Power Up FSDP2 as a Flexible Training Backend for Miles
by: SGLang RL Team, Miles Team, Dec 03, 2025
TL;DR:
We have added FSDP to Miles as a more flexible training framework and have aligned it with Megatron. FSDP supports architecture-innovative models such as Qwen3-Next more flexibly and helps us further support VLM RL.
SGLang RL Team and the Miles community have conducted some interesting explorations around RL training stability and acceleration:
Aligning the SGLang and FSDP backends for strictly zero KL divergence
Speculative Decoding with online SFT for the draft model
Unified FP8: Moving Beyond Mixed Precision for Stable and Accelerated MoE RL
Building on this, we now share a new progress that seeks the best adaptbility and usability to new model architectures, enable FSDP2 a more flexible training backend for Miles.
This work is jointly completed by the SGLang RL Team and Miles Team. Special thanks to DataCrunch, AtlasCloud and EigenAI for compute sponsorship.
Background
What is FSDP?
FSDP (Fully Sharded Data Parallel) inherits the design philosophy of DeepSpeed ZeRO Stage 3 and can be seen as a powerful optimization of traditional DDP (Distributed Data Parallel).
From Replicate to Shard
In traditional DDP, each GPU maintains a complete copy of model weights, gradients, and optimizer states (Replication), synchronizing gradients via all-reduce. In FSDP, we shift to a Sharding mode: all the aforementioned data is sharded and distributed across different GPU ranks.
- Forward Propagation: When a layer needs to be calculated, full parameters are temporarily collected via
all-gatherand released immediately after calculation. - Backward Propagation: After gradient calculation is complete,
reduce-scatteris performed immediately to synchronize and shard, then the full gradients are released.
FSDP1 vs FSDP2
Compared to FSDP1 which flattens all parameters into a giant FlatParameter, FSDP2 introduces DTensor (Distributed Tensor). It allows for better sharding on specified parallel dimensions while preserving the original Tensor structure (such as shape, stride). This not only solves the pain points of volatile metadata and complex padding in FSDP1, but also provides out-of-the-box support for MixedPrecision Training and LoRA; FSDP mentioned in this article refers to FSDP2 natively supported by PyTorch.
✅ For more content about FSDP, you can check the previous blogs of the SGLang RL team: RL System Deep Dive: FSDP Training Backend
Why does Miles need FSDP?
Miles is an enterprise-facing reinforcement learning framework for large-scale MoE post-training and production workloads, forked from and co-evolving with slime. People familiar with Miles know that we already have a mature training engine based on Megatron-LM. Considering the significant maintenance cost brought by introducing a new backend, why are we still determined to support FSDP?
- VLM Architecture Adaptation: The modal interaction architecture of VLM is complex, and FSDP's flexibility makes it much easier to adapt than Megatron. Therefore, we choose FSDP as the preferred path for VLM RL training (of course, Megatron version adaptation is also planned).
- Agility for Architecture Innovation: For new architectures under rapid iteration like Qwen3-Next, FSDP allows us to support RL processes with maximum speed.
- Low Barrier and High Usability: As a PyTorch native training backend, FSDP does not have complex environment dependencies and installation processes. Both the learning curve and debug cost are significantly lower than Megatron.
- Seamless Ecosystem Compatibility: FSDP is directly compatible with HuggingFace Model format. This means we don't need to perform tedious weight conversion via
mbridgelike when using Megatron, and community models work out of the box.
⚠️ Some models in Megatron now also do not require manual weight conversion, as it is automatically converted internally.
FSDP in Miles: Architecture Design
To support two distinct distributed backends, Megatron and FSDP, in Miles simultaneously, how should we avoid underlying conflicts and keep the code clean? We adopted a top-level design of "Interface Standardization + Physical Isolation", meaning we only expose core FSDP functions outwardly: init, save, sleep, wake_up, train. Other functions try to follow the underscore convention, like _train_core. Specifically:
We utilize the Ray Actor mechanism to encapsulate different backends in independent process spaces, exposing unified training primitives (such as train) to the upper-level scheduler, so that the upper-level algorithm logic does not need to care about the underlying gradient synchronization details. This design largely eliminates global variable conflicts and reduces conditional branch complexity, allowing us to deeply optimize for FSDP2's Sharding mechanism and DTensor structure. The core implementation is located in miles/backends/fsdp_utils/actor.py. While keeping external business logic (such as Data Packing, Context Parallel) highly consistent with Megatron, we refactored the data flow path in the kernel implementation, ensuring that while enjoying FSDP's flexibility, we maximize training efficiency and maintain numerical precision.
The robust FSDP design leaves the top-level architecture unaffected, and the overall process remains the standard RLHF loop: Rollout → Data Sharding → Packing → Forward/LogProb → Loss → Backward → Update. On this basis, we have made multiple optimizations for FSDP, including Data Packing, True On-Policy mode, CUDA Graph Aware Weight Wake Up, and numerous mitigation mechanisms for Training-Inference Mismatch. Next, we discuss the top-level init and train function entry points.
Initialization
In the init stage, the following work is mainly completed:
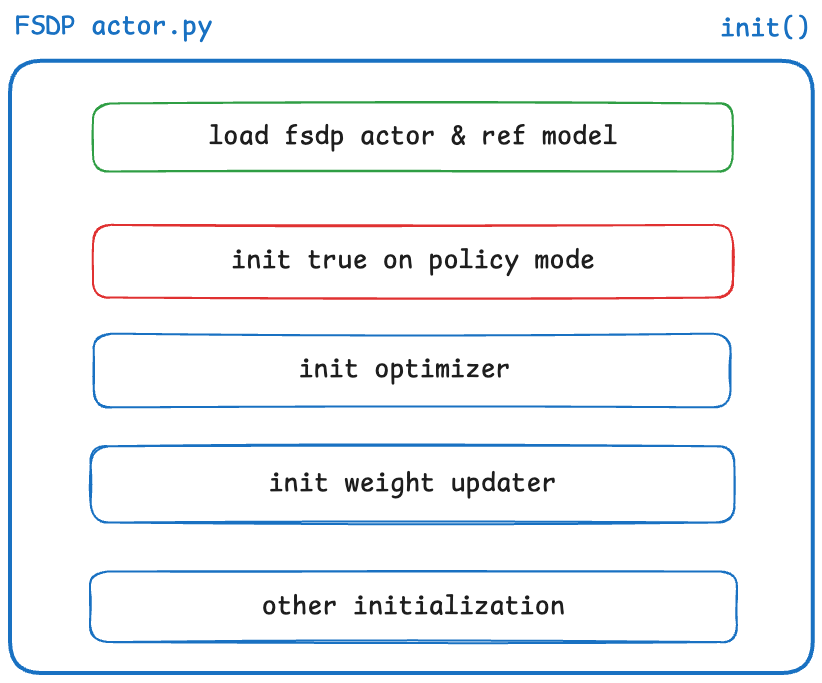
FSDP actor init flow
- Model and Optimizer: Initialize Actor Model and Reference Model, and support resuming from Checkpoint; set
true_on_policy_modeand Optimizer. - Weight Updater: Supports two modes: Colocate (training tasks and inference tasks on the same group of GPUs) and Disaggregated (training tasks and inference tasks on different GPUs), used to synchronize trained weights back to the Inference Engine.
- Device Mesh: Build DP + CP communication topology based on
DeviceMesh, and callfully_shardto shard parameters. - Operator Optimization:
- Force the training end to use operators consistent with SGLang via
enable_batch_invariant_mode, eliminating the impact of batch size on calculation results. - Use
torch.compileto solidify RoPE implementation, eliminating operator behavior differences at the bottom layer to ensure True On-Policy alignment.
- Force the training end to use operators consistent with SGLang via
Training Flow
The train function serves as the main training entry point:
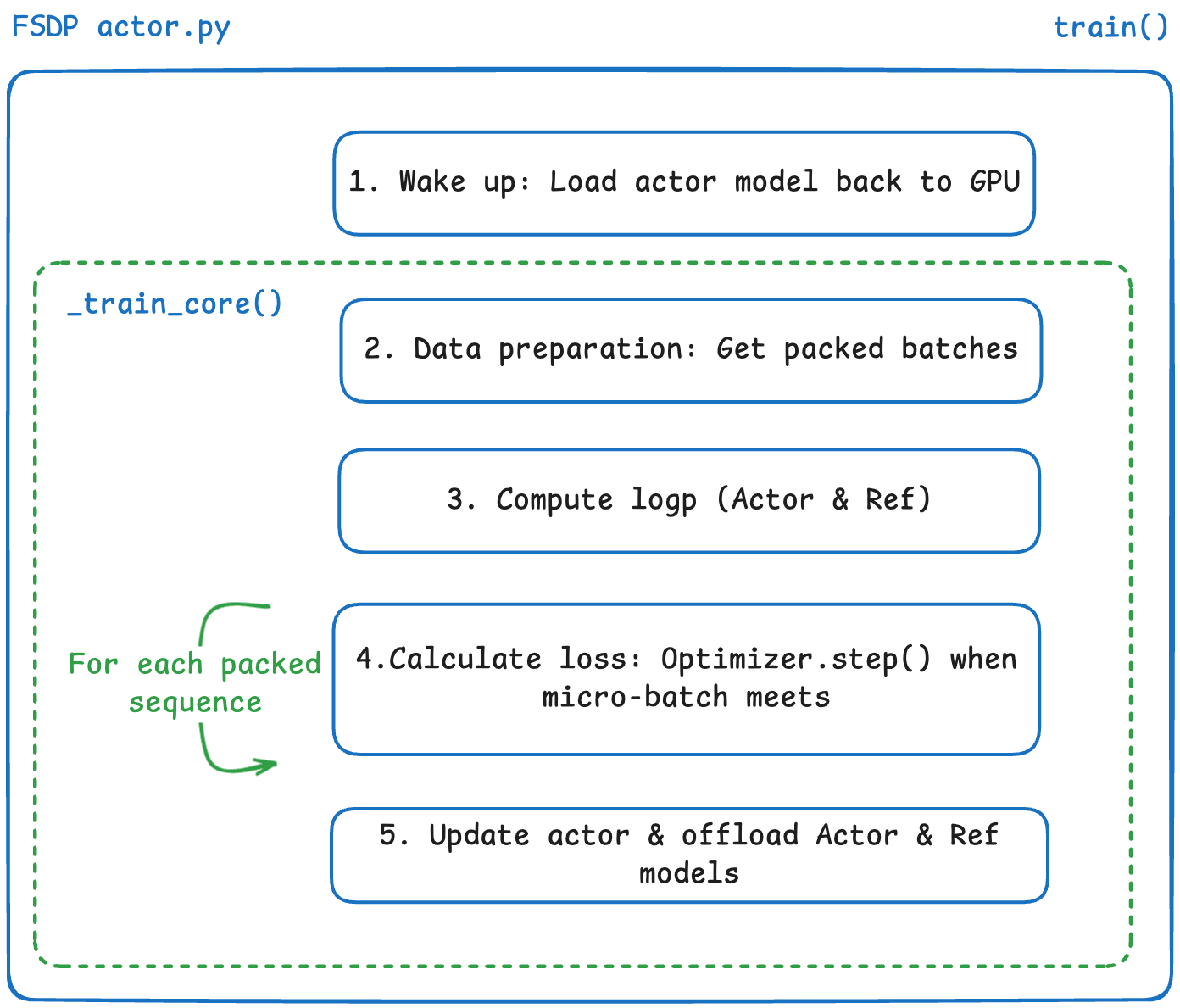
FSDP actor train flow
- wake up: Load the previously Offloaded Actor Model back to GPU.
- data preparation:
- Get data required for the current DP rank via
process_rollout_data. - Call
_pack_rollout_datato pack data intopacked_batches(see Appendix Data Packing for details), eliminating performance loss caused by Padding.
- Get data required for the current DP rank via
- forward & log prob:
- Calculate log_prob and entropy for Actor and Ref.
- loss calculation:
- Calculate PPO/GRPO loss (importance ratio, clip, KL penalty, entropy bonus).
- mismatch feature: Real-time calculation of
train_rollout_logprob_abs_diffto monitor numerical deviation between training and inference. Enable TIS (Truncated Importance Sampling)Source to re-weight policy gradient loss, preventing model collapse due to off-policyness caused by training-inference differences.
- update & offload:
- Perform gradient accumulation and parameter update.
- offload strategy: Call
sleepafter training to offload model and optimizer to CPU (colocated mode); Ref model is loaded only when calculating log prob and offloaded immediately after use.
FSDP in Miles Features & Optimization
Based on the architecture design, we further analyze the optimizations made so far.
Data Prepare And Packing
At the beginning of each training round, the FSDP actor (i.e., this actor class) first gets a batch of balanced rollout sequences from rollout, then does simple sample splitting by DP rank. This step is no different from conventional implementation. For extreme efficiency, we implemented Data Packing. Simply put, pack_sequences is processed in miles/backends/fsdp_utils/data_packing.py. For a batch of input sequences, we estimate how many packs are needed, i.e., the number of micro-batches, based on the length of each sequence and max_tokens_per_gpu. Next, sequences of varying lengths are distributed into different packs so that the total tokens in each pack are as close as possible. Within each pack, multiple sequences are flattened into a long tokens vector, and cu_seqlens is constructed to record the start and end positions of each sequence. This strategy ensures that the total Token amount of each Pack is highly consistent, eliminating the computational waste caused by traditional Padding. Specific details can be found in the Appendix.
Strict Training-Inference Consistency
After completing Data Packing, the actor calculates log-prob and entropy of ref/actor for the packed micro-batch. We implemented True On Policy on FSDP. That is, for the recently very popular training inference mismatch problem, we gave the strictest answer, achieving absolute consistency of logprob for the same policy model in training backend and inference backend, solving training-infer mismatch from the system level.
✅ Briefly speaking, the implementation and idea of training-infer kl = 0 are as follows:
- Both Training and Inference use FlashAttn3 as backend to achieve bitwise equal.
- Use DeepGEMM for matrix multiplication, Batch-invariant Kernels to achieve batch invariance. Specific details are documented in more detail in Miles's Docs.
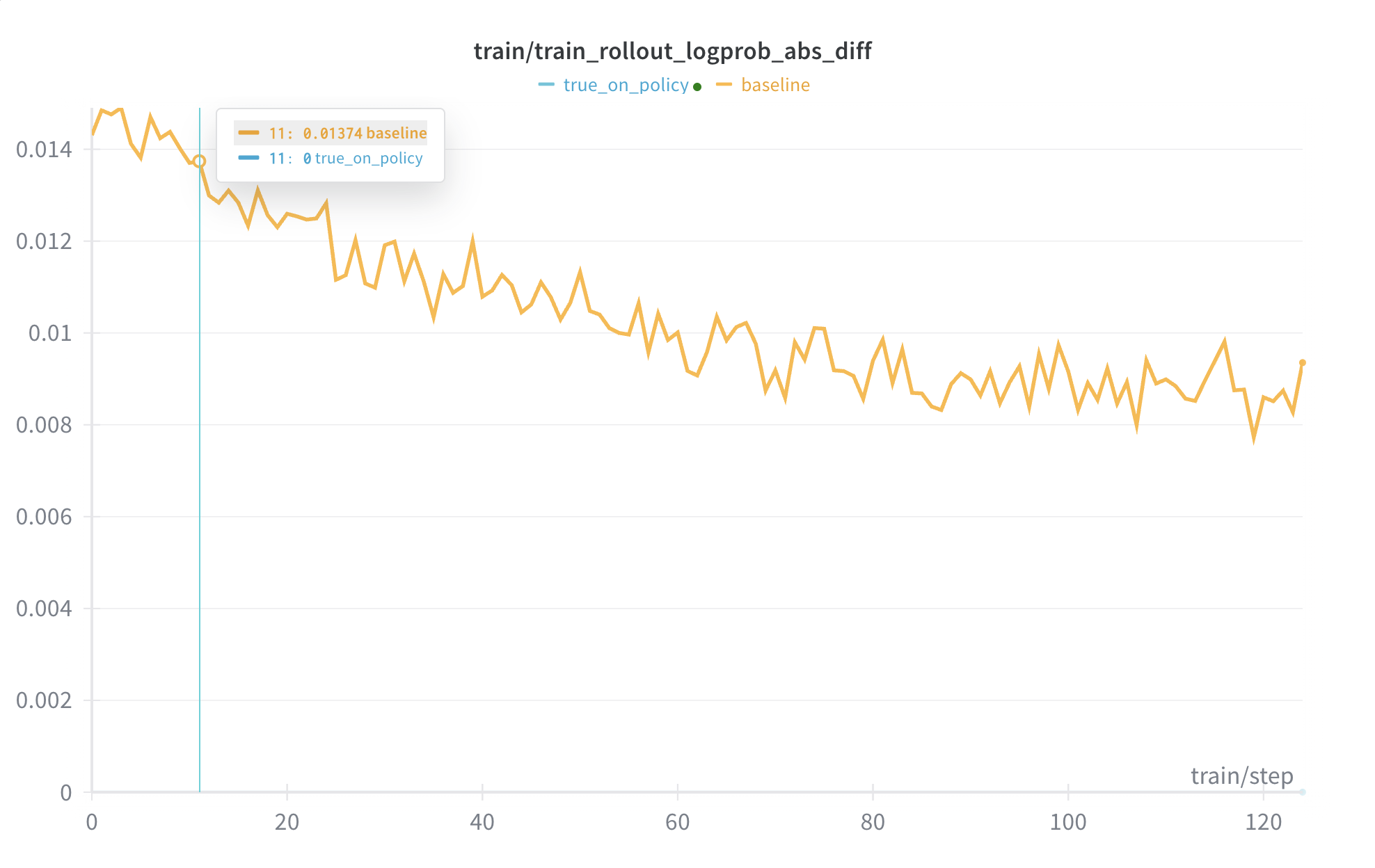
We further optimize performance under true on policy conditions. get_logprob_and_entropy_with_cp directly reuses the temperature passed in by Rollout, and turns off allow_compile which may introduce deviation. Disabling compile will forbid compiling selective_log_softmax_raw, preventing estimation deviation caused by different calculation paths due to compilation and batch invariant. This ensures that the log-prob re-calculated at the training end can accurately restore the numerical performance during Rollout.
⚠️ Here we discovered and solved an imperceptible Bug that caused on policy kl ≠ 0 when using kl-loss, see Appendix PPO KL Precision Error for details.
Algorithms Mitigation For Mismatch
The default set up in Miles and most of RL communities do not enable true on policy features, which would lose about 30% of training efficiency. So there will still be training-inference mismatch. For accuracy, we call the rollout policy log probs recorded during the rollout phase rollout_log_probs; after entering the training loop, the log probs of the policy model recalculated in the training backend are recorded as old_log_probs.
Without considering training-infer mismatch, the actor constructs loss in _train_step in the conventional GRPO/GSPO/PPO way. Specifically, each training step calculates the log probs of the current training data batch based on the current policy model, directly noted as log_probs. Use old_log_probs and log_probs to construct importance ratio, superimpose clip, KL norm and entropy bonus to get loss, then do gradient accumulation and optimizer backward.
Considering mismatch, rollout_log_probs, old_log_probs, log_probs will all participate in loss construction:
- In
_train_stepofactor.py, calculate the absolute differencetrain_rollout_logprob_abs_diffbetweenold_log_probsandrollout_log_probsto quantify numerical deviation between training and inference in real-time. - Enable TIS (Truncated Importance Sampling). Calculate importance weight, i.e.,
tis = torch.exp(old_log_probs - rollout_log_probs), and truncate (Clip) it, using this weight to re-weight Policy Gradient Loss (pg_loss). This method ensures that the model can still mitigate model training collapse even in a not-so-perfect on-policy environment (Thanks to the author teams of MIS and TIS).
Taking GRPO as an example, the final loss function is:
$$ \mathcal{L}(\theta) = \frac{1}{L} \sum_{t=1}^L \left[ \bar{w}_t \cdot \mathcal{L}^{\text{clip}}_t(\theta) - \beta ,\text{KL}_t + \lambda H_t \right] $$
where
$$ \mathcal{L}^{\text{clip}}_t = \min \left( r_t(\theta) A_t,\ \text{clip}(r_t(\theta), 1\pm\epsilon), A_t \right) $$
and
$$ r_t(\theta) = \frac{\pi_\theta}{\pi_{\text{old}}}, \quad \bar{w}_t = \min \left( \frac{\pi_{\text{old}}}{\pi_{\text{rollout}}}, C \right) $$
Weight Update Optimization: Weight Update and Colocated Mode
After training ends, the latest weights are synchronized back to the Inference Engine (this is the best definition of the term refit). In update_weight_utis.py, we fully support all modes: colocated and distributed. The former alternates train / rollout occupying the same batch of GPUs, while the latter distributes train / rollout on different GPUs. For both methods, we adopted a bucketed asynchronous update strategy Reference, synchronizing chunked weights to the inference engine one by one, minimizing peak memory usage as much as possible.
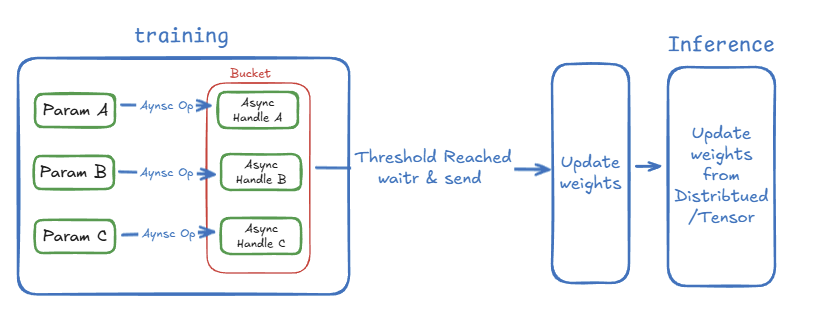
✅ For specific mechanisms of weight update, welcome to check the previous blogs of SGLang RL group: RL System Deep Thinking: Weight Update Mechanisms
VRAM Optimization: Offload Strategy
In the FSDP training process, we save memory by offloading weights in the following scenarios:
- Train offload: In colocated scenarios, call
sleepafter training completes to offload model weights and optimizer to CPU, avoiding memory occupation during the rollout phase. - Ref model: When using KL penalty, the reference model is only loaded to GPU during
compute_log_prob, and offloaded back to CPU immediately after calculation completes, avoiding GPU occupation. - Optimizer offload: During the training phase, model parameters are offloaded to CPU when not participating in calculation, and gradients are also offloaded to CPU; this significantly saves VRAM consumption during training, but optimizer steps will be performed on CPU, and training time will increase significantly.
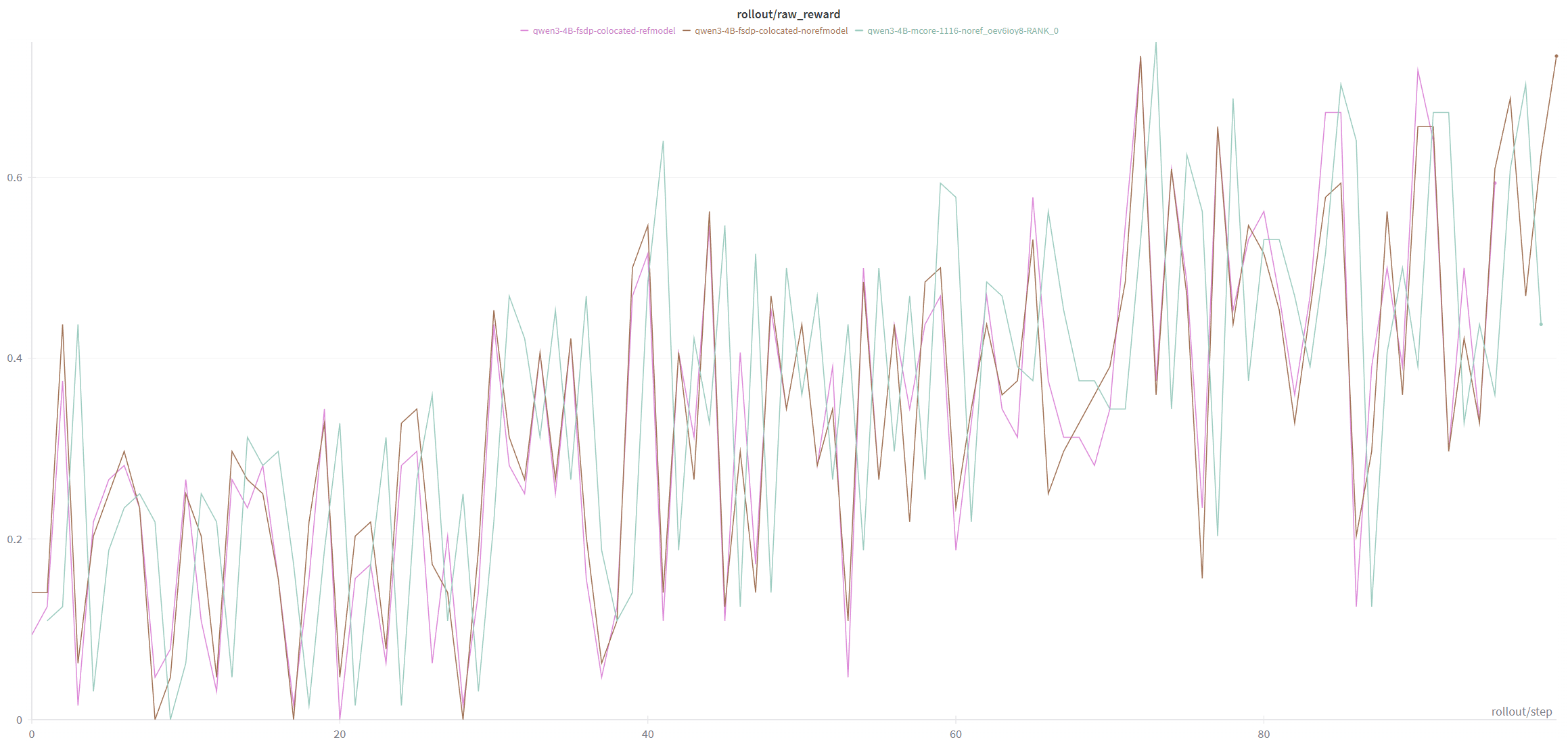
FSDP/Megatron Training Precision Alignment
Experimental Environment: Single node H100, Miles 0.5.5post1
Megatron, FSDP colocated w ref model, FSDP colocated w/o ref model
Context Parallelism
For CP, we want to ensure that Megatron and FSDP can support similar response lengths under the same Context Parallelism degree:
✅ Theoretically
max_reponse_length_with_cp = max_reponse_length_without_cp * cp_sizeref link
For experimental configuration: 4 B200s, global_batch_size = 64:
| response_length = 8k | response_length = 16k | |
|---|---|---|
| FSDP, cp = 1 | work | OOM |
| FSDP, cp = 2 | work | work |
| Megatron(TP = 1), cp = 1 | work | OOM |
| Megatron(TP = 1), cp = 2 | work | work |
Experimental results meet expectations, and convergence effects are similar.
Quick Start FSDP Backend
FSDP One-Click Start
# If you need to use WANDB, you need to set the environment variable WANDB_API_KEY in advance
# Download model weights (Qwen3-4B)
hf download Qwen/Qwen3-4B --local-dir /root/Qwen3-4B
# Download training dataset (dapo-math-17k)
hf download --repo-type dataset zhuzilin/dapo-math-17k \
--local-dir /root/dapo-math-17k
# Download evaluation dataset (aime-2024)
hf download --repo-type dataset zhuzilin/aime-2024 \
--local-dir /root/aime-2024
# Clone code and install dependencies
git clone https://github.com/radixark/miles.git
cd miles
pip install -e .
# FSDP does not require weight conversion, natively supports huggingface format
# Enable reference model, train Qwen3-4B in colocate mode
bash /root/miles/scripts/run-qwen3-4B-fsdp.sh
From Megatron to FSDP
FSDP automatically reads all architecture information via AutoModelForCausalLM.from_pretrained(), without manual specification. Megatron requires manual configuration of parameters to read model architecture information, or automatic inference via --use-hf-config-for-megatron. FSDP can read entirely from config.json, directly avoiding the weight format conversion step.
Megatron vs FSDP Parameters Comparison Table
| Configuration Category | Megatron Parameter | FSDP Parameter | Description |
|---|---|---|---|
| Model Loading | --load (Megatron checkpoint) + architecture args (--num-layers, --hidden-size etc.) or --use-hf-config-for-megatron |
--hf-checkpoint (Required) |
FSDP: Directly uses HuggingFace format, no weight conversion needed, architecture inferred via AutoConfig |
| Tensor Parallel | --tensor-model-parallel-size |
Coming Soon | |
| Pipeline Parallel | --pipeline-model-parallel-size |
Coming Soon | |
| Expert Parallel | --expert-model-parallel-size |
Coming Soon | |
| Context Parallel | --context-parallel-size |
--context-parallel-size |
Both support CP |
| Initial Learning Rate | --lr |
--lr |
Same parameter |
| Learning Rate Decay | --lr-decay-style (linear/cosine) |
--lr-decay-style (only constant) |
|
| Warmup | --lr-warmup-iters (steps) |
Coming Soon | |
| Min Learning Rate | --min-lr |
Coming Soon | |
| Optimizer Type | --optimizer (adam/sgd etc.) |
--optimizer (default adam) |
Basically same |
| Distributed Optimizer | --use-distributed-optimizer |
Built-in to FSDP | FSDP uses distributed optimizer by default |
| Gradient Checkpoint | --recompute-granularity, --recompute-method |
--gradient-checkpointing |
FSDP: Simplified to boolean switch |
| CPU Offload | Implemented via distributed optimizer | --fsdp-cpu-offload |
FSDP: Offload parameters/gradients/optimizer states to CPU |
| Attention Backend | Decided by Megatron Core | --attn-implementation (flash_attention_2/sdpa/eager) |
FSDP: Directly passed to HuggingFace |
| Mixed Precision | --fp16 or --bf16 |
--fp16 (bf16 inferred automatically) |
Basically same |
| Offload on Save | - | --fsdp-state-dict-cpu-offload (Default True) |
FSDP: Offload to CPU when saving checkpoint |
| Training Backend | Default or --train-backend megatron |
--train-backend fsdp (Required) |
Used to switch backend |
Features Currently Not Supported in FSDP
FSDP currently only supports DP + CP, and does not support TP, EP, PP. The implementation of CP is different from Megatron.
Megatron Core has native implementation (deeply integrated with TP/PP), while FSDP implements it via external Ring Flash Attention library.
In addition, Megatron's --recompute-granularity (full/selective), --recompute-method (uniform/block), --recompute-num-layers are not supported. FSDP only has a simple --gradient-checkpointing switch.
Finally, FSDP optimizer's learning rate currently only supports being set to constant, and there is no warmup strategy.
Future Plans
As a lightweight backend, our future plans for FSDP include the following directions:
- Implement TP and EP while maintaining clean and tidy code.
- Add a set of FSDP VLM training capabilities and corresponding scripts: Prioritize Qwen2.5-VL / Qwen3-VL (HF default weights) models, using Geo3K / Deepeyes datasets to implement and test single-turn and multi-turn VLM RL Training respectively, and finally support vision + language joint training or partial freezing on FSDP2.
- Support Qwen3-next and other hybrid models for training and optimization.
Acknowledgements
Thanks to all friends who contributed code, testing, and optimization to miles X FSDP:
SGlang RL team: Chengxi Li, Zilin Zhu, Chengxing Xie, Haoran Wang, Lei Li, Yusheng Su, Zhuohao Li, Ji Li, Jiahui Wang, Jin Pan, William Ren, Qisheng Liu, Yuzhen Zhou, Jiajun Li, Yuqi Xiang
Miles Team: Huapeng Zhou, Mao Cheng, Chenyang Zhao, Tom
We sincerely thank the AtlasCloud and DataCrunch for their computing support.
Linkedin: Lancert
In the same time, our amazing members, Chengxi Li and Huapeng Zhou are looking for new work opportunities, welcome to contact them.
Engineering Implementation Details
Context Parallel
FSDP's CP is directly implemented via ring flash attention library. Compared to Megatron's complex chunk mechanism, FSDP only needs to implement simple continuous chunks, and the load balancing part is handed over to ring flash attn. We only need to focus on input data slicing and result aggregation.
Specific implementation flow is as follows:
- Device Mesh Setup: Establish (DP, CP) 2D communication group in
setup_device_mesh, and usesubstitute_hf_flash_attnto replace HuggingFace model's original Flash Attention operator with Ring Flash Attention implementation supporting CP. - Input Slicing: In the
_get_model_inputs_argsstage before forward, we directly usetorch.chunkto slice Data Packedinput_idsandposition_idsintocp_sizeparts on the sequence dimension. The current rank only loads its own part of data. Meanwhile, callupdate_ring_flash_attn_paramsto pass globalcu_seqlensinfo to the underlying Attention operator. - Result Gathering: When calculating Log Probs (
get_logprob_and_entropy_with_cp), each rank calculates local shard's log_probs and entropy in parallel. Finally, splice the results distributed on different ranks back into a complete sequence viaall_gather, and remove Padding filled to meet CP alignment requirements.
Data Packing
To avoid waste caused by large amounts of padding on each CP rank due to direct padding, we splice long sequences into continuous vectors and use cu_seqlens to record boundaries. We first reused megatron's process_rollout_data() to split rollout by DP rank, then packed_data estimates how many micro_batches are needed to complete a global_batch based on rollout token count and DP size. The relationship between global_batch and micro_batch in miles is seen in Batch & Sample.
- When
use_dynamic_batch_sizeis enabled, the number of micro-batches needs to be dynamically calculated based on actual sequence length: Use First-Fit algorithm viaget_minimum_num_micro_batch_size()to estimate the minimum number of micro-batches needed to accommodate all data based on each sequence's length andmax_tokens_per_gpulimit. This number will be synchronized across all DP ranks viaall_reduce(MAX)to ensure consistent gradient accumulation steps for each rank. - If dynamic batch size is not enabled, directly use static formula global_batch_size // (micro_batch_size * dp_size) to calculate fixed micro-batch count.
Next, execute actual packing operation in pack_sequences():
- Calculate partition count
k_partitions = ceil(total_tokens / max_tokens_per_gpu) - Call
get_seqlen_balanced_partitions()to perform load balanced allocation using Karmarkar-Karp algorithm (Largest Differencing Method). This algorithm maintains partition states via priority queue, merging the two partitions with the largest token total difference each time, making the final token count of each pack highly balanced. - For each pack, splice assigned sequences into continuous
flat_tokensvector, and constructcu_seqlensarray to record each sequence's boundaries, e.g.,[0, 128, 384, 512]means 3 sequences with lengths 128, 256, 128 respectively.
In Context Parallel mode (cp_size > 1), pad_packed_sequence_with_cp() will perform minimum alignment padding (at most cp_size-1 tokens) on the spliced sequence, ensuring total length can be divisible by cp_size for cross-rank slicing. Although this is still naive direct padding, since padding ≤ cp_size -1, it will not cause visible overhead.
During training, cu_seqlens is directly passed to Flash Attention to handle variable length sequences; when calculating loss, unpack_sequences() accurately restores indicators like log_probs, advantages for each sequence based on boundary information. This method basically avoids overhead caused by naive padding.
PPO KL Precision Error
The PPO training process involves three batch-related parameters: Batch, Micro batch size & Sample.
Ideally, when sample count × micro_batch_size = global_batch_size, it means all samples generated in one rollout (sample count × prompts processed per batch) exactly equal one complete training batch. At this time, rollout phase and training phase use the same unupdated actor weight version.
- Use weight
W_tto generate responses during Rollout. - Still use weight
W_tto calculate log probabilities during training.
Therefore, theoretically PPO KL divergence should be 0. However, in actual operation (only when reference model is enabled), KL divergence maintains a small positive value instead of 0 starting from the first micro batch, indicating a numerical drift problem.
This problem is caused by precision errors in weight exchange logic. The original implementation referred to Megatron's way, manually exchanging ref and actor tensors between CPU and GPU. To be compatible with FSDP2's DTensor, we manually created DTensor for swap. However, manual weight exchange leads to slight numerical deviations during weight loading. Megatron uses this manual exchange because the offload process of distributed optimizer is very complex, so it simply exchanges weights directly.
Finally, we switched to a cleaner solution: treat reference model as an independent FSDP model, use FSDP native CPU Offload for management, and load it to GPU only during forward. This method completely avoids manual weight exchange, fully utilizes FSDP native CPU/GPU transfer mechanism, eliminates numerical drift from the root cause, making PPO KL converge to theoretical value 0, while not introducing additional GPU memory overhead.
True on policy
After the CP PR was merged, the true on policy of the main branch actually failed. After investigation, it was found that precision was autocast to bf16 after indentation. After fixing, training-infer mismatch was successfully restored to 0.
To avoid precision problems caused by improper application of auto cast, we finally chose Mixed Precision newly supported by FSDP2, implementing clearer and cleaner precision management.
Batch & Sample
- Sample count (n-samples-per-prompt): Number of candidate responses generated per prompt
- Micro batch size: Number of samples processed per forward/backward pass during training (limited by GPU VRAM)
- Global batch size: Total samples for a complete training iteration, usually completed by gradient accumulation of multiple micro batches