Together with SGLang: Best Practices for Serving DeepSeek-R1 on H20-96G
Introduction
Operationalizing scaled Mixture-of-Experts (MoE) models such as DeepSeek-R1 requires a careful balance of latency, throughput, and cost. The challenge is especially acute on hardware with asymmetric performance profiles—for example, the H20 GPU, which offers high memory bandwidth but comparatively low compute throughput. Our goal was to design a serving stack that meets the stringent SLAs typically achieved on high-end GPUs while leveraging the H20’s cost advantages. This report outlines the practices we used to reach that goal. We introduce a hardware-aware deployment strategy that departs from common practice, together with a set of systems and kernel-level optimizations:
- Hardware-aware parallelization: single-node TP-8 for prefill and small-scale EP-16 for decode, meeting latency targets and reducing fault domains.
- Kernel-level optimizations: FlashMLA-FP8 and DeepGEMM swapAB to maximize compute throughput on H20.
- Scheduling and load balancing: Single-Batch Overlap (SBO) to boost small-batch throughput, plus an asynchronous Expert Affinity Load Balancer to minimize cross-node communication.
- Lightweight observability: a purpose-built diagnostics stack to quickly identify and resolve bottlenecks in distributed MoE serving.
Our experiments demonstrate that, with our deployment strategy, each node achieves 16.5k input tokens per second and 5.7k output tokens per second on 4096-token input sequences. To the best of our knowledge, this represents the state-of-the-art(SOTA) performance on H20. Furthermore, our work constitutes the first comprehensive study of H20, encompassing deployment, optimization, and large-scale industrial practice.
Challenges with H20
Why H20 Matters
H20 GPUs are widely available, enabling Ant Group to operate clusters at very large scale. At this level, even a modest throughput improvement can translate into significant daily cost savings.
Comparison: H20 vs. H800
| Spec | H20-96G | H800-80G |
|---|---|---|
| FP8 Compute | 296 TFLOPS | 1979 TFLOPS |
| FP16/BF16 Compute | 148 TFLOPS | 989 TFLOPS |
| Memory Capacity | 96 GB | 80 GB |
| Memory Bandwidth | 4000 GB/s | 3352 GB/s |
| NVLink Bandwidth | 900 GB/s | 400 GB/s |
| RDMA NIC Bandwidth | 4 × 400 Gb/s | 8 × 400 Gb/s |
H20 offers larger memory (96 GB), higher memory bandwidth (4000 GB/s), and over 2× NVLink bandwidth (900 GB/s) compared to H800. However, it comes with much weaker compute performance and lower RDMA NIC bandwidth.
Crucially, inference—especially decode phase—is often memory-bound, making H20’s high memory bandwidth and capacity particularly advantageous. Building on these strengths, we designed a series of optimizations to maximize inference throughput.
Solution: Optimizations and Strategies on H20
Deployment Strategy

Prefill
- SLA: Prefill is compute-intensive, and multi-node DP+EP can inflate time-to-first-token (TTFT), often violating SLAs. A single-node TP setup keeps TTFT within target.
- Elastic Scaling: Prefill must scale in and out with the KV cache. Single-node TP makes scaling straightforward, while multi-node DP+EP complicates resource and cache management.
Decode
- Hardware Characteristics: H20 trades compute for larger memory and higher NVLink bandwidth(compared with H800), enabling efficient KV-cache use and keeping MoE communication on high-bandwidth NVLink.
- Fault Radius: Smaller EP configurations limit the impact of decoding or GPU failures. With EP high-availability (HA) still maturing, smaller EP is safer and more reliable in production.
Optimizations
Prefill

Observation
- MLA is costlier than MHA for long sequences.
- MoE latency was unexpectedly high despite lower computation
embed/mlp all reduce + RMSNorm + fused_qkv_a_proj_with_mqaintroduces redundant communication and computation in TP
Solution
- MHA/MLA: Introduced tunable parameter
se = extend × (extend + prefix)to select MHA or MLA based on batch size and sequence lengths. - MoE: Optimized
b_scalecalculation, refactored input access ofdown projwith TMA, and tuned configurations based on real expert distributions. - TP Optimization: Optimized
embed/mlp reduce scatter + RMSNorm + fused_qkv_a_proj_with_mqa + all gatherto reduce computation and communication.
Decode
Load Balance
Expert Affinity EPLB

Standard EPLB balances intra-GPU loads but overlooks correlations between experts, which often scatters frequently co-activated experts across nodes and increases cross-node communication overhead.
We extend EPLB by tracking top-k expert co-activations to build an expert affinity matrix. After intra-GPU load balancing, we adjust placement so that highly co-activated experts are kept within the same node, thereby reducing cross-node communication, delivering an additional ~5% performance gain over vanilla EPLB.
Asynchronous Dynamic Load Adjustment

Static EPLB tightly couples load balancing with inference. This coupling means that migration decisions block ongoing inference, leading to noticeable latency when expert placement changes are required.
We decouple load balancing from inference, allowing both to run in parallel without blocking. To minimize the impact of expert migration, we adopt a hierarchical transfer strategy, which ensures inference remains seamless during transfers. This approach achieves performance that matches or exceeds static EPLB while consistently maintaining a >70% load balance ratio.
Computation
FP8 MLA
BF16 FlashMLA achieves good performance but leaves optimization headroom, as memory transfers and compute are not fully overlapped and shared-memory usage remains heavy. Previous FP8 implementations (#54) improved throughput but still suffered from pipeline inefficiencies, layout mismatches, and coarse-grained tiling that limited performance and accuracy.
We implement end-to-end FP8 attention on Hopper (SM90), leveraging TMA for memory transfers and WGMMA for computation.
Two warp groups pipeline QK^T and PV to minimize shared-memory pressure and overlap compute with memory.
Compared to BF16 FlashMLA, this yields ~70% speedup by introducing FP8 Q/KV, WGMMA FP8, shared-memory reallocation, and removing redundant operations.
Over previous FP8 (#54), it delivers an additional ~5% gain through a refined TMA–WGMMA pipeline, ping-pong buffers (sP0/sP1, sVt0/sVt1), 128-bit STSM/LDSM for layout fixes, and fine-grained Q@K tiling with BF16 ROPE, fully aligned with the Hopper programming model.
SwapAB GEMM

On Hopper, WGMMA PTX impose constraints: N must be a multiple of 8 and M is fixed at 64.
This forces coarse tiling and can waste compute when M is small, irregular, or not aligned to 64.
As a result, boundary inefficiency, load imbalance, and high shared-memory pressure limit overall throughput, especially in MoE workloads with variable M.
We introduce swapAB, which remaps the problem’s M dimension onto WGMMA’s N dimension.
This enables smaller BLOCK_M (32) tiling for finer granularity and better resource utilization.
SBO (Single-batch-overlap)
Why not TBO
The performance benefit of TBO (Two-batch-overlap) in the Decode phase is limited on H20:
- Hopper architecture constraint: WGMMA’s
block_mis fixed at 64. With small-batch decoding, TBO introduces redundant MLP GEMM computations. Positive throughput gains appear only at large batch sizes (e.g., 64 or 128). - SLA limitations on H20: At these large batch sizes, low-compute hardware cannot meet SLA targets for TPOT, making TBO impractical in online serving.
How SBO works

To improve Decode throughput without violating SLA, Single Batch Overlap (SBO) is adopted in DeepSeek v3/R1 by modifying DeepEP and DeepGEMM. The design of these overlaps is driven by the alignment granularity between communication and computation.
We observe that in the communication-computation overlap, token packets often arrive out of order at the receiver due to factors like NIC multi-QP scheduling, network congestion and multi-path routing. This disorder disrupts the alignment with the wave-based granularity of GEMM computation, reducing overlap efficiency. Consequently, we overlap Dispatch Recv with the data-independent Shared Expert computation to maximize resource utilization.
Conversely, the computation-communication overlap is more straightforward. The Down GEMM sequentially generates a predictable, ordered data stream for the Combine Send. Leveraging this, we structure their interaction as a signal-synchronized Producer-Consumer model:
- For each local expert, a signal unit is allocated for every
block_mtokens. - The Down GEMM atomically increments the signal's value after completing parts of the computation.
- The Combine Send polls this signal unit and sends the corresponding
block_mtokens once the value reaches a threshold.
Observability

To identify and diagnose communication slowdowns in MoE models under expert-parallel (EP) deployment, we developed a lightweight workflow named DeepXTrace:
- Metrics Collection: Each node periodically records communication and computation metrics, which are aggregated to Rank 0 every 10 seconds for centralized logging.
- Anomaly Detection: Rank 0 constructs an
N×Nlatency matrix and applies z-score analysis to detect anomalies across rows, columns, and individual points. - Root Cause Analysis: Anomalies are categorized into computation delays, imbalanced expert distribution, or communication bottlenecks.
- Visualization (Web UI): Results are visualized as a heatmap, making it easy to quickly spot slow ranks or links and guide targeted optimization.
Performance: Make H20 Great in Real World Inference
SGLang version: v0.5.2
Prefill
Environment
Deployment strategy: The Prefill instance is deployed on a 1-node setup (8× H20 GPUs). The following configuration serves as the Base (BF16 + fa3):
--tp-size 8
--Attention-backend fa3
Benchmarking: Performance is benchmarked using sglang.bench_serving with the following base configuration:
--backend sglang
--dataset-path /path/to/ShareGPT.json
--num-prompt 512
--random-input 4096
--random-output 1
--dataset-name random
--random-range-ratio 1
Metrics: We obtain the Input token throughput directly from the return results of sglang.bench_serving, and normalize the results to a per-GPU basis.
Performance improvements
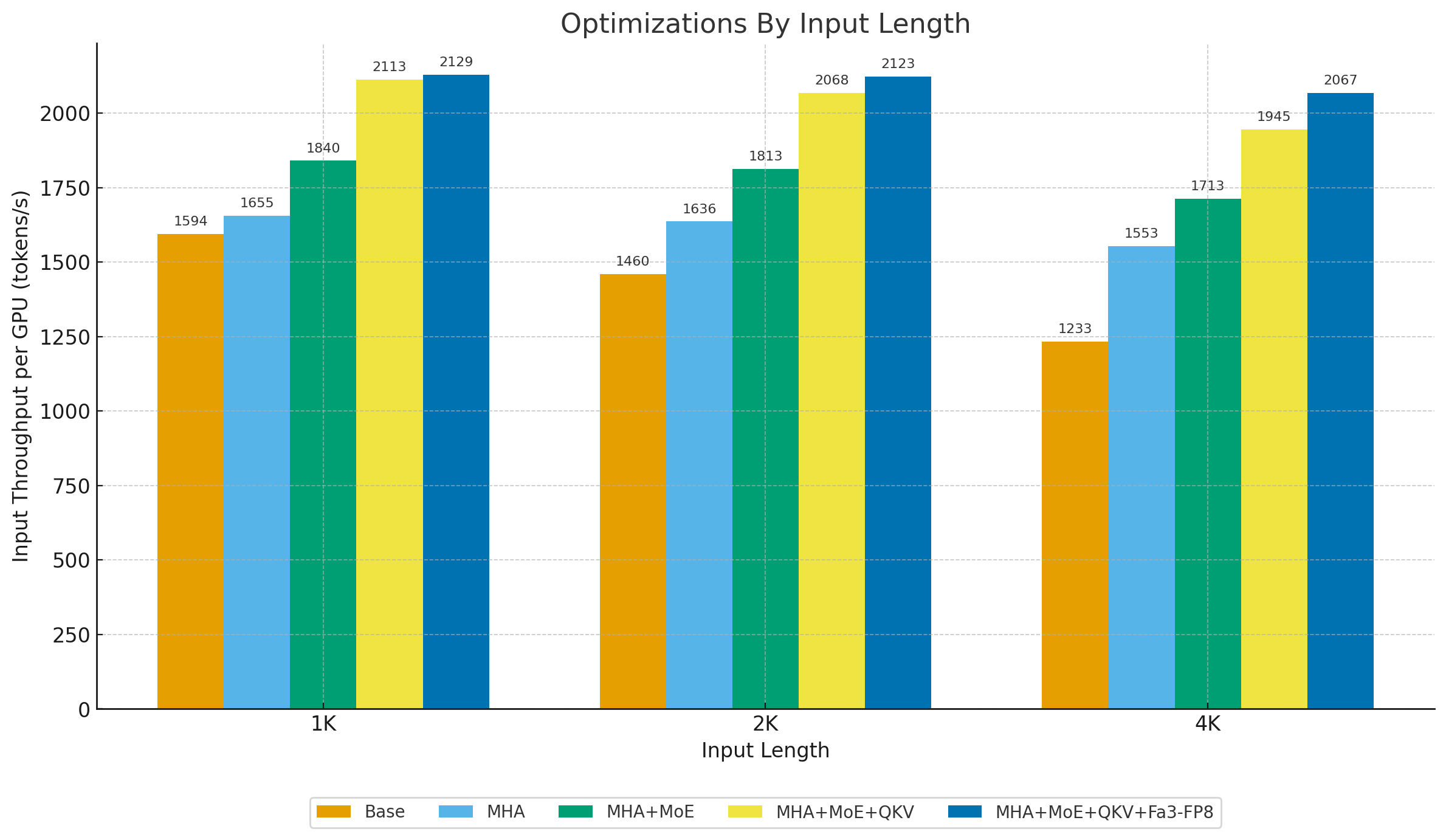
Sequence Length
Throughput generally rises from 1K to 2K as overhead is amortized, then decreases at 4K as memory pressure dominates.
Optimizations
- MHA: Provides modest gains at longer sequence lengths (2K, 4K), but shows no measurable benefit at 1K.
- MoE: Yields consistent improvements across all sequence lengths.
- QKV: Delivers additional throughput improvements, especially at longer sequence lengths, and helps narrow the performance gap between short and long sequences.
- Fa3-FP8: By introducing FP8 quantization in the attention module, throughput is further boosted, most notably at 2K and 4K sequence lengths.
Decode
Environment
Deployment strategy: The Decode instance is deployed on a 2-node setup (16× H20 GPUs). The following configuration serves as the Base (BF16 + MTP):
--tp-size 16
--dp-size 16
--enable-dp-attention
--enable-deepep-moe
--deepep-mode low_latency
--speculative-algorithm NEXTN
--speculative-num-steps 1
--speculative-eagle-topk 1
--speculative-num-draft-tokens 2
Benchmarking: Performance is benchmarked using sglang.bench_serving with the following base configuration:
--backend sglang
--dataset-path /path/to/ShareGPT.json
--random-input 4096
--random-output 1536
--dataset-name random
--random-range-ratio 1
Metrics: During stress testing, batch size is increased step by step. Therefore, raw results from sglang.bench_serving do not accurately reflect throughput at a given batch size. Instead, we parse the logs for Decode batch entries and compute the median throughput from 100 samples at the same batch size, which we report as the representative value.
Performance improvements
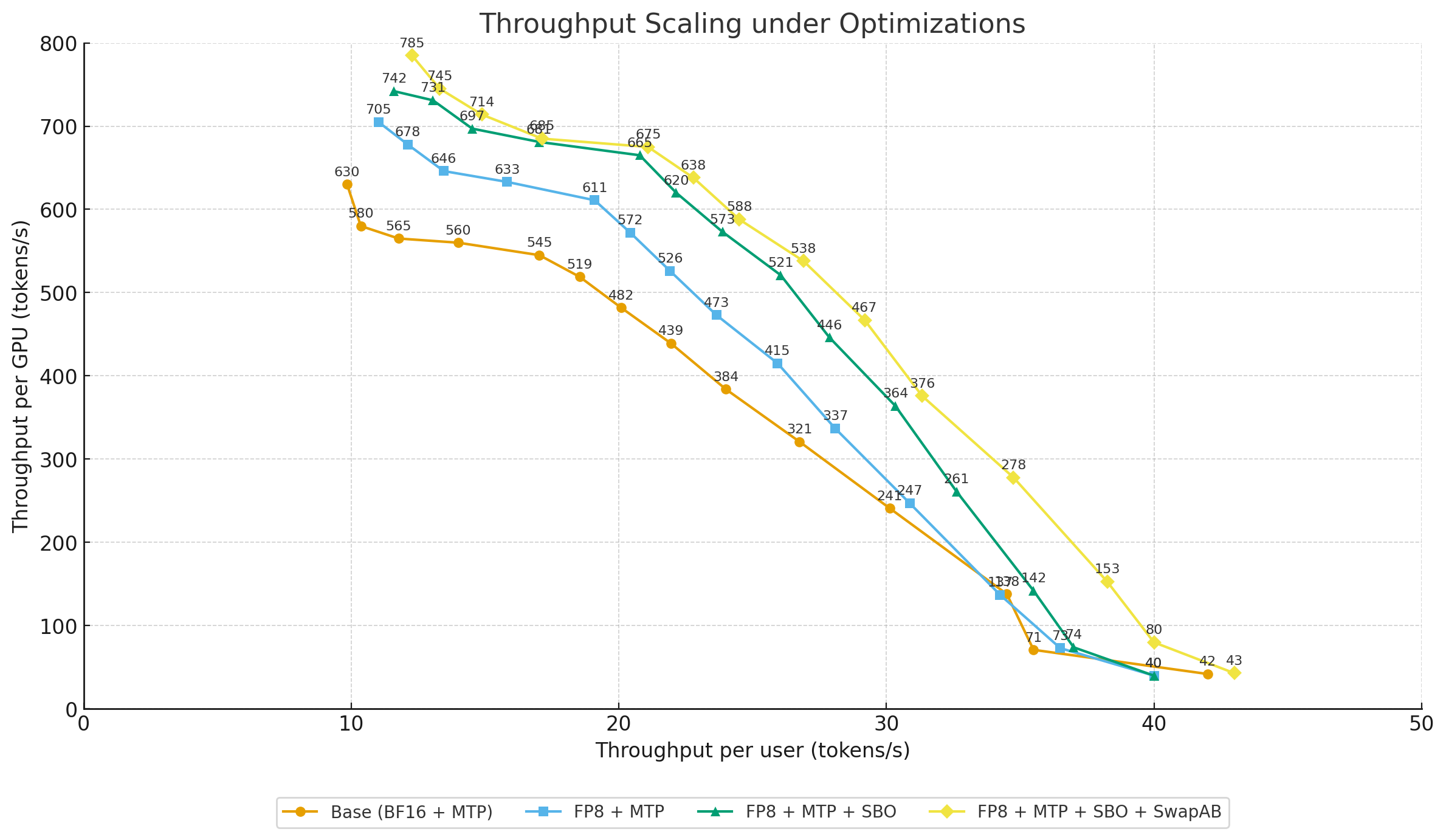
Batch-size
As the batch size increases, per-GPU throughput rises steadily. However, at larger batch sizes the gains taper off as both computation and communication begin to saturate.
Optimizations
- FP8 MLA: Reduces attention compute cost. Benefits are limited at small batch sizes; at larger batch sizes—where attention dominates—throughput improves by 16.9% at BS=56 over the baseline.
- SwapAB Gemm: Enables finer-grained tiling to improve boundary efficiency and concurrency. Clear gains at small/medium batches—+8.1% at BS=2 and +7.7% at BS=4—with incremental benefits of ≈2% at larger batches.
- SBO: Boosts resource utilization by overlapping computation with communication. As the batch grows, overlap becomes more effective, delivering +8%–10% improvement in the BS=20–56 range.
Investigation for EP size
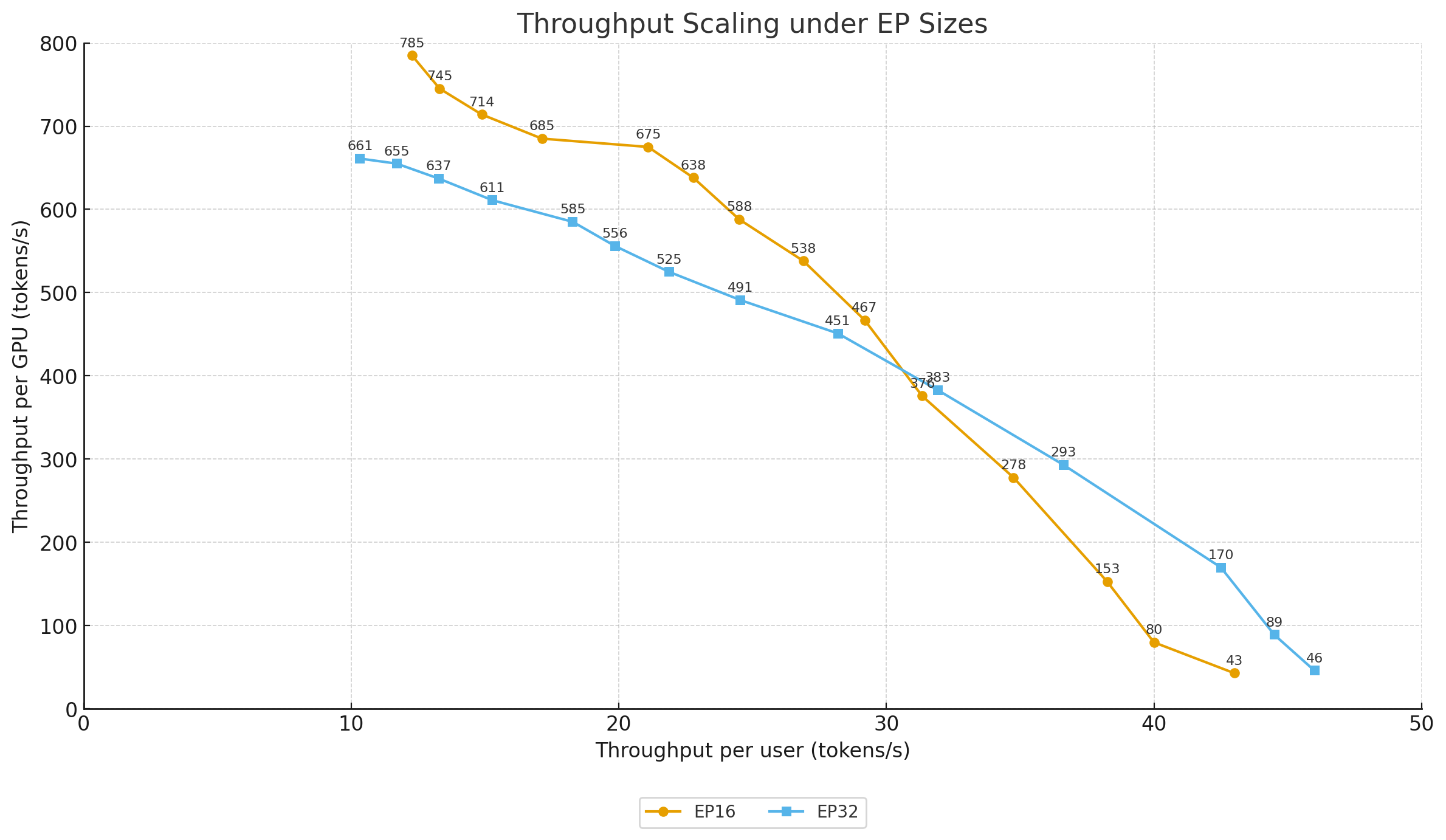
- Batch-size < 16: EP32 outperforms EP16. A larger EP size reduces the number of experts per GPU, which significantly cuts memory access overhead. While sparser expert placement slightly increases communication cost, the memory savings dominate, resulting in higher throughput (e.g., at BS=8, EP32 delivers 293 tokens/s vs. 278 tokens/s for EP16).
- Batch-size ≥ 16: EP16 pulls ahead of EP32. At larger EP sizes, cross-GPU communication dominates. With DeepEP, ~50% of MoE traffic stays on NVLink at EP16 but only ~25% at EP32, forcing more inter-node transfers and raising latency. As a result, throughput drops (e.g., at BS=32, EP16 achieves 675 tokens/s vs. 585 tokens/s for EP32).
Config for MTP
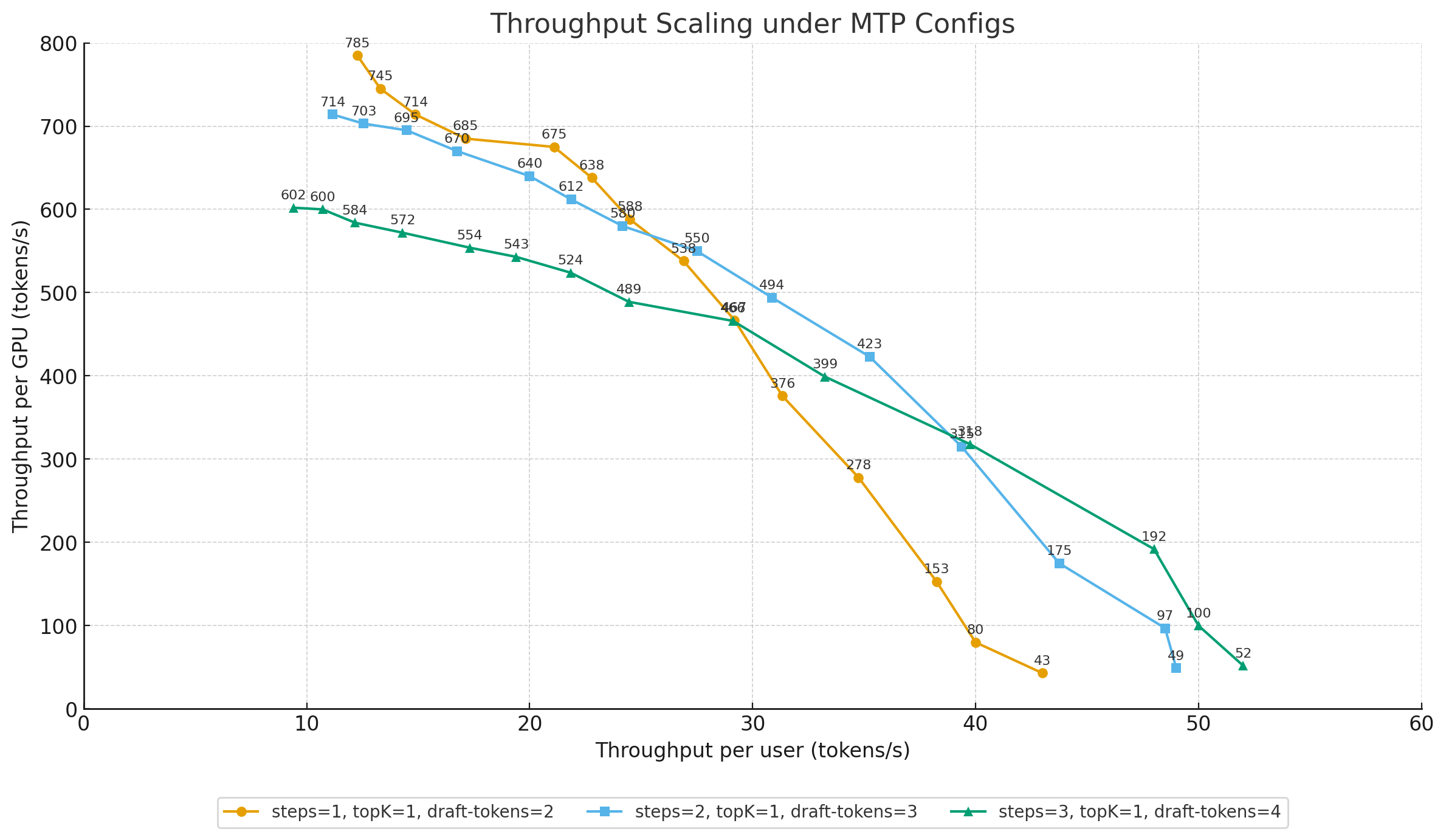
Draft vs. Accept Length
- (steps=1, topK=1, draft-tokens=2) → Accept length ≈ 1.8–1.9
- (steps=2, topK=1, draft-tokens=3) → Accept length ≈ 2.4–2.7
- (steps=3, topK=1, draft-tokens=4) → Accept length ≈ 2.9–3.3
Performance by Batch Size
- Small batches: On low-compute GPUs like the H20, resources are not fully utilized. Even though a higher draft token count reduces the accept length, it still boosts throughput. For example, at BS=1, throughput increases from 43 tokens/s (steps=1, topK=1, draft-tokens=2) to 52 tokens/s (steps=3, topK=1, draft-tokens=4), a ~21% gain.
- Large batches: With larger batches, the GPU becomes compute-bound. The shorter accept length from higher draft token settings leads to wasted compute and lower performance. At BS=32, throughput drops from 675 tokens/s (steps=1, topK=1, draft-tokens=2) to 554 tokens/s (steps=1, topK=1, draft-tokens=2), a ~18% loss.
Tiered Online Inference Serving
Our team powers all inference workloads at Ant Group.
To balance user experience with cost efficiency, we offer tiered SLA-based services:
- InferX Base: TTFT < 2s, TPOT < 70 ms
- InferX Pro: TTFT < 1.5s, TPOT < 50 ms
- InferX Max: TTFT < 1s, TPOT < 30 ms
Decode Deployment
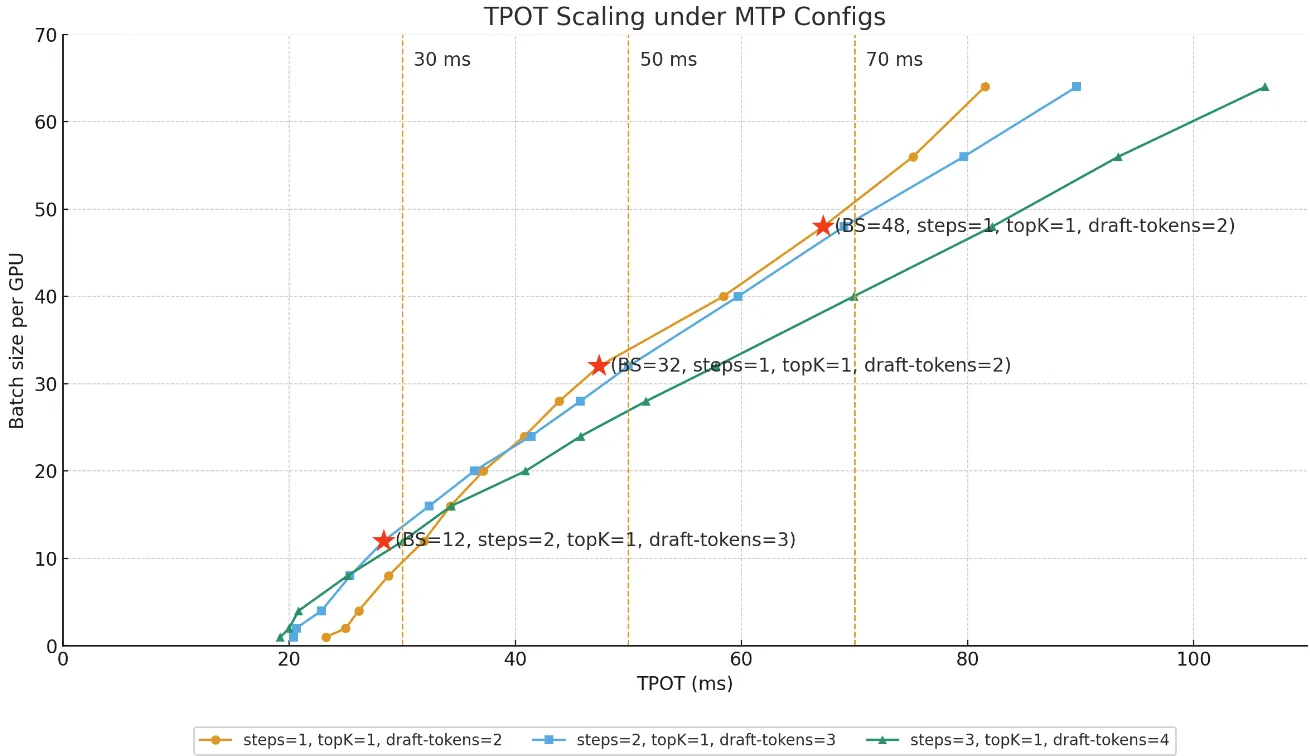
All Decode instances are deployed with a dual-node setup: Attention-DP16 + MoE-EP16.
To meet different SLA targets, we tune configurations along the latency–throughput curve, primarily adjusting batch size per GPU and MTP settings.
| Service Level | Batch-size/GPU | Steps | Eagle-topk | Draft-tokens | Throughput/GPU (tokens/s) |
|---|---|---|---|---|---|
| InferX Base | 48 | 1 | 1 | 2 | 714 |
| InferX Pro | 32 | 1 | 1 | 2 | 675 |
| InferX Max | 12 | 2 | 1 | 3 | 423 |
Prefill Deployment
As noted earlier, our Prefill instances are deployed with single-node TP8. To prevent TTFT violations caused by queueing delays, we run two Prefill instances for each model instance. Looking ahead, we plan to support dynamic scaling of Prefill instances to better adapt to workload fluctuations.
Reproducibility
Our experiments rely on multiple repositories (SGLang, DeepEP, DeepGEMM, FlashMLA), with several PRs still under review. For reproducibility, we will consolidate these into a dedicated test branch and provide a prebuilt image. Both will be made available in the antgroup/sglang repository.
Conclusion
Leveraging SGLang, we have achieved state-of-the-art serving performance for DeepSeek-R1 on H20 GPUs. By balancing throughput and latency, we provide deployment strategies optimized for diverse SLA requirements. Moving forward, we remain committed to aligning with community progress and contributing our practical optimizations back to the ecosystem.
Acknowledgements
We would like to extend our sincere gratitude to the following teams and collaborators for their invaluable support and contributions:
- SGLang Team and Community — for their outstanding work on the SGLang framework.
- AntGroup SCT and Inference Team — Yongfei Xu, Zhe Wang, Qianyu Zhang, Chun Huang, Xi Chen, Peipeng Cheng, Fakang Wang, Jianhao Fu and many others.