hicache-mem-layout page_first \
--hicache-storage-backend hf3fs --hicache-storage-prefetch-policy wait_complete
python3 bench_long_context.py --model-path /DeepSeek-R1/ --dataset-path loogle_wiki_qa.json
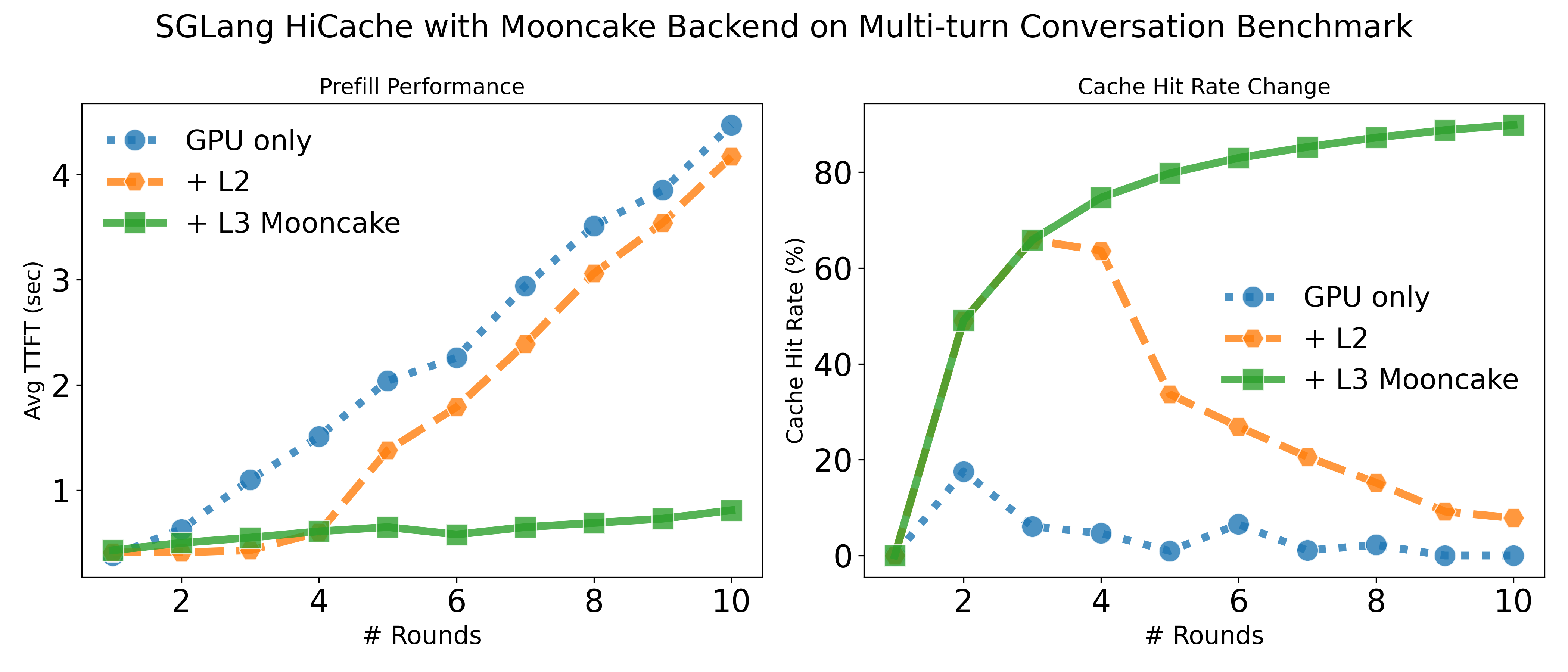
# Qwen3-235B-A22B-Instruct-2507 on 8 × H800 GPUs with 8 × mlx5 RDMA NICs using Mooncake
MOONCAKE_TE_META_DATA_SERVER="http://127.0.0.1:8080/metadata" \
MOONCAKE_GLOBAL_SEGMENT_SIZE=816043786240, MOONCAKE_PROTOCOL="rdma" \
MOONCAKE_DEVICE="$DEVICE_LIST", MOONCAKE_MASTER=127.0.0.1:50051 \
python3 -m sglang.launch_server --model-path $MODEL_PATH --tp 8 --page-size 64 \
--enable-hierarchical-cache --hicache-ratio 2 \
--hicache-storage-prefetch-policy timeout --hicache-storage-backend mooncake
python3 benchmark/hicache/bench_multiturn.py --model-path $MODEL_PATH --disable-random-sample \
--output-length 1 --request-length 2048 \ # simulate P-D disaggregation
--num-clients 80 --num-rounds 10 --max-parallel 4 --request-rate 16 \
--ready-queue-policy random --disable-auto-run --enable-round-barrier
We also want to highlight NIXL as a special backend, which is a transfer library designed to bridge storage backends such as GPU-direct storage and cloud object storage. You can find more details here and stay tuned for upcoming integration with the Dynamo ecosystems.
Acknowledgement:
We would like to express our sincere gratitude for the tremendous support and feedback from the community. We are grateful to Sicheng Pan, Zhangheng Huang, Yi Zhang, Jianxing Zhu, and Yifei Kang from the Alibaba Cloud TairKVCache team for the 3FS backend integration; Tingwei Huang and Yongke Zhao from Ant Group; Teng Ma, Shangming Cai, and Xingyu Liu from Alibaba Cloud; Jinyang Su and Ke Yang from Approaching.AI; and Zuoyuan Zhang and Mingxing Zhang from the Mooncake community for their efforts on Mooncake integration; Moein Khazraee, Vishwanath Venkatesan, and the Dynamo team from NVIDIA for enabling the NIXL integration. Special thanks go to Ziyi Xu from the SGLang team, Yuwei An from LMCache, Vikram Sharma Mailthody, Scott Mahlke, and Michael Garland from NVIDIA, as well as Mark Zhao and Christos Kozyrakis from Stanford for their contributions to the HiCache design and implementation. Finally, we appreciate the ongoing contributions from the LMCache, AIBrix, PrisDB, and ByteDance EIC teams in bringing their products into the ecosystem.