Optimizing GPT-OSS on NVIDIA DGX Spark: Getting the Most Out of Your Spark
We’ve got some exciting updates about the NVIDIA DGX Spark! In the week following the official launch, we collaborated closely with NVIDIA and successfully brought GPT-OSS 20B and GPT-OSS 120B support to SGLang on the DGX Spark. The results are impressive: around 70 tokens/s on GPT-OSS 20B and 50 tokens/s on GPT-OSS 120B, which is state-of-the-art so far, and makes running a local coding agent on the DGX Spark fully viable.
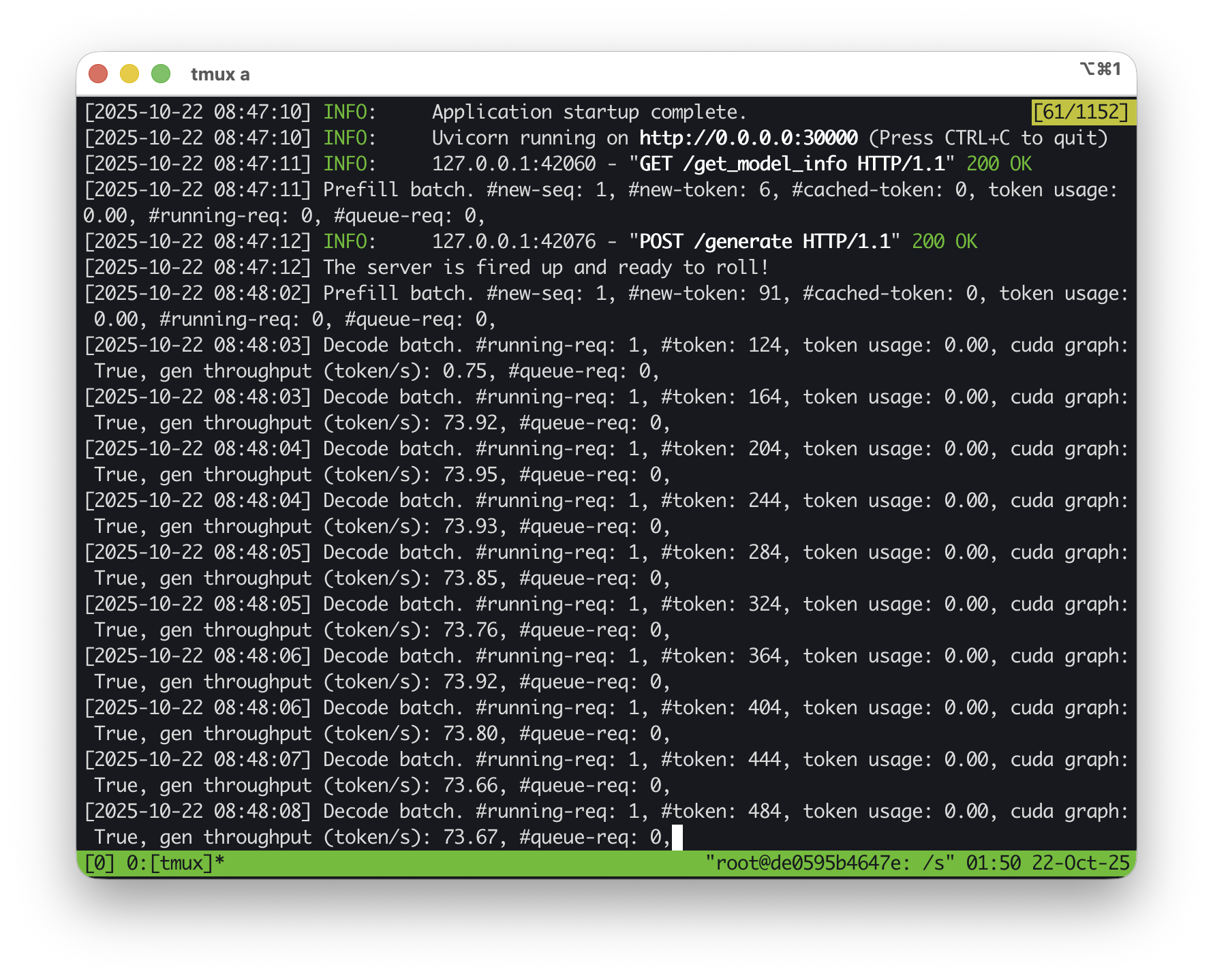
We’ve updated our detailed benchmark results here, and check out our demo video here.
In this post, you’ll learn how to:
- Run GPT-OSS 20B or 120B with SGLang on the DGX Spark
- Benchmark performance locally
- Hook it up to Open WebUI for chatting
- Even run Claude Code entirely locally via LMRouter
1. Preparing the Environment
Before launching SGLang, make sure you have the proper tiktoken encodings for OpenAI Harmony:
mkdir -p ~/tiktoken_encodings
wget -O ~/tiktoken_encodings/o200k_base.tiktoken "https://openaipublic.blob.core.windows.net/encodings/o200k_base.tiktoken"
wget -O ~/tiktoken_encodings/cl100k_base.tiktoken "https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken"
2. Launching SGLang with Docker
Now, launch the SGLang server with the following command:
docker run --gpus all \
--shm-size 32g \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface -v ~/tiktoken_encodings:/tiktoken_encodings \
--env "HF_TOKEN=<secret>" --env "TIKTOKEN_ENCODINGS_BASE=/tiktoken_encodings" \
--ipc=host \
lmsysorg/sglang:spark \
python3 -m sglang.launch_server --model-path openai/gpt-oss-20b --host 0.0.0.0 --port 30000 --reasoning-parser gpt-oss --tool-call-parser gpt-oss
Replace <secret> with your Hugging Face access token. If you’d like to run GPT-OSS 120B, simply change the model path to: openai/gpt-oss-120b. This model is roughly 6× larger than the 20B version, so it will take a bit longer to load. For best performance and stability, consider enabling swap memory on your DGX Spark.
3. Testing the Server
Once SGLang is running, you can send OpenAI-compatible requests directly:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many letters are there in the word SGLang?"
}
]
}'
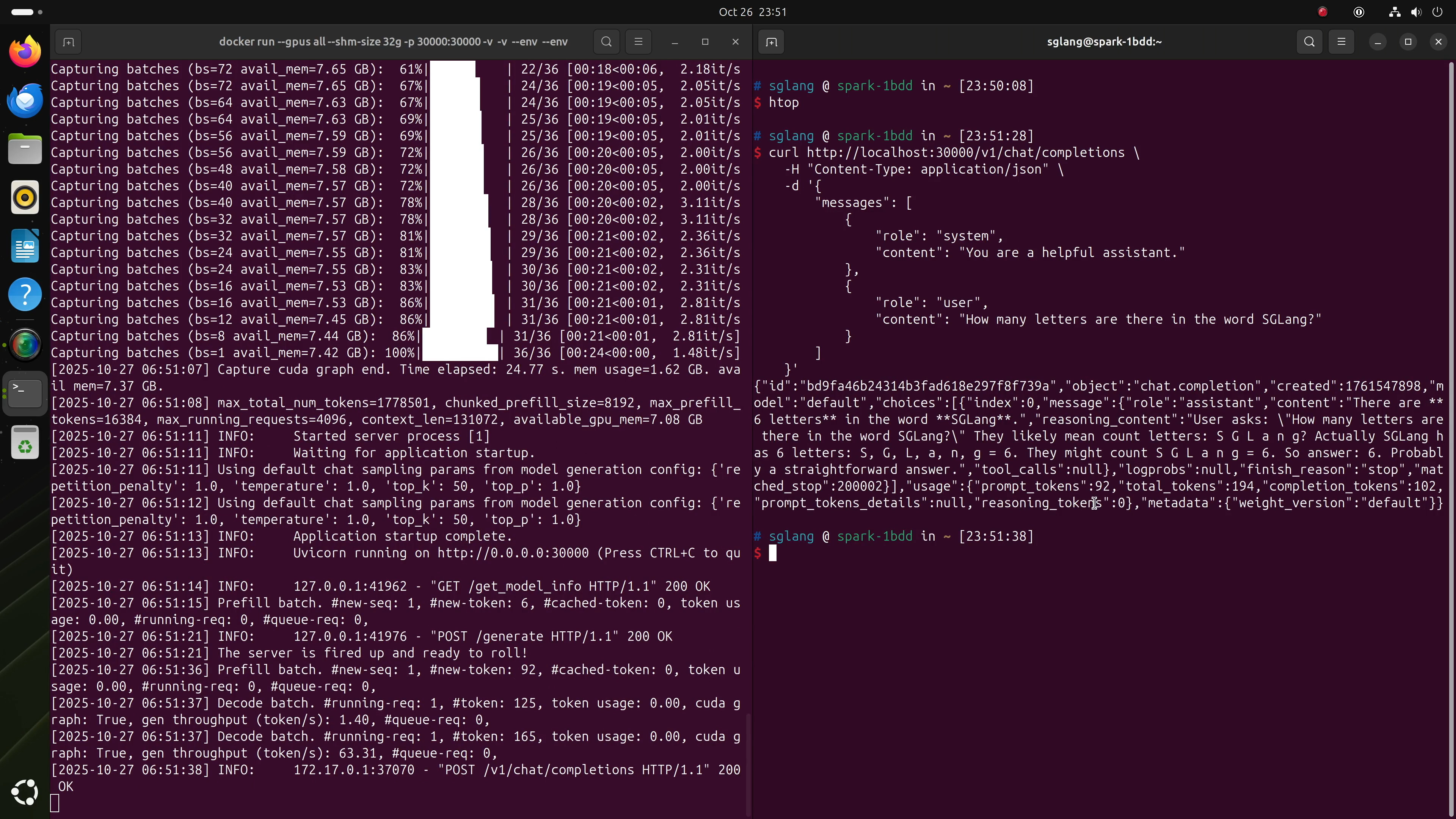
4. Benchmarking Performance
A quick way to benchmark throughput is to request a long output, such as:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Generate a long story. The only requirement is long."
}
]
}'
You should see around 70 tokens per second with GPT-OSS 20B under typical conditions.
5. Running a Local Chatbot (Open WebUI)
To set up a friendly local chat interface, you can install Open WebUI on your DGX Spark and point it to your running SGLang backend: http://localhost:30000/v1. Follow the Open WebUI installation instructions to get it up and running. Once connected, you’ll be able to chat seamlessly with your local GPT-OSS instance. No internet required.
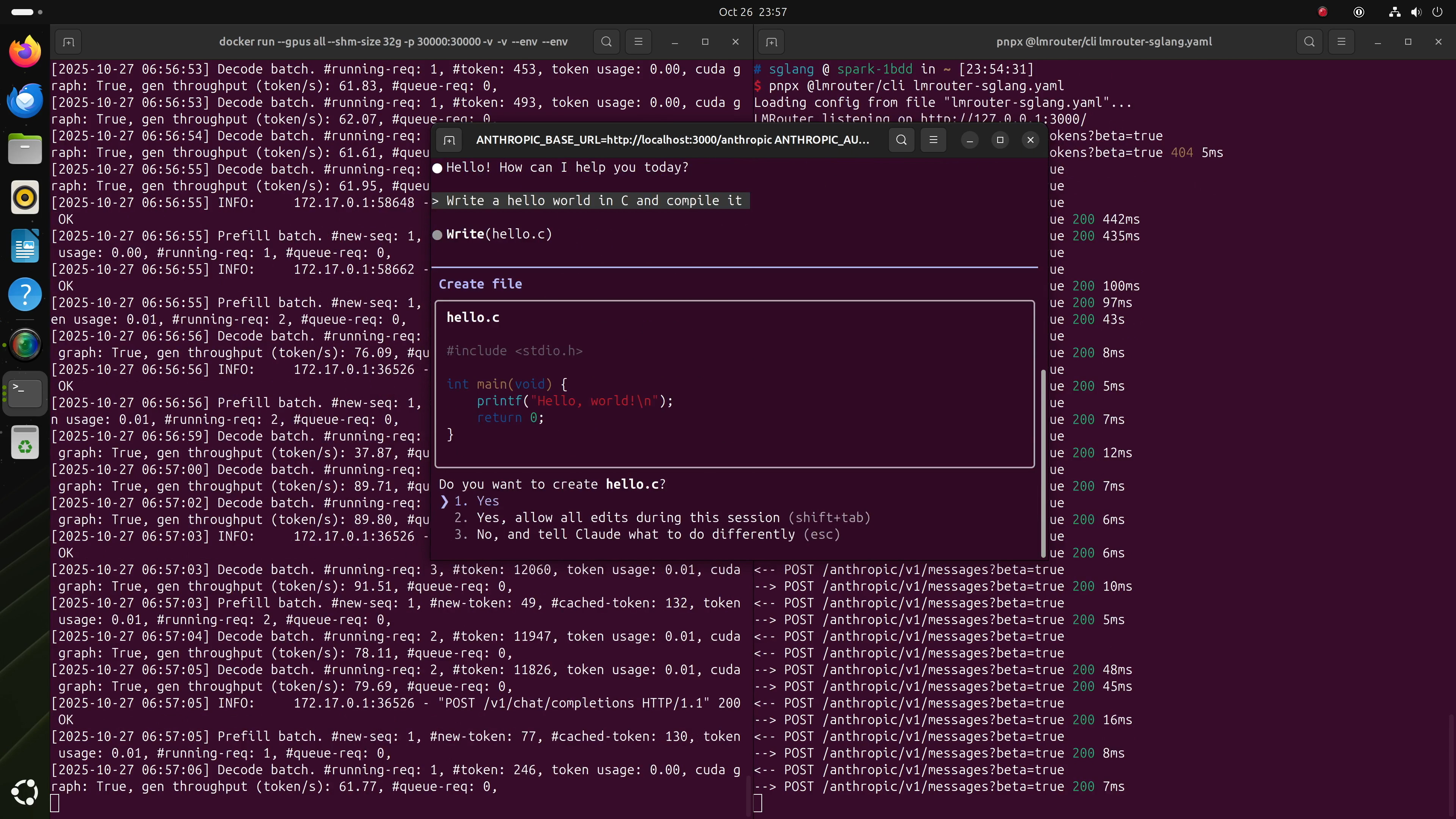
6. Running Claude Code Entirely Locally
With a local GPT-OSS model running, you can even connect Claude Code through LMRouter, which is able to convert Anthropic-style requests into OpenAI-compatible ones.
Step 1: Create the LMRouter Config
Save this file as lmrouter-sglang.yaml.
Step 2: Launch LMRouter
Install pnpm (if not already installed), then run:
pnpx @lmrouter/cli lmrouter-sglang.yaml
Step 3: Start Claude Code
Install Claude Code following its setup guide, then launch it as follows:
ANTHROPIC_BASE_URL=http://localhost:3000/anthropic \
ANTHROPIC_AUTH_TOKEN=sk-sglang claude
That’s it! You can now use Claude Code locally, powered entirely by GPT-OSS 20B or 120B on your DGX Spark.
7. Conclusion
With these steps, you can fully unlock the potential of the DGX Spark, turning it into a local AI powerhouse capable of running multi-tens-of-billion-parameter models interactively.