Introducing Miles — RL Framework To Fire Up Large-Scale MoE Training
A journey of a thousand miles is made one small step at a time.
Today, we are releasing Miles, an enterprise-grade reinforcement learning framework tailored for large-scale MoE training and production workloads.
Miles is built on top of slime, the lightweight RL framework that has quietly powered many of today’s post-training pipelines and large MoE runs (including GLM-4.6). While slime proved that lightweight design works, Miles takes the next step: delivering the reliability, scale, and control needed for real-world enterprise deployments.
GitHub: radixark/miles.
Why Miles?
Every mile of progress begins with one well-placed step - slime it is. As a very lightweight and customizable RL framework, slime has been growing popular across the community. It has also been battle-tested in large MoE training, where it is used to train GLM-4.6. slime comes with a few elegant design principles:
Open-to-Use Performance
We provide native, structured support for SGLang and Megatron's full optimization stack, keeping pace with the rapid evolution of inference and training frameworks.
Modular Design
Key components—Algorithm, Data, Rollout, and Eval—are fully decoupled. You can plug in new agent types, reward functions, or sampling strategies with minimal code changes.
Built for Researchers
Every abstraction is readable and hackable. Algorithm researchers can modify importance sampling, rollout logic, or loss dynamics without digging into low-level code. We also provide inference-only and training-only debugging modes for fast diagnosis.
Community-Driven
slime evolved through real-world feedback from the LMSYS and SGLang communities, embodying what open collaboration across research and engineering can achieve.
What's New?
Miles builds on slime but focuses on new hardware (e.g., GB300), large-scale MoE RL, and production-grade stability. Recent additions include (most of which we've also upstreamed to slime):
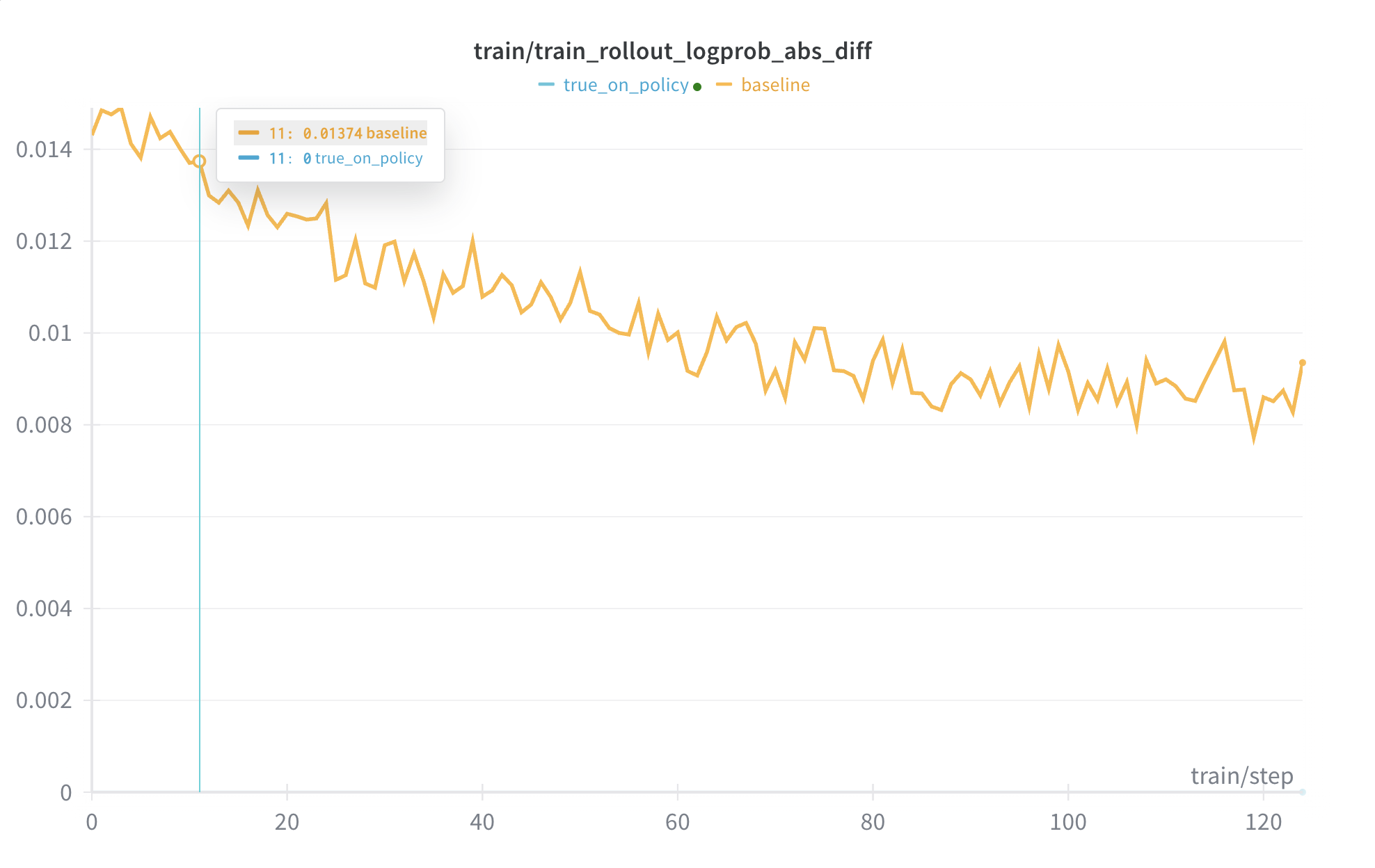
True On-Policy
Beyond deterministic inference (bitwise identical results), we now support true on-policy via an infrastructure approach.
- We've eliminated the mismatch between training and inference to exactuly 0 kl divergence.
- This uses Flash Attention 3, DeepGEMM, batch invariant kernels from Thinking Machines Lab, and
torch.compile. We also aligned numeric operations between training and inference.
Memory Improvements
To maximize performance without hitting OOM errors, we've made several updates:
- Added error propagation to avoid crashes on benign OOMs.
- Implemented memory margins to fix NCCL-related OOMs.
- Fixed excessive memory usage in FSDP.
- Added support for move-based and partial offloading, plus host peak memory savings.
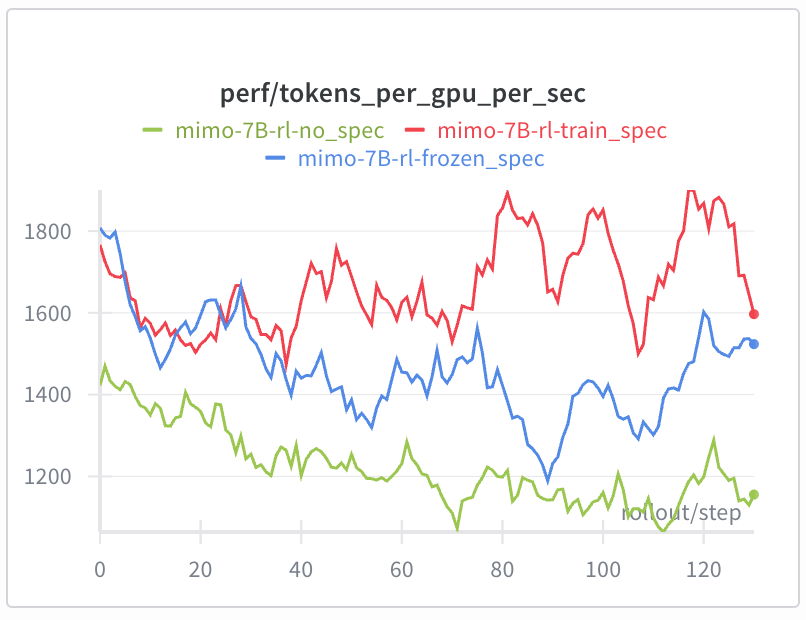
Speculative Decoding with Online Draft Model Training
Freezing the draft model in RL prevents it from following the target model's policy, which reduces accept length and speedup. We now perform online SFT on the draft model throughout RL.
- Achieves 25%+ rollout speedup vs. a frozen MTP, especially in late training stages.
- Supports MTP with sequence packing + CP, loss masks with edge-case handling, LM head/embedding gradient isolation, and Megatron↔SGLang weight syncing.
Other Improvements
We've enhanced the FSDP training backend, allowed independent deployment of the rollout subsystem, and added more debug utilities (metrics, post-hoc analyzers, better profilers). We also included a formal mathematics (Lean) example with SFT/RL scripts.
Roadmap
We are committed to supporting enterprise-grade RL training. Upcoming efforts include:
- Large-scale MoE RL examples on new hardware (e.g., GB300).
- Multi-modal training support.
- Rollout accelerations:
- Compatibility with SGLang spec v2.
- Advanced speculative decoding (e.g., EAGLE3, multi-spec layer).
- Better resource allocation for balanced training & serving in large-scale async training.
- Elasticity to GPU failures.
Acknowledgment
Miles wouldn't exist without the slime authors and the broader SGLang RL community.
We invite researchers, startups, and enterprise teams to explore slime and Miles—pick the one that fits your needs—and join us in making reinforcement learning efficient and reliable. We're listening to the community and actively working on Miles to build a production-ready training environment.