Boost SGLang Inference: Native NVIDIA Model Optimizer Integration for Seamless Quantization and Deployment
(Updated on Dec 2)
We are thrilled to announce a major new feature in SGLang: native support for NVIDIA Model Optimizer quantization! This integration streamlines the entire model optimization and deployment process, allowing you to go from a full-precision model to a high-performance, quantized endpoint entirely within the SGLang ecosystem.
Serving large language models efficiently is one of the biggest challenges in production. Model quantization is a critical technique for reducing the memory footprint and increasing inference speed of a model. Prior to this feature the process required multi-step workflows and separate tools for model optimization and deployment.
With our latest updates (via PRs #7149, #9991, and #10154), we’ve eliminated that complexity.
The optimizations from Model Optimizer and SGLang can deliver up to 2x better per GPU throughput comparing NVFP4 and FP8 inference.
What’s New: Direct ModelOpt APIs in SGLang
SGLang now integrates NVIDIA's Model Optimizer directly, allowing you to call its powerful quantization APIs from your SGLang code.
This new capability unlocks a simple, three-step workflow:
-
Quantize: Use the new SGLang-ModelOpt interface to apply state-of-the-art quantization techniques that enable accelerated low-precision inference in NVFP4, MXFP4, FP8, etc.
-
Export: Save the optimized model artifacts, now fully compatible with the SGLang runtime.
-
Deploy: Load the quantized model directly into the SGLang runtime and serve it on NVIDIA platforms, immediately benefiting from lower latency and reduced memory usage.
Performance Outcomes
The models optimized through this new API enable significant performance boost. Better yet these optimizations can be stacked with other software components in the NVIDIA software-hardware stack and across the various embodiments of the latest Blackwell architecture, from the DGX Spark to GB300 NVL72.
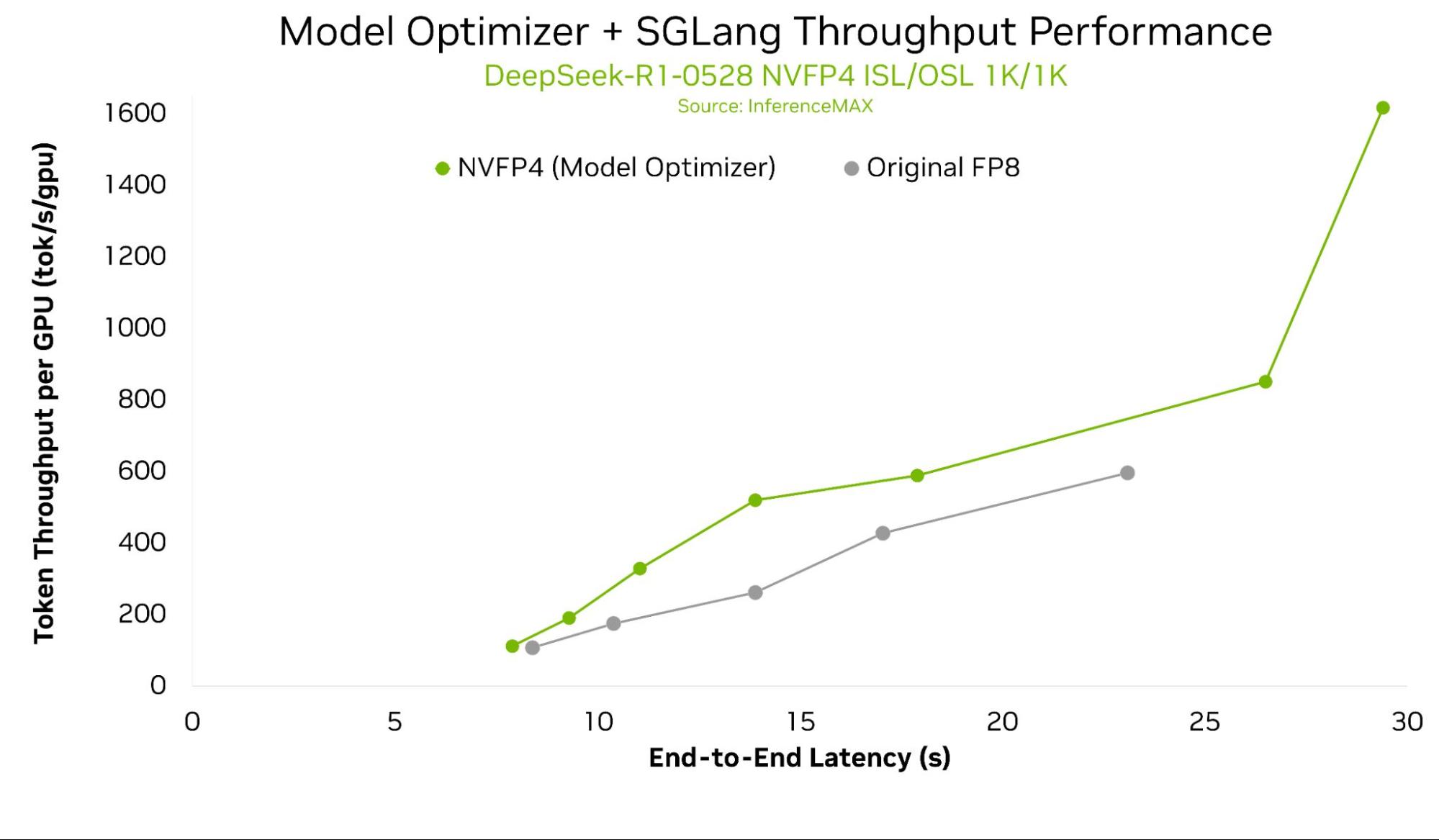
This figure shows NVIDIA B200 per GPU throughput vs End-to-End Latency for DeepSeek-R1-0528 across multiple configurations using Model Optimizer NVFP4 quantized model. This figure compares the original FP8 and NVFP4. DeepSeek-R1-0528 is not yet supported in this initial API release.
As measured by the latest results from InferenceMAX, the optimizations from Model Optimizer and SGLang can deliver up to 2x better per GPU throughput compared to an original FP8 baseline. These performance benefits are coming soon through the native integration discussed in this blog.
How to Get Started
SGLang provides an example script that demonstrates the complete Model Optimizer quantization and export workflow. You can also follow the code snippet below to run quantization and export for your models. Please make sure you installed nvidia-modelopt and accelerate in your SGLang environment.
import sglang as sgl
from sglang.srt.configs.device_config import DeviceConfig
from sglang.srt.configs.load_config import LoadConfig
from sglang.srt.configs.model_config import ModelConfig
from sglang.srt.model_loader.loader import get_model_loader
# Configure model with ModelOpt quantization and export
model_config = ModelConfig(
model_path="Qwen/Qwen3-8B",
quantization="modelopt_fp8", # or "modelopt_fp4"
trust_remote_code=True,
)
load_config = LoadConfig(
modelopt_export_path="./quantized_qwen3_8b_fp8",
modelopt_checkpoint_save_path="./checkpoint.pth", # optional, fake quantized checkpoint
)
device_config = DeviceConfig(device="cuda")
# Load and quantize the model (export happens automatically)
model_loader = get_model_loader(load_config, model_config)
quantized_model = model_loader.load_model(
model_config=model_config,
device_config=device_config,
)
After quantization and export, you can deploy the model with SGLang:
# Deploy the exported quantized model
python -m sglang.launch_server \
--model-path ./quantized_qwen3_8b_fp8 \
--quantization modelopt \
--port 30000 --host 0.0.0.0
Or using the Python API:
import sglang as sgl
from transformers import AutoTokenizer
def main():
# Deploy exported ModelOpt quantized model
llm = sgl.Engine(
model_path="./quantized_qwen3_8b_fp8",
quantization="modelopt"
)
# Use chat template to format prompts for Qwen3-8B
tokenizer = AutoTokenizer.from_pretrained("./quantized_qwen3_8b_fp8")
messages = [
[{"role": "user", "content": "Hello, how are you?"}],
[{"role": "user", "content": "What is the capital of France?"}]
]
prompts = [
tokenizer.apply_chat_template(m, tokenize=False, add_generation_prompt=True)
for m in messages
]
# Run inference
sampling_params = {"temperature": 0.8, "top_p": 0.95, "max_new_tokens": 512}
outputs = llm.generate(prompts, sampling_params)
for i, output in enumerate(outputs):
print(f"Prompt: {prompts[i]}")
print(f"Output: {output['text']}")
if __name__ == "__main__":
main()
Conclusion
This native Model Optimizer integration reinforces SGLang's commitment to providing a simple and powerful platform for LLM inference. We are continuing to close the gap between optimization and deployment of highly-performance models.
We can't wait to see the performance gains you achieve with this new feature. Head over to our GitHub repository to pull the latest version and try it out!
Also, please join our dedicated Slack channel #modelopt to discuss topics such as modelopt, quantization, and low-precision numerics! If you haven’t joined our workspace yet, you can join it first here.
Acknowledgement
Nvidia team: Zhiyu Cheng, Jingyu Xin, Huizi Mao, Eduardo Alvarez, Pen Chung Li, Omri Almog
SGLang team and community: Qiaolin Yu, Xinyuan Tong