Deploying DeepSeek on GB200 NVL72 with PD and Large Scale EP (Part II): 3.8x Prefill, 4.8x Decode Throughput
The GB200 NVL72 is one of the most powerful hardware for deep learning. In this blog post, we share our progress after our previous blog post to optimize the inference performance of DeepSeek V3/R1 with FP8 attention, NVFP4 MoE, large-scale expert parallelism, prefill-decode disaggregation, and various other optimizations. When using FP8 attention and NVFP4 MoE, SGLang achieved 26,156 input and 13,386 output tokens per second per GPU for prefill and decode, respectively, on DeepSeek V3/R1 for 2000-token input sequences, which is a 3.8x and 4.8x speedup compared to H100 settings. Even with traditional BF16 attention and FP8 MoE, SGLang still achieves 18,471 input and 9,087 output tokens per second. Reproduction instructions can be found here.
Highlights
- SGLang achieves 26,156 input and 13,386 output tokens per second per NVIDIA Blackwell GPU for prefill and decode, respectively, on DeepSeek V3/R1 for 2000-token input sequences, which is a 3.8x and 4.8x speedup compared to H100 settings.
- For traditional precision (BF16 for attention and FP8 for GEMM), SGLang still achieves 18,471 input and 9,087 output tokens per second.
- Using FP8 for attention and NVFP4 for GEMM kernels, compared with the original precision counterparts, leads to up to 1.8x and 1.9x improvement, respectively.
- The FP8 attention and NVFP4 GEMM leads to negligible accuracy degradation.
Methods
The following strategies are applied:
- FP8 Attention: In addition to the traditional BF16 precision, we now support the FP8 precision for KV cache in attention. This roughly halves the memory access pressure in decode and allows faster Tensor Core instructions, resulting in a speedup for decode attention kernels. Furthermore, this also results in a larger number of tokens in the KV cache, enabling longer sequences and larger batch sizes, and the latter further increases the system efficiency.
- NVFP4 GEMM: Compared to the classical FP8 GEMM, the new NVFP4 precision not only reduces the memory bandwidth pressure for GEMM, but also allows leveraging the more powerful FP4 Tensor Core. Secondly, it also speeds up token dispatching by halving the required communication traffic. Last but not least, it reduces the memory consumption of weights, enabling either scaling down or more space for KV cache. Besides that the MoE experts are executed in NVFP4 precision, the output projection GEMM in attention is also optionally quantized to NVFP4. Different from the official NVIDIA checkpoint, we further execute q_b_proj in FP8 instead of BF16 to enhance performance.
- Scaling Down by Offloading: In addition to scaling up, we also support scaling down the expert parallel (EP) size. When device memory is insufficient, we utilize GB200’s fast bandwidth between CPUs and GPUs (900GB/s, bidirectional) to offload weights to the host memory with prefetching. This reduces the communication overhead and results in improved performance when it outweighs computation slowdown, and thus the optimal scale is related to the currently used computation and communication kernels besides model configs. This also minimizes the explosion radius since each prefill instance uses fewer GPUs. Lastly, it may reduce the time wasted waiting for the slowest rank.
- Computation Communication Overlap: The two-batch overlap used in the previous hardware may not be the most suitable given the significantly increased communication bandwidth, thus we adopt a fine-grained overlapping approach. For simplicity, we overlap the combine communication with both the down GEMM and the shared experts. When implementing signaling in GEMM, we use atomic instructions with release semantics after the TMA store wait which is sufficiently many steps after the TMA store commit. In addition, we use the cp.async.bulk.wait_group PTX instruction, which is the family used in tma_store_wait or equivalent procedures but removing the .read suffix.
At the kernel level, the following concrete kernels are integrated into SGLang or optimized:
- NVIDIA Blackwell DeepGEMM for prefill attention: The NVIDIA Blackwell DeepGEMM is a unified kernel that achieves high performance in both prefill and decode. Therefore, in addition to using it in decode since the last blog, we integrated the kernel into the prefill code path.
- FlashInfer Blackwell CuTe DSL GEMM for NVFP4 decode: This kernel utilizes CuTe DSL to implement GEMM with masked layout in NVFP4 precision. It leverages Tensor Memory Access (TMA) and tcgen05.mma instructions (including 2CTA MMA) for efficient computation, while also using persistent tile scheduling and warp specialization.
- FlashInfer Blackwell CUTLASS GEMM for NVFP4 prefill: This module supports multiple data types and is implemented via CUTLASS. The optimizations applied are similar to those in the CuTe DSL version. Designed for high-throughput workloads, it is especially suited for prefill.
- Flash Attention CuTe for BF16 KV-cache prefill: Similar to the GEMM above, this kernel is written in the CuTe DSL framework and achieves high performance for MHA during prefill.
- FlashInfer Blackwell TensorRT-LLM Attention for decode and FP8 KV-cache prefill: This kernel utilizes persistent schedulers based on cluster launch control, which efficiently hides prologue and epilogue. It also implements better overlapping between computation and memory loading. It supports both BF16 and FP8 precision.
- Fusing NVFP4 in DeepEP: DeepEP optionally quantizes tokens before dispatching them, thus NVFP4 quantization is fused into it alongside the original FP8, halving the required network traffic.
- Smaller Kernels: Firstly, other kernels, such as quantization and concatenation, are optimized and fused. Secondly, we also optimized the MLA RoPE quantize kernel in FlashInfer. Last but not least, we also slightly optimized several kernels located in FlashInfer from TensorRT-LLM, as a prototype, with a 5% end-to-end speedup and a up to 2.5x kernel speedup.
Experiments
End-to-end Performance
We evaluate the end-to-end performance of DeepSeek in SGLang on the GB200 NVL72. To ensure consistency, we follow the experimental setup from our previous blog post series (large-scale EP and GB200 part 1), with the baseline numbers directly copied from them. We assess both the original precision (BF16 for attention and FP8 for MoE) and the reduced precision (FP8 for attention and NVFP4 for MoE and output projection GEMM). For decode, we use 48 ranks, i.e. large scale EP; for prefill, we use 4 ranks per instance for high-precision and 2 for low-precision. We use an early access version of CuTe DSL since a needed bugfix is not yet publicly released.
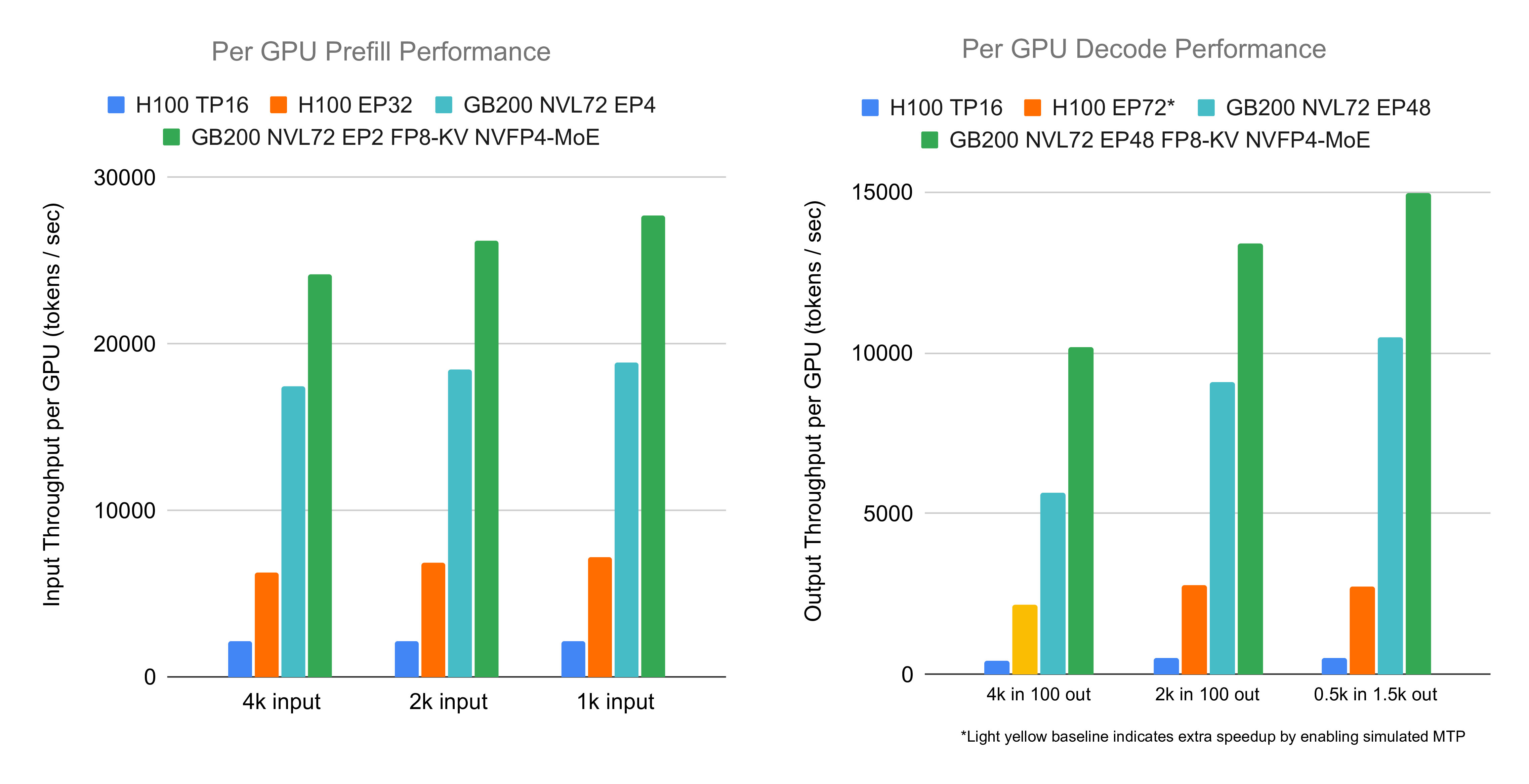
The experiments demonstrate a speedup of 3.8x and 4.8x for prefill and decode, respectively, on GB200 compared to H100. This speedup is potentially attributed to the following major factors:
- Reduced Precision: As mentioned above, using FP8 instead of BF16 for attention and NVFP4 instead of FP8 for various GEMMs lead to speedup. This stems from both reduced computation and memory access, as well as larger batch sizes enabled by fitting more tokens into the KV cache.
- Faster Kernels: We integrated the faster attention and GEMM kernels, as is shown above, which account for a significant portion of end-to-end time.
- Various Optimizations: Optimizations like overlapping, offloading, smaller kernel speedups and fusions, etc, contribute multiplicatively to the final speedup.
- Previously Mentioned Factors: The factors mentioned in the previous blog apply not only to decode but also to the new prefill optimizations, so they are not repeated here.
As a remark, the end-to-end performance differences between the high-precision and low-precision code paths are not solely due to the change of precision; we will examine that more closely in the next section. On one hand, different code paths employ distinct auxiliary kernels and strategies, and some have yet to be fully optimized. On the other hand, EP balancedness across experiments is not identical, since we follow our previous blogs to let data be in-distribution. The batch size is chosen to make KV cache roughly full (thus 768 for 4k ISL and 1408 for 2k ISL), but can also be lowered (e.g. changing batch size from 1408 to 768 for 2k ISL reduces performances by roughly one tenth).
Zoom into Low-precision Kernels
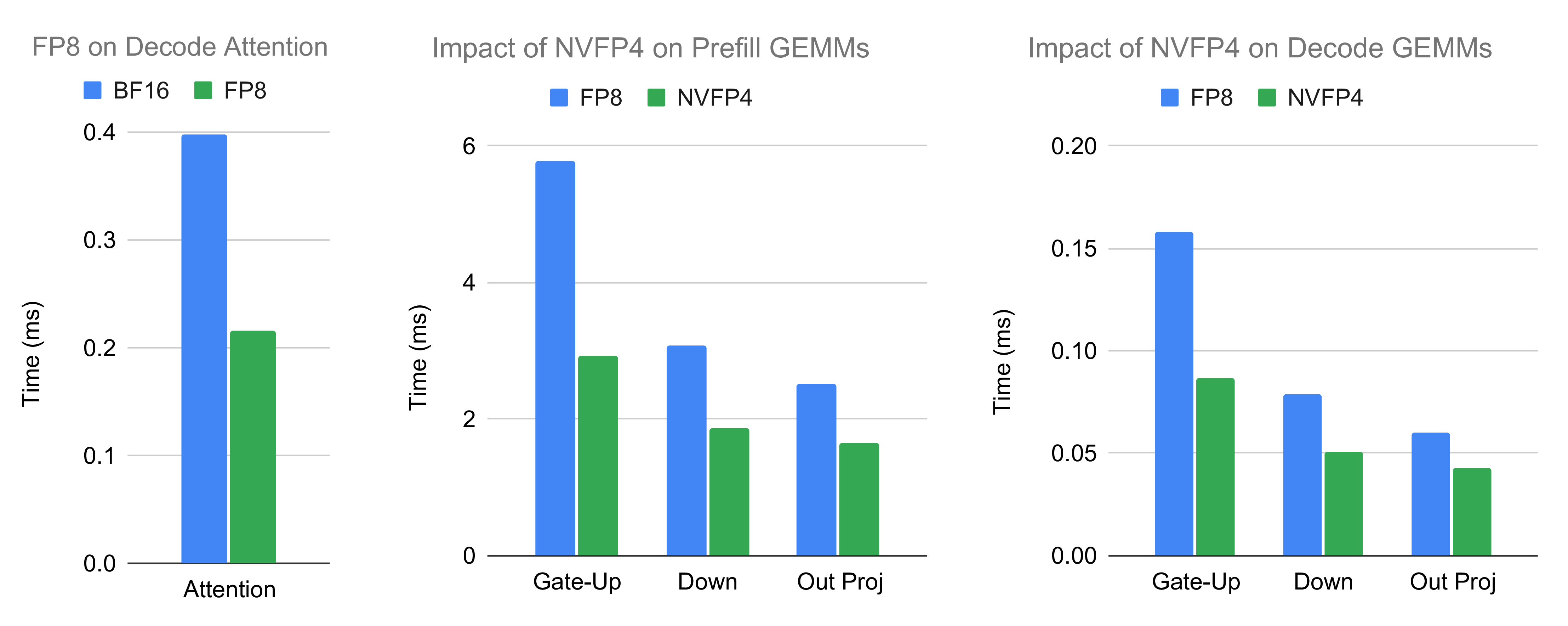
In this subsection, we examine the effects when changing from standard precision to low precision kernels. More specifically, we consider both the attention kernel and the GEMM kernels. For the latter, we consider the gate-up GEMM in MoE, the down GEMM in MoE, as well as the output projection GEMM which is in attention but is also time-consuming. For simplicity, we only consider one typical case.
As can be seen in the figure below, lowering the precision speeds up the related kernels to a great extent. For the case under test, attention is 1.8x faster and GEMM is up to 1.9x faster. Another improvement, which is not visible from the kernel perspective, is the increased number of KV cache tokens, which leads to larger batch sizes and thus improved performance.
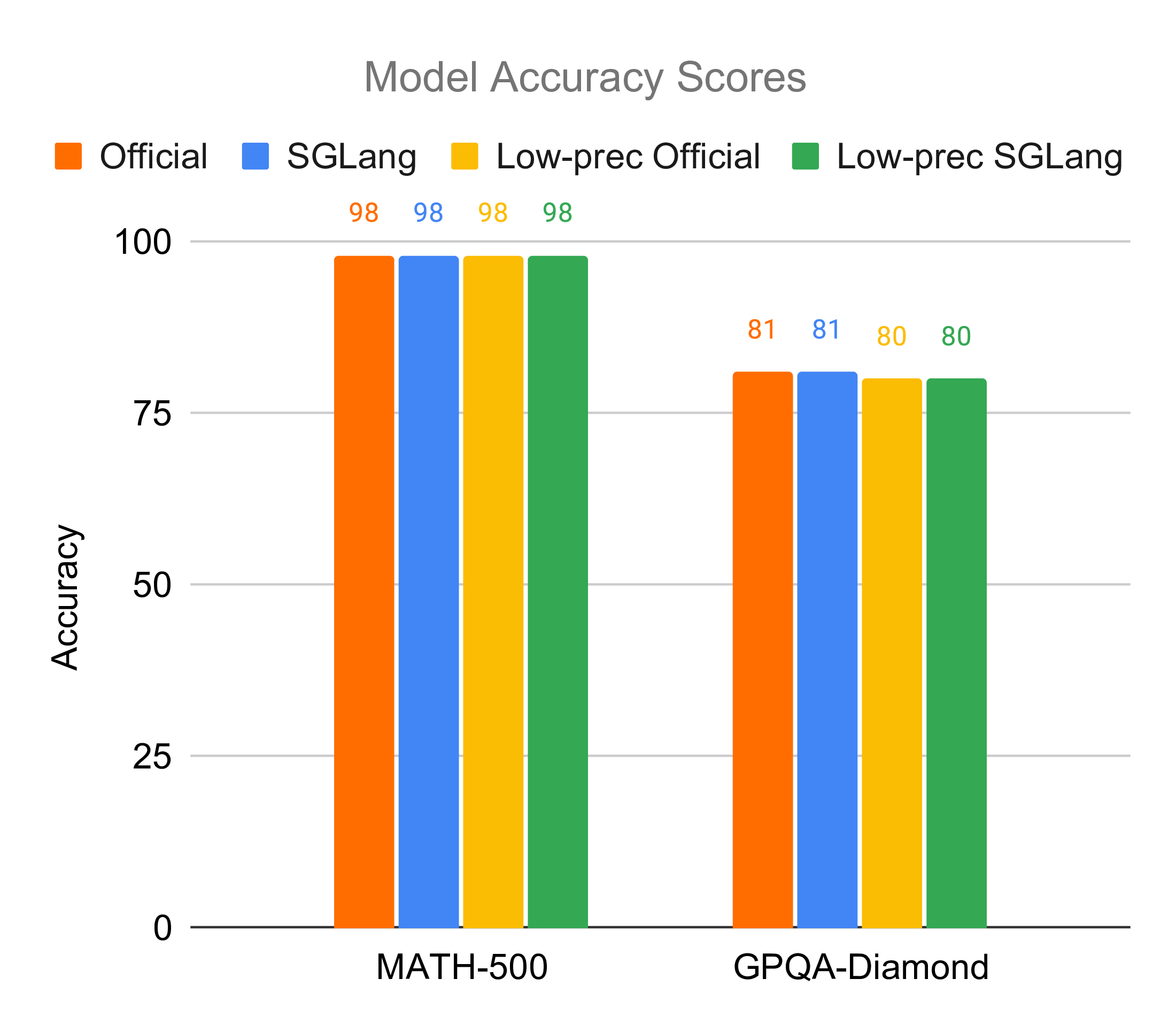
Accuracy
Post-training quantization (PTQ) inevitably loses information, thus it remains a question whether NVFP4 will result in performance on par with the original model. Theoretically speaking, NVFP4 chooses a small block size (16) and uses FP8 as the scaling factor data type, making it able to represent the original information with as little loss as possible. Experimentally, we observe that the results, consistent with NVIDIA’s official checkpoint for NVFP4, have tiny accuracy changes:
Future Work
Though our implementation has demonstrated significant performance boosts, there are some remaining areas for future improvements:
- Multi-Token Prediction (MTP) with Overlap Scheduler: It will be beneficial for decoding, especially when the batch size is small for kernels, or when the attention memory access pressure is high. The ongoing PR can be tracked here.
- Kernel Optimizations: There is still room for improvements for some kernels to fully utilize the hardware.
- More Models: Other powerful models, either existing or to be released, will also be optimized, such as Kimi-K2, Qwen, and GLM 4.5.
- OME for Easier Usage: OME is a Kubernetes operator for enterprise-grade management and serving of LLMs, which simplifies the deployment and operations of the model.
Acknowledgement
The GB200 optimizations would not have been possible without the collective efforts of the SGLang community. Special thanks to the SGLang team, FlashInfer team, Mooncake team, NVIDIA DevTech team, NVIDIA Enterprise Product team, NVIDIA DGX Cloud team, and the Dynamo team for driving this forward together! And we’ll continue pushing performance optimizations and actively working on adapting SGLang to upcoming hardware platforms, so the community can benefit from every new generation of acceleration.