SGLang and NVIDIA Accelerating SemiAnalysis InferenceMAX and GB200 Together
The SGLang and NVIDIA teams have a strong track record of collaboration, consistently delivering inference optimizations and system-level improvements to ensure exceptional performance of the SGLang framework. Most recently, this collaboration has been centered on the NVIDIA Blackwell architecture, NVIDIA’s latest data center GPU. By leveraging key Blackwell features like FP8 attention, NVFP4 MoE, and PD-Disaggregated Expert Parallelism architecture, SGLang achieved breakthrough performance at high throughput. On an NVIDIA GB200 NVL72 system, SGLang served the DeepSeek R1 models at an incredible 26k input and 13k output tokens per second per GPU for prefill and decode, respectively. This milestone represents a new level of cost and power efficiency at scale.
The results of this joint effort were further demonstrated in SGLang’s performance at the newly launched SemiAnalysis InferenceMAX v1 benchmark. InferenceMAX is a continuous benchmarking framework that runs inference tests across different input/output configurations and publishes updated daily results.
Running the DeepSeek R1 model on Blackwell GPUs (GB200/B200) with SGLang showed up to a 4x performance gain compared to previous generation Hopper GPUs (H100/H200). These gains were consistently observed across the entire Pareto frontier, which evaluates the critical trade-off between latency and throughput.
SemiAnalysis InferenceMAX Benchmark
LLM inference performance is driven by two pillars: hardware and software. While hardware innovation drives step-function improvements, software evolves daily, delivering continuous performance gains. The SemiAnalysis InferenceMAX™ benchmark was designed to capture this dynamic. It runs a suite of benchmarks every night on hundreds of chips, continually re-evaluating the world’s most popular open-source inference frameworks and models to track real performance in real-time. A live dashboard is available to the public at inferencemax.ai.
A core goal of InferenceMAX™ is to provide benchmarks that reflect the full spectrum of possibilities across different GPUs, inference engines, and workloads. To ensure server configurations reflect real-world deployments, the benchmark organizers ask hardware vendors to submit configurations that align with their documented best practices.
Notably, SGLang was selected by the benchmark as the default inference engine for running DeepSeek models on both NVIDIA and AMD hardware, a testament to its highly specialized optimizations for these state-of-the-art models.
Below is a figure presenting the results for a configuration of 1k input tokens and 8k output tokens, highlighting the performance on Blackwell.
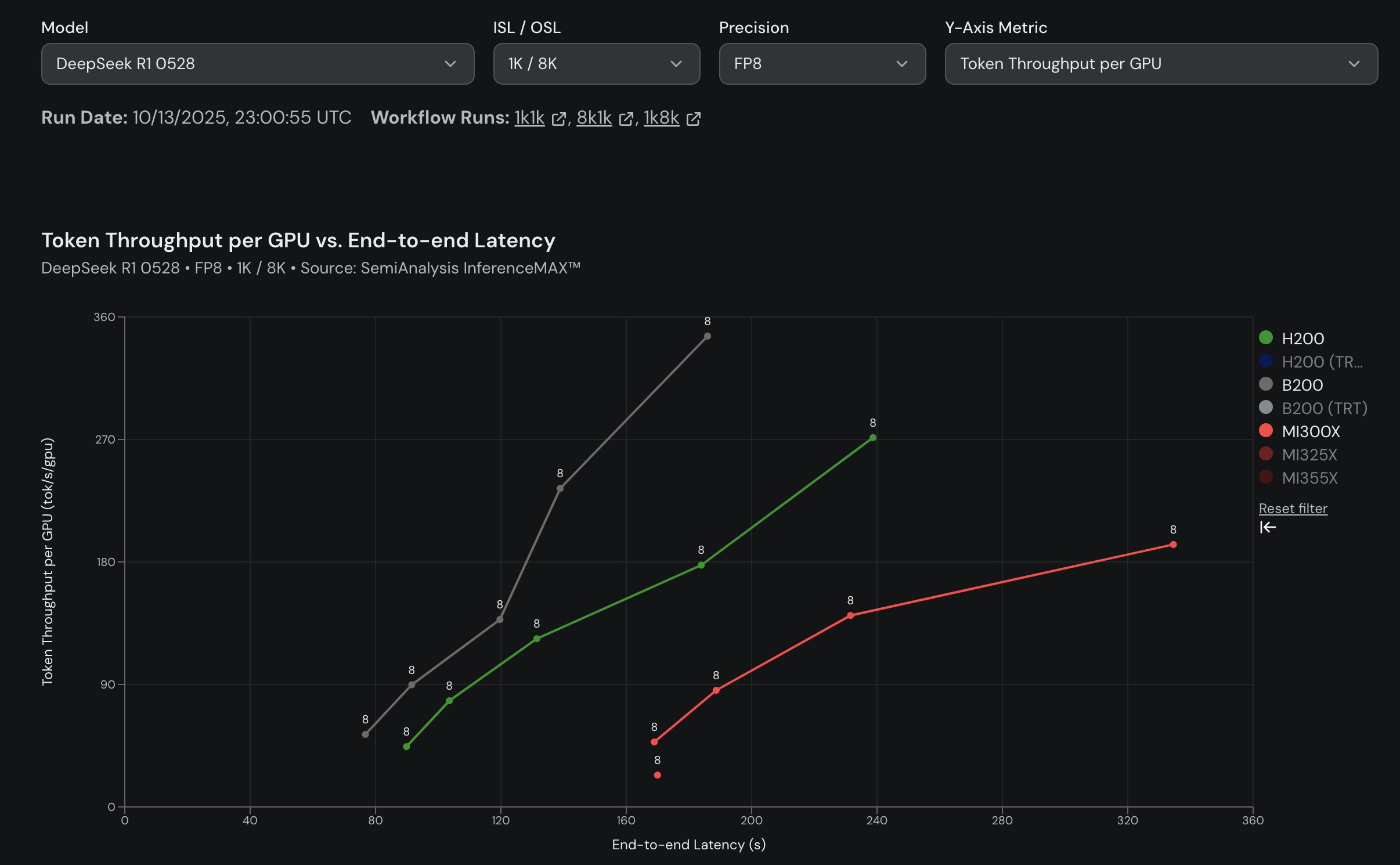
Figure 1: SGLang's Performance on Different Hardware Platforms. (Source: https://inferencemax.ai/)
SGLang Optimizations for Large-Scale Mixture-of-Expert Models
The performance gains demonstrated are the result of deep, system-level optimizations tailored for large-scale Mixture-of-Experts (MoE) models.
Prefill-Decode Disaggregation and Large-Scale Expert Parallelism
LLM inference is a two-phase process: a compute-intensive Prefill phase to process the input prompt, and a memory-intensive Decode phase to generate output tokens. Handling these together in a unified engine creates inefficiencies like prefill batches interrupting decode streams.
To solve this, SGLang implements Prefill-Decode (PD) Disaggregation, which separates the two stages into distinct engines, allowing for tailored scheduling and optimization for each. This architecture is crucial for efficiently implementing Large-Scale Expert Parallelism (EP), especially when using communication libraries like DeepEP. DeepEP uses different dispatch modes for prefill (high throughput) and decode (low latency), making a unified engine incompatible. By disaggregating, SGLang can leverage the optimal DeepEP mode for each phase, maximizing overall system efficiency.
Blackwell-Specific Kernel Optimizations
Our collaboration with NVIDIA enabled us to develop and integrate highly optimized kernels that fully exploit the new capabilities of the Blackwell architecture:
- FP8 Attention: Using FP8 precision for the KV cache halves memory access pressure during decoding and enables the use of faster Tensor Core instructions. This not only speeds up attention kernels but also allows for larger batch sizes and longer sequences.
- NVFP4 GEMM: The new NVFP4 precision for MoE experts and other GEMMs reduces memory bandwidth, leverages the powerful FP4 Tensor Core, and halves the communication traffic for token dispatching. This reduces weight memory, freeing up space for a larger KV cache.
- Computation-Communication Overlap: The significantly increased communication bandwidth on Blackwell systems allows for a more fine-grained approach to overlapping communication with computation, hiding communication latency more effectively.
- Optimized Kernels: We integrated a suite of new and optimized kernels, including NVIDIA Blackwell DeepGEMM, FlashInfer kernels for NVFP4 GEMM and FP8 attention, Flash Attention CuTe, and CUTLASS MLA, all rewritten to leverage Blackwell's new architectural features like TMA and cluster launch control.
To learn more, please see our detailed technical blog posts:
- Deploying DeepSeek with PD Disaggregation and Large-Scale Expert Parallelism on 96 H100 GPUs
- Deploying DeepSeek on GB200 NVL72 with PD and Large Scale EP (Part I): 2.7x Higher Decoding Throughput
- Deploying DeepSeek on GB200 NVL72 with PD and Large Scale EP (Part II): 3.8x Prefill, 4.8x Decode Throughput
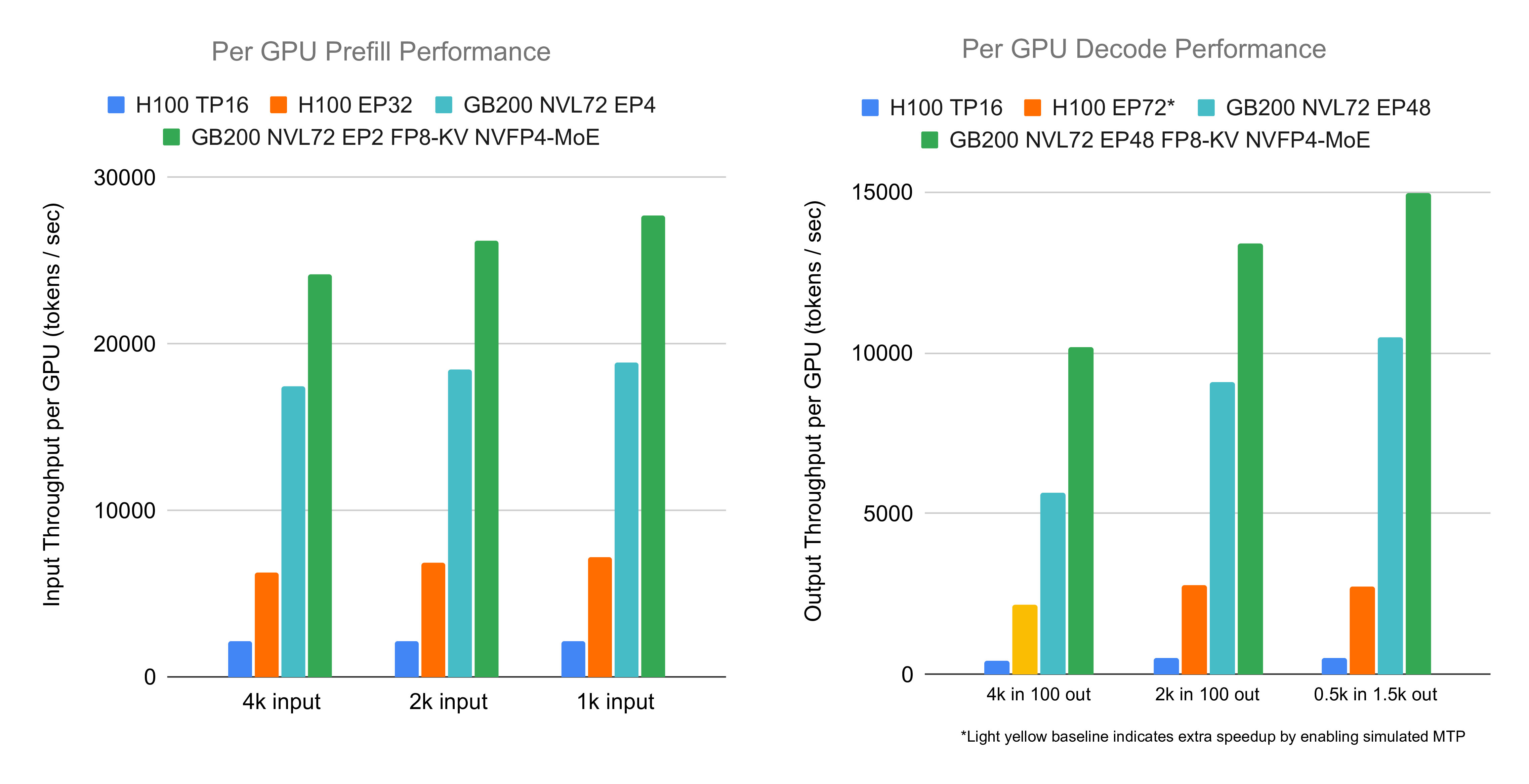
Figure 2: SGLang's Performance with Prefill-Decode Disaggregation and Expert Parallelism. (source: https://lmsys.org/blog/2025-09-25-gb200-part-2/)
Future Collaborations
Going forward, we will strengthen our collaboration with the NVIDIA team on both the runtime and kernel levels. We will continue to optimize performance for the DeepSeek v3.2, GPT-OSS, and QWen model series on all the latest NVIDIA GPUs, from the compact DGX Spark to the full rack-scale supercomputers like the GB200 and GB300.
We also plan to work more closely with the SemiAnalysis team to make the InferenceMAX benchmark more systematic, reproducible, and reliable. We look forward to helping them set up and validate all of our rack-scale solutions.
Acknowledgements
We would like to thank everyone in the community that helped make this effort possible.
NVIDIA team: Trevor Morris, Kaixi Hou, Elfie Guo, Nicolas Castet, Faraz Khoubsirat, Ishan Dhanan, Shu Wang, Pavani Majety, Zihao Ye, Yingyi Huang, Alex Zhurkevich, Kushan Ahmadian, Pen Li, Juan Yu, Kedar Potar, Grace Ho, Lingjie Wu, Yiheng Zhang, Kyle Liang and many more
SGLang team: Jingyi Chen, Baizhou Zhang, Jiexin Liang, Qiaolin Yu, Yineng Zhang, Ke Bao, Liangsheng Yin, Jianan Ji, Ying Sheng
SemiAnalysis team: Dylan Patel, Kimbo Chen, Cam, and others