Towards Deterministic Inference in SGLang and Reproducible RL Training
TL;DR: This post shares our efforts to enable deterministic inference in SGLang and our collaboration with slime to work towards reproducible RL training.
Recently, the Thinking Machines Lab published a blog detailing their findings. Since this blog was published, the industry has responded enthusiastically, eagerly awaiting open-source inference engines to implement stable and usable deterministic inference, or even further, to achieve fully reproducible RL training. Now, SGLang and slime together provide the answer.
Building on Thinking Machines Lab's batch-invariant operators, SGLang achieves fully deterministic inference while maintaining compatibility with chunked prefill, CUDA graphs, radix cache, and non-greedy sampling. With CUDA graphs, SGLang delivers 2.8x acceleration and reduces performance overhead to just 34.35% (vs. TML's 61.5%).
Taking this deterministic inference capability further, SGLang collaborated with the slime team to unlock 100% reproducible RL training - a breakthrough achieved with minimal code changes. Our validation experiments on Qwen3-8B demonstrate perfect reproducibility: two independent training runs produce identical curves, providing the reliability needed for rigorous scientific experimentation.
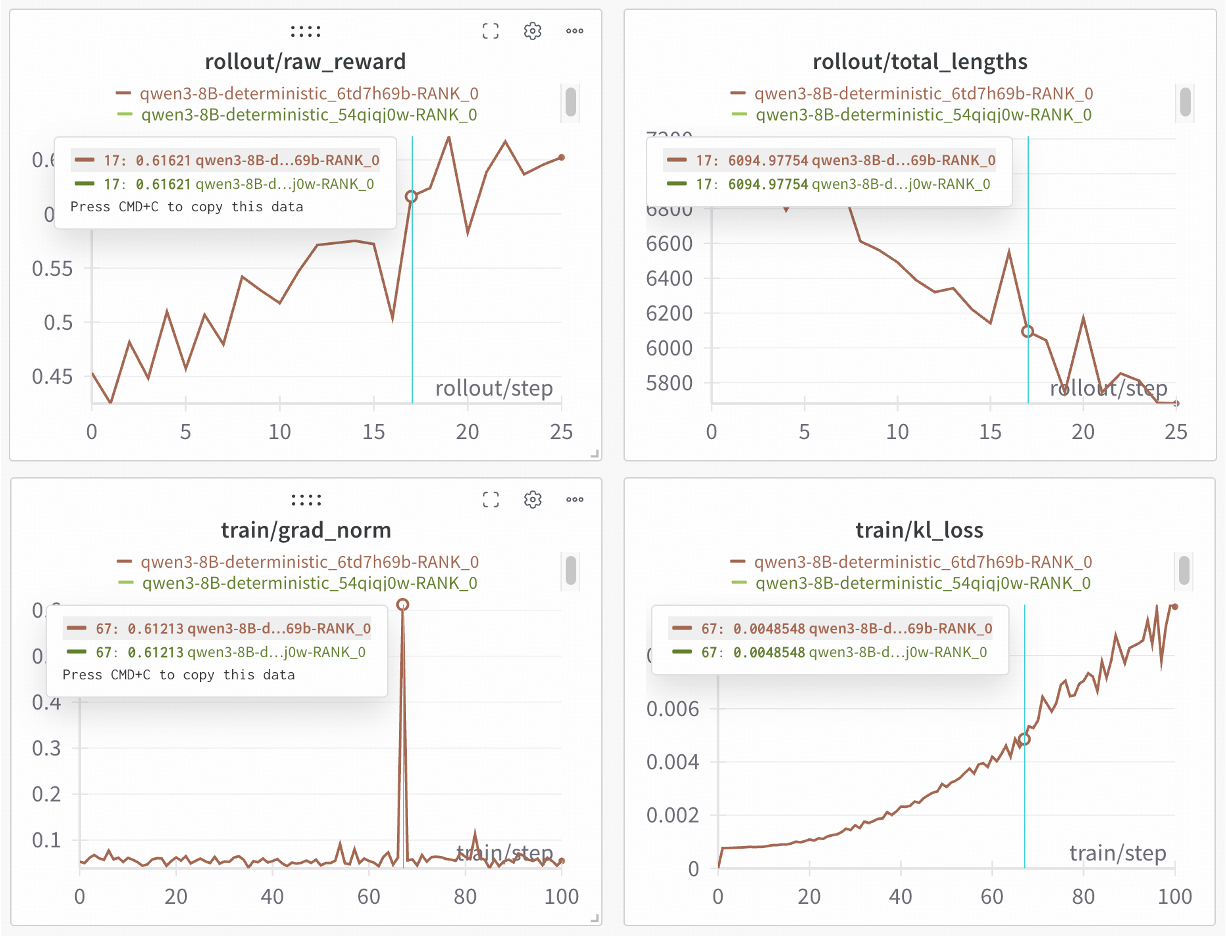
Now let's dive into the some technical details.
Why Deterministic Inference Matters
The ability to achieve consistent outputs from large language models (LLMs) inference is increasingly important. For example, the indeterminism of inference results can implicitly transform on-policy reinforcement learning (RL) into off-policy RL as researchers pointed out. However, even if we turn the temperature down to 0 in SGLang, the sampling is still not deterministic due to the use of dynamic batching and radix cache (past discussions here) .
As mentioned in the blog, the largest source of nondeterminism is the varying batch sizes: Even when a user repeatedly submits the same prompt, the output can vary across runs, since the request may be batched together with other users' requests, and differences in batch size can lead to nondeterministic inference results.
To explain more, different batch sizes will influence the reduction splitting process of kernels. This leads to varying order and size for each reduction block, which can cause nondeterministic outputs due to the non-associativity of floating-point arithmetic. To fix this, they replaced reduction kernels (RMSNorm, matrix multiplication, attention, etc…) with a batch-invariant implementation. These kernels were also released as a companion library for external integration.
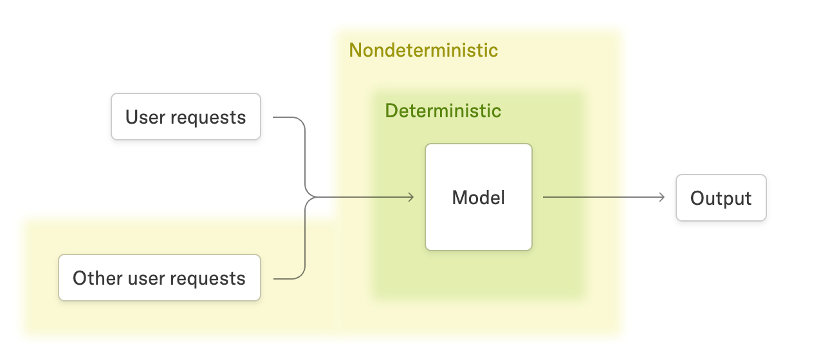
Building on the work of Thinking Machines Lab, SGLang delivers a robust, high-throughput solution for deterministic LLM inference, combining batch-invariant kernels, CUDA graphs, radix cache, and chunked prefill with efficient performance. Determinism has been extensively validated through comprehensive tests and RL training experiments.
Key enhancements include:
- Integration of batch-invariant kernels from Thinking Machines Lab, including mean, log-softmax, and matrix multiplication kernels.
- Implementation of batch-invariant attention kernels with fixed split-KV size. Multiple backends are supported, including FlashInfer, FlashAttention 3, and Triton.
- Full compatibility with common inference features, such as chunked prefill, CUDA graph, radix cache, all of which remain supported when deterministic inference is enabled.
- Expose a per-request seed in sampling arguments, allowing users to enable deterministic inference even when temperature > 0.
- Better performance: Compared to the 61.5% slowdown reported in TML's blog, SGLang achieves an average slowdown of only 34.35% with the FlashInfer and FlashAttention 3 backends, representing a significant improvement. With CUDA graphs, 2.8x speedup can be achieved compared to the minimal integration.
Results
Verifying Deterministic Behavior
We introduce a deterministic test suite to verify whether inference results remain consistent under different batching conditions. The test covers three subtests, progressing from simple to more challenging:
- Single: Run the same prompt across varying batch sizes and check if outputs remain identical.
- Mixed: Mix different types of prompts (short prompts and long prompts) within the same batch and verify consistency.
- Prefix: Use prompts derived from the same long text with different prefix lengths, batch them randomly, and test whether results are reproducible across trials.
Here are the results from 50 sampling trials. The numbers indicate the count of unique outputs observed for each subtest (lower = more deterministic).
| Attention Backend | Mode | Single Test | Mixed Test (P1/P2/Long) | Prefix Test (prefix_len=1/511/2048/4097) |
|---|---|---|---|---|
| FlashInfer | Normal | 4 | 3 / 3 / 2 | 5 / 8 / 18 / 2 |
| FlashInfer | Deterministic | 1 | 1 / 1 / 1 | 1 / 1 / 1 / 1 |
| FA3 | Normal | 3 | 3 / 2 / 2 | 4 / 4 / 10 / 1 |
| FA3 | Deterministic | 1 | 1 / 1 / 1 | 1 / 1 / 1 / 1 |
| Triton | Normal | 3 | 2 / 3 / 1 | 5 / 4 / 13 / 2 |
| Triton | Deterministic | 1 | 1 / 1 / 1 | 1 / 1 / 1 / 1 |
*Tested on QWen3-8B
* Cuda graph, chunked prefill are enabled. Radix cache is disabled for Flashinfer and Triton since their support is still in progress.
CUDA Graph Acceleration
CUDA graphs can accelerate the inference process by consolidating multiple kernel launches into a single launch. Our evaluation compared the total throughput of deterministic inference with and without CUDA graphs enabled. The test workload consisted of 16 requests, each with an input length of 1024 and an output length of 1024. The results show an at least 2.79x speedup across all attention kernels when CUDA graphs is utilized.
| Attention Backend | CUDA Graph | Throughput (tokens/s) |
|---|---|---|
| FlashInfer | Disabled | 441.73 |
| FlashInfer | Enabled | 1245.51 (2.82x) |
| FA3 | Disabled | 447.64 |
| FA3 | Enabled | 1247.64 (2.79x) |
| Triton | Disabled | 419.64 |
| Triton | Enabled | 1228.36 (2.93x) |
*Setup: QWen3-8B, TP1, H100 80GB
*We disabled radix cache for all performance benchmarks since FlashInfer and Triton Radix Cache support is still in progress.
Measuring Offline Inference Performance
We measured end-to-end latency for both non-deterministic and deterministic modes using three common RL rollout workloads (256 requests with varying input/output lengths).
Deterministic inference is generally usable, with most slowdowns ranging from 25% to 45%, and average slowdown of FlashInfer and FlashAttention 3 backends being 34.35%. The majority of this overhead comes from unoptimized batch-invariant kernels (matrix multiplication and attention), indicating significant room for performance improvements.
| Attention Backend | Mode | Input 1024 Output 1024 | Input 4096 Output 4096 | Input 8192 Output 8192 |
|---|---|---|---|---|
| FlashInfer | Normal | 30.85 | 332.32 | 1623.87 |
| FlashInfer | Deterministic | 43.99 (+42.6%) | 485.16 (+46.0%) | 2020.13 (+24.4%) |
| FA3 | Normal | 34.70 | 379.85 | 1438.41 |
| FA3 | Deterministic | 44.14 (+27.2%) | 494.56 (+30.2%) | 1952.92 (+35.7%) |
| Triton | Normal | 36.91 | 400.59 | 1586.05 |
| Triton | Deterministic | 57.25 (+55.1%) | 579.43 (+44.64%) | 2296.60 (+44.80%) |
*Setup: QWen3-8B, TP1, H200 140GB.
*We disabled radix cache for all performance benchmarks since FlashInfer and Triton Radix Cache support is still in progress.
We acknowledge that deterministic inference is significantly slower than normal mode. We recommend using it primarily for debugging and reproducibility. Future work will focus on accelerating deterministic inference, with the goal of reducing the performance gap to under 20%, or ideally achieving parity with normal mode.
Usage
Environment Setup
To set up the environment, install SGLang with version >=0.5.3
pip install "sglang[all]>=0.5.3"
Launching the Server
SGLang supports deterministic inference across multiple models. For example, with Qwen3-8B you only need to add the --enable-deterministic-inference flag when launching the server:
python3 -m sglang.launch_server \
--model-path Qwen/Qwen3-8B \
--attention-backend <flashinfer|fa3|triton> \
--enable-deterministic-inference
Technical Details
Chunked Prefill
SGLang's chunked prefill technique is designed to manage requests with long contexts. However, its default chunking strategy violates the determinism requirement for attention kernels.
As illustrated in the figure, consider two input sequences, seq_a and seq_b, each with a context length of 6,000. The maximum chunk size for chunk prefill is 8192, while the required split-KV size for deterministic attention is 2,048. Each sequence can be partitioned into three smaller units (a1 to a3 and b1 to b3), with lengths of 2,048, 2,048, and 1,904, respectively. If these smaller units remain intact during chunk prefilling, then they can be processed by the same attention kernel and lead to deterministic reduction behavior.
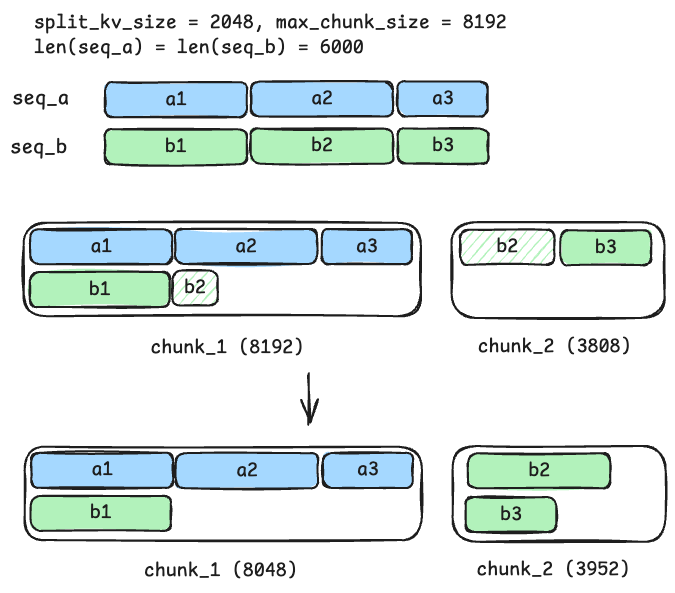
The standard chunking strategy operates on a "best-effort" principle. In this example, this strategy tries to generate a chunk_1 of 8,192 tokens by splitting the b2 unit of seq_b into two smaller parts. This can cause inconsistent truncation points since the length of b2 after splitting depends on the length of seq_a. To address this, we adapted the chunking logic to align the truncation point with an integer multiple of the split_kv_size. This adjustment ensures that the processing of b2 is deferred to a subsequent chunk, allowing it to be computed as a complete unit by the attention kernel.
Attention Backends
Attention kernel is an important part of determinism. For different attention backends, we modified them in different ways to satisfy their usage requirements.
- For Flashinfer backend, we utilize the
fixed_split_sizeanddisable_kv_splitarguments from batch invariant FA2 kernels to fix split sizes during kernel planning. Truncation of chunked prefill is aligned to the prefill split size. (PR link) - For FlashAttention-3 backend, num-splits of flash attention kernel are fixed to 1 to ensure determinism. (PR link)
- For Triton backend, we fix the split size of decoding, and manually set the alignment size of chunked prefill. Deterministic inference can also run on AMD hardware with the extensibility of Triton backend. (PR link).
Reproducible Non-Greedy Sampling
To extend determinism beyond greedy decoding, we introduce a new sampling function: multinomial_with_seed.
Instead of relying on torch.multinomial, which is inherently nondeterministic under batching, this operator perturbs logits with Gumbel noise generated from a seeded hash function. As a result, the same (inputs, seed) pair always yields the same sample, even when temperature > 0.
This modification enables deterministic multinomial sampling while preserving the stochasticity required by reinforcement learning rollouts.
RL Framework Integration (slime)
We integrated deterministic inference with temperature > 0 into slime's GRPO training recipe. In preliminary experiments, repeated RL training runs produced identical rollout responses and loss values for the first iterations, confirming that the rollout process itself is deterministic.
In a follow-up PR, we further enabled full training reproducibility by implementing the following key configurations:
- Flash Attention: Use Flash Attention v2 instead of v3 to enable deterministic backward passes
- Megatron: Set
--deterministic-modeflag for deterministic training - Environment Variables: Configure critical settings:
NCCL_ALGO=RingNVTE_ALLOW_NONDETERMINISTIC_ALGO=0CUBLAS_WORKSPACE_CONFIG=:4096:8
- PyTorch: Enable
torch.use_deterministic_algorithms(True, warn_only=False)
With these comprehensive changes, we successfully achieved full training reproducibility for GRPO in slime, enabling truly deterministic end-to-end RL training pipelines.
Future Work
Our future efforts will focus on enhancing deterministic inference by addressing the following key areas:
- Faster batch invariant kernels: Batch invariant kernels are the bottleneck of performance, so we'll work on optimizing their configurations and potentially rewriting them to boost performance. This is also critical for improving the speed of RL rollouts.
- Support for MoE models: Currently we only support deterministic inference for dense models like QWen3-8B or LLaMa-3.1-8B. In the future we plan to expand our support to MoE models like Qwen3-30B-A3B or DeepSeek-V3.
- True On-Policy RL: We plan to further integrate deterministic inference into reinforcement learning frameworks (e.g., slime) to enable reproducible sampling, with the ultimate goal of achieving true on-policy training.
- Enhancing Radix Cache Functionality: We will improve the radix tree to enable compatibility with a wider variety of attention kernels, moving beyond current limitation to the FlashAttention 3 backend.
- Tensor Parallelism: TP1 and TP2 are deterministic due to consistent floating-point addition order; larger TP setups require modifications to reduce kernels for determinism.
- FlexAttention Integration: Besides currently supported attention backends, we plan to extend our support of deterministic inference to FlexAttention in the future.
- A roadmap for deterministic inference features can be found in this issue.
SGLang's deterministic inference and slime's reproducible training capabilities are currently under active development and improvement. We sincerely welcome users and developers to actively try out these features and provide us with valuable feedback. Your experience and suggestions will help us further optimize these important capabilities and advance the development of deterministic inference technology.
Acknowledgement
We would like to extend our heartfelt gratitude to the following teams and collaborators:
- SGLang team and community: Baizhou Zhang, Biao He, Qiaolin Yu, Xinyuan Tong, Ke Bao, Yineng Zhang, Chi Zhang, Ying Sheng, Lianmin Zheng and many others
- Flashinfer team and community: Wenxuan Tan, Yilong Zhao, Zihao Ye
- slime team and community: Zilin Zhu
- AMD: Yusheng Su
- Thinking Machines Lab: for their awesome blog and batch_invariant_ops library