🚀 AutoRound Meets SGLang: Enabling Quantized Model Inference with AutoRound
Overview
We are thrilled to announce an official collaboration between SGLang and AutoRound, enabling low-bit quantization for efficient LLM inference.
Through this integration, developers can now quantize large models with AutoRound’s signed-gradient optimization and directly deploy them in SGLang’s efficient runtime, achieving low-bit model inference with minimal accuracy loss and significant latency reduction.
What Is AutoRound?
AutoRound is an advanced post-training quantization (PTQ) toolkit designed for Large Language Models (LLMs) and Vision-Language Models (VLMs). It uses signed gradient descent to jointly optimize weight rounding and clipping ranges, enabling accurate low-bit quantization (e.g., INT2 - INT8) with minimal accuracy loss in most scenarios. For example, at INT2 precision, it outperforms popular baselines by up to 2.1x higher in relative accuracy. At INT4 precision, AutoRound continues to hold a competitive edge in most cases. The image below provides an overview of the core algorithm in AutoRound.
Full technical details are presented in the AutoRound paper:
👉 Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs
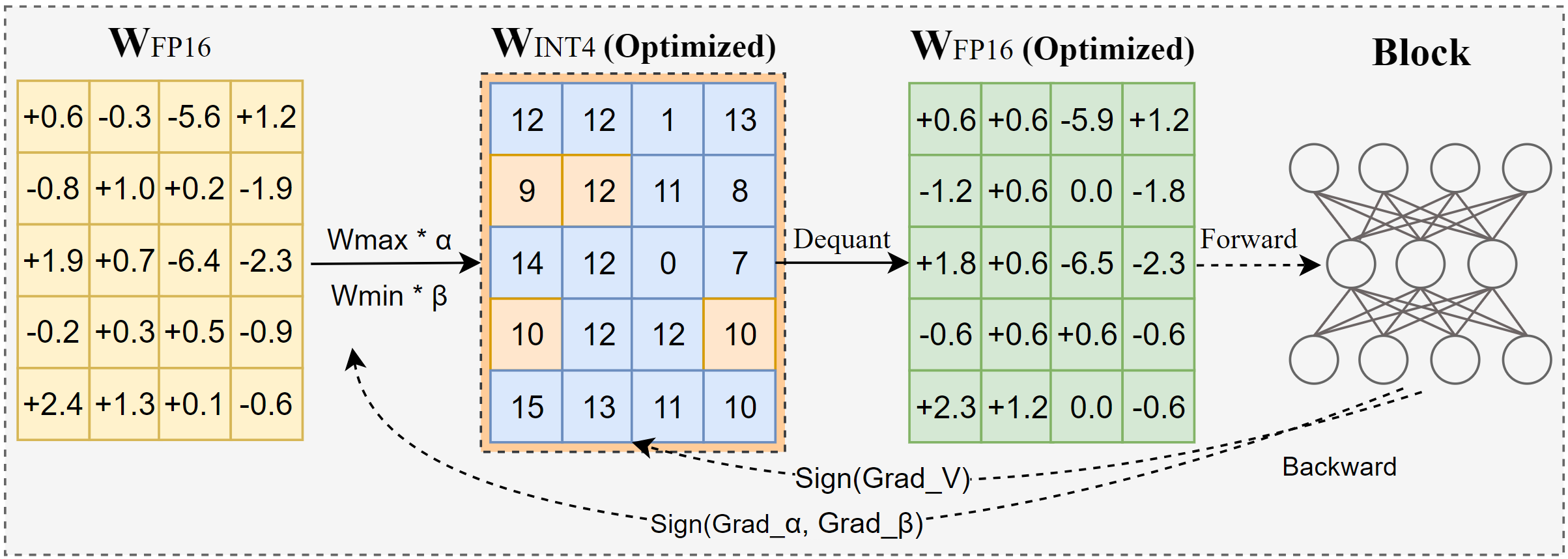
AutoRound algorithm overview
Despite its robust performance, AutoRound remains fast and lightweight—quantizing a 72B model takes only 37 minutes on a single GPU under light mode.
It further supports mixed-bit tuning, lm-head quantization, GPTQ/AWQ/GGUF format exports, and customizable tuning recipes.
AutoRound Highlights
AutoRound is not only focused on algorithmic innovation and exploration, but also widely recognized for its completeness in quantization engineering.
- Accuracy: deliver superior accuracy at low-bit precision
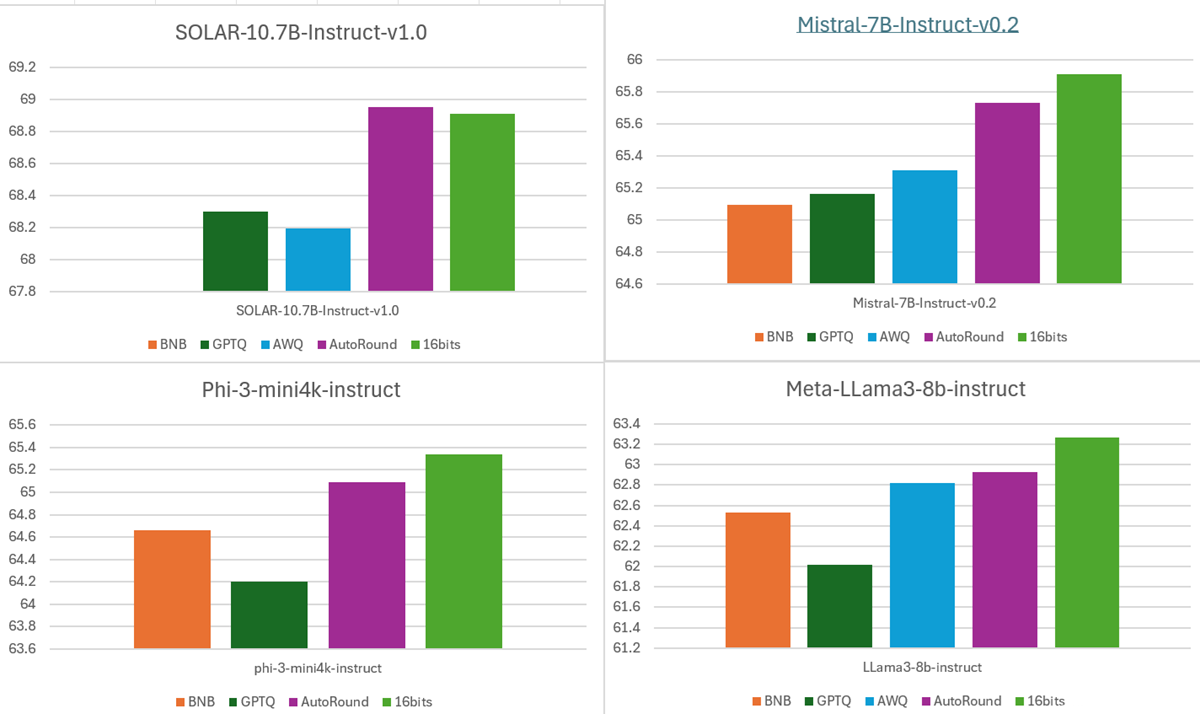
Average accuracy of 10+ tasks at INT4 weight
- Schemes: support weight-only quantization, weight & activation quantization, dynamic and static for activation quantization
- Mixed-bits: propose an effective algorithm to generate mixed-bits / other data types schemes in minutes
- Broad Compatibility:
- Support nearly all popular LLM architectures and over 10 vision-language models (VLMs)
- Support Devices: CPU, Intel GPU, CUDA
- Support Data Types: INT2 - INT8, MXFP4, NVFP4, FP8, and MXFP8
- Efficiency: Enables block-wise tuning to lower VRAM usage without sacrificing throughput yet fast

Quantization time cost comparison
- Community adoption:
- Work seamlessly with SGLang, TorchAO, Transformers, and vLLM
- Widely used by HuggingFace model hubs such as Intel, OPEA, Kaitchup, and fbaldassarri with approximately two million downloads
- Export Formats:
- AutoRound
- GPTQ
- AWQ
- GGUF
- Compressed-tensor (initial support)
Integration Overview
SGLang provides a next-generation inference runtime built for scalable, low-latency LLM deployment. Its multi-modal, multi-GPU, and streaming execution model enables both chat and agentic reasoning workloads with exceptional efficiency.
SGLang’s flexible architecture now offers native hooks for quantized model loading, unlocking AutoRound’s full potential for deployment.
1. Quantize with AutoRound
AutoRound automatically optimizes weight rounding and exports quantized weights that compatible with SGLang.
1.1 API Usage
# for LLM
from auto_round import AutoRound
model_id = "meta-llama/Llama-3.2-1B-Instruct"
quant_path = "Llama-3.2-1B-Instruct-autoround-4bit"
# Scheme examples: "W2A16", "W3A16", "W4A16", "W8A16", "NVFP4", "MXFP4" (no real kernels), "GGUF:Q4_K_M", etc.
scheme = "W4A16"
format = "auto_round"
autoround = AutoRound(model_id, scheme=scheme)
autoround.quantize_and_save(quant_path, format=format) # quantize and save
1.2 CMD Usage
auto-round \
--model Qwen/Qwen2-VL-2B-Instruct \
--bits 4 \
--group_size 128 \
--format "auto_round" \
--output_dir ./tmp_autoround
2. Deploying with SGLang
SGLang supports AutoRound-quantized models directly (Version>=v0.5.4.post2). It is compatible with SGLang-supported modeling architectures, including common LLM, VLM, and MoE models, and also supports inference and evaluation of AutoRound mixed-bit quantized models.
2.1 OpenAI-Compatible Inference Usage
from sglang.test.doc_patch import launch_server_cmd
from sglang.utils import wait_for_server, print_highlight, terminate_process
# This is equivalent to running the following command in your terminal
# python3 -m sglang.launch_server --model-path Intel/DeepSeek-R1-0528-Qwen3-8B-int4-AutoRound --host 0.0.0.0
server_process, port = launch_server_cmd(
"""
python3 -m sglang.launch_server --model-path Intel/DeepSeek-R1-0528-Qwen3-8B-int4-AutoRound \
--host 0.0.0.0 --log-level warning
"""
)
wait_for_server(f"http://localhost:{port}")
2.2 Offline Engine API Inference Usage
import sglang as sgl
llm = sgl.Engine(model_path="Intel/DeepSeek-R1-0528-Qwen3-8B-int4-AutoRound")
prompts = ["Hello, my name is"]
sampling_params = {"temperature": 0.6, "top_p": 0.95}
outputs = llm.generate(prompts, sampling_params)
for prompt, output in zip(prompts, outputs):
print(f"Prompt: {prompt}\nGenerated text: {output['text']}")
More flexible configurations and deployment options are waiting for you to explore!
Quantization Roadmap
AutoRound’s quantization benchmark results demonstrate robust accuracy retention at low precision. The results below highlight AutoRound’s strong advantages and potential in MXFP4, NVFP4, and mixed-bits model quantization. Note that the accuracy result is measured by average accuracy across lambada_openai, hellaswag, piqa, winogrande, and mmlu task.
As part of AutoRound roadmap, we plan to continue enhancing MXFP4 & NVFP4 accuracy for common models and auto mixed-bits quantization in the upcoming releases.
-
MXFP4 & NVFP4 Quantization. RTN (Round-to-nearest) algorithm is baseline, and 'alg_ext' option indicates experimental optimization algorithms enabled.
mxfp4 llama3.1-8B-Instruct Qwen2-7.5-Instruct Phi4 Qwen3-32B RTN 0.6212 0.6550 0.7167 0.6901 AutoRound 0.6686 0.6758 0.7247 0.7211 AutoRound+alg_ext 0.6732 0.6809 0.7225 0.7201 nvfp4 llama3.1-8B-Instruct Qwen2-7.5-Instruct Phi4 Qwen3-32B RTN 0.6876 0.6906 0.7296 0.7164 AutoRound 0.6918 0.6973 0.7306 0.7306 AutoRound+alg_ext 0.6965 0.6989 0.7318 0.7295 -
Auto MXFP4 & MXFP8 Mixed-Bits Quantization
Average bits Llama3.1-8B-I Qwen2.5-7B-I Qwen3-8B Qwen3-32B BF16 0.7076 (100%) 0.7075 (100%) 0.6764 (100%) 0.7321 (100%) 4-bit 0.6626 (93.6%) 0.6550 (92.6%) 0.6316 (93.4%) 0.6901 (94.3%) 4.5-bit 0.6808 (96.2%) 0.6776 (95.8%) 0.6550 (96.8%) 0.7176 (98.0%) 5-bit 0.6857 (96.9%) 0.6823 (96.4%) 0.6594 (97.5%) 0.7201 (98.3%) 6-bit 0.6975 (98.6%) 0.6970 (98.5%) 0.6716 (99.3%) 0.7303 (99.8%)
Conclusion
The integration of AutoRound and SGLang marks a major milestone in efficient AI model deployment. This collaboration bridges precision optimization and runtime scalability, allowing developers to move seamlessly from quantization to real-time inference with minimal friction. AutoRound’s signed-gradient quantization ensures high fidelity even at extreme compression ratios, while SGLang’s high-throughput inference engine unlocks the full potential of low-bit execution across CPUs, GPUs, and multi-node clusters.
Looking forward, we aim to expand support for advanced quantization formats, optimize kernel efficiency, and bring AutoRound quantization into** **broader multimodal and agentic workloads. Together, AutoRound and SGLang are setting a new standard for intelligent, efficient, and scalable LLM deployment.