Introducing Hard Prompts Category in Chatbot Arena
by: Tianle Li, Wei-Lin Chiang, Lisa Dunlap, May 20, 2024
Background
Introducing Hard Prompts, a new and challenging category in the Chatbot Arena Leaderboard.
Over the past few months, the community has shown a growing interest in more challenging prompts that push the limits of current language models. To meet this demand, we are excited to introduce the Hard Prompts category. This category features user-submitted prompts from the Arena that are specifically designed to be more complex, demanding, and rigorous. Carefully curated, these prompts test the capabilities of the latest language models, providing valuable insights into their strengths and weaknesses in tackling challenging tasks. We believe this new category will offer insights into the models' performance on more difficult tasks.
New Category: Hard Prompts!
To evaluate the difficulty of a prompt, we define several hardness criteria, such as domain knowledge, complexity, and problem-solving. Prompts that meet multiple criteria are considered more challenging and are assigned a higher hardness score. These scores help us create a new leaderboard category: Hard Prompts.
In Figure 1, we present the ranking shift from English to Hard Prompts (English). We observe that Llama-3-8B-Instruct, which performs comparably to GPT-4-0314 on the English leaderboard, drops significantly in ranking. This suggests that the model may struggle with the increased complexity and difficulty of the prompts in this new category. We also observe Claude-3-Opus surpasses Llama-3-70B-Instruct, and GPT-4o shows slight improvement.
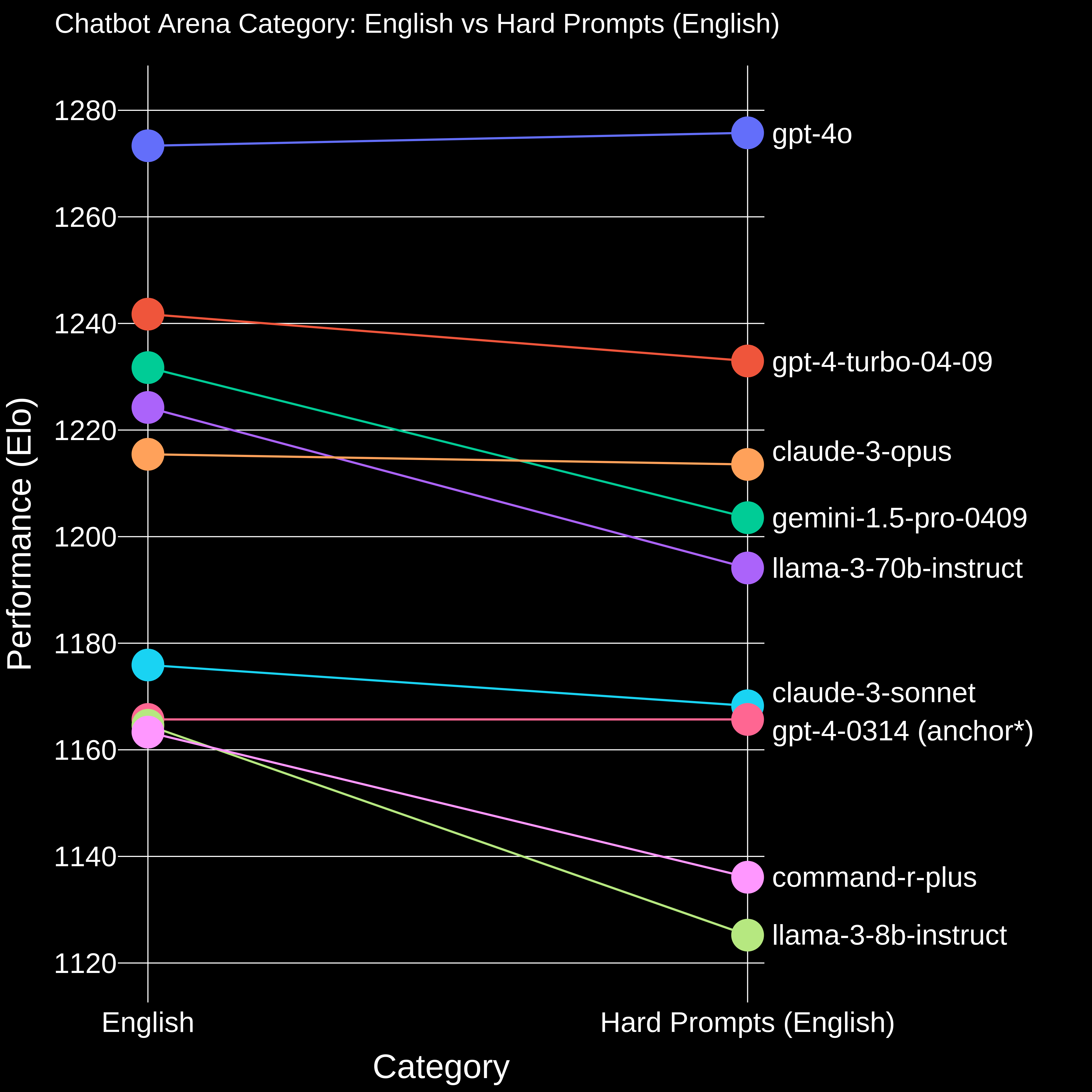
Figure 1. Comparison between Chatbot Arena Category English vs Hard Prompts (English). We set gpt-4-0314 as anchor model.
We also observe notable improvements in GPT-3.5-Turbo-1106/0125 and Claude-2.1, as well as Phi-3, which is trained for reasoning tasks.
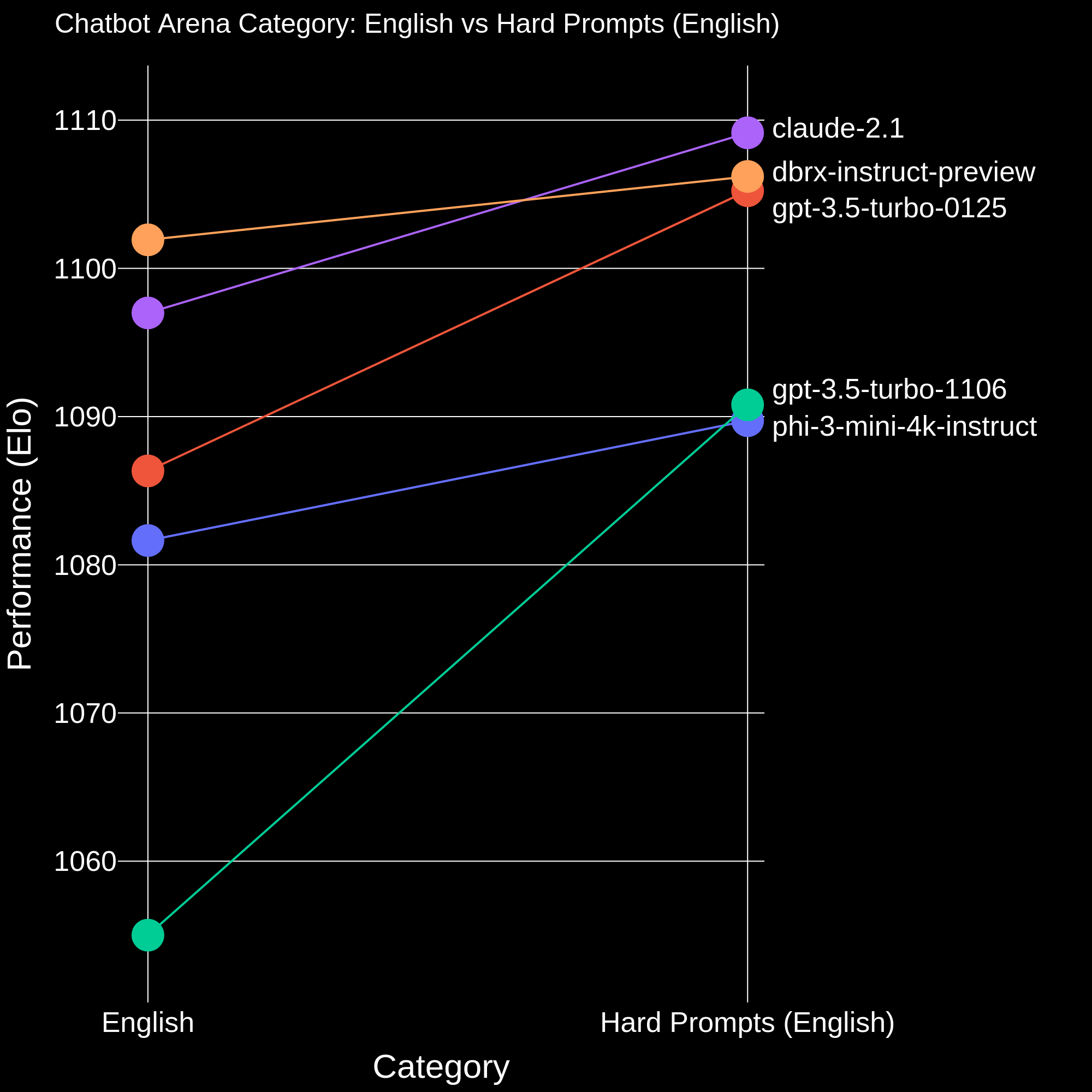
Figure 2. Comparison between Chatbot Arena Category English vs Hard Prompts (English). We set mixtral-8x7b-instruct-v0.1 as anchor model.
How to Define Hard Prompts?
A few weeks ago, we introduce the Arena-Hard pipeline to identify a collection of high-quality prompts from Chatbot Arena. Each user prompt is evaluated against the 7 Key Criteria defined in the Table below.
| 1. Specificity: Does the prompt ask for a specific output? |
| 2. Domain Knowledge: Does the prompt cover one or more specific domains? |
| 3. Complexity: Does the prompt have multiple levels of reasoning, components, or variables? |
| 4. Problem-Solving: Does the prompt directly involve the AI to demonstrate active problem-solving skills? |
| 5. Creativity: Does the prompt involve a level of creativity in approaching the problem? |
| 6. Technical Accuracy: Does the prompt require technical accuracy in the response? |
| 7. Real-world Application: Does the prompt relate to real-world applications? |
We employ Meta's Llama-3-70B-Instruct to help us label over 1 million Arena prompts on whether certain critieria are met. Note that we do not use LLM as judges to evalute model answers. We use the preference votes casted by Arena users to rank models. Figure 3 shows the criteria breakdown (i.e., how many prompts satisfy each criteria). We observe the most common criteria are Specificity, Domain Knowledge, and Real-world Application, while the relatively rare criteria are Problem-Solving and Complexity.
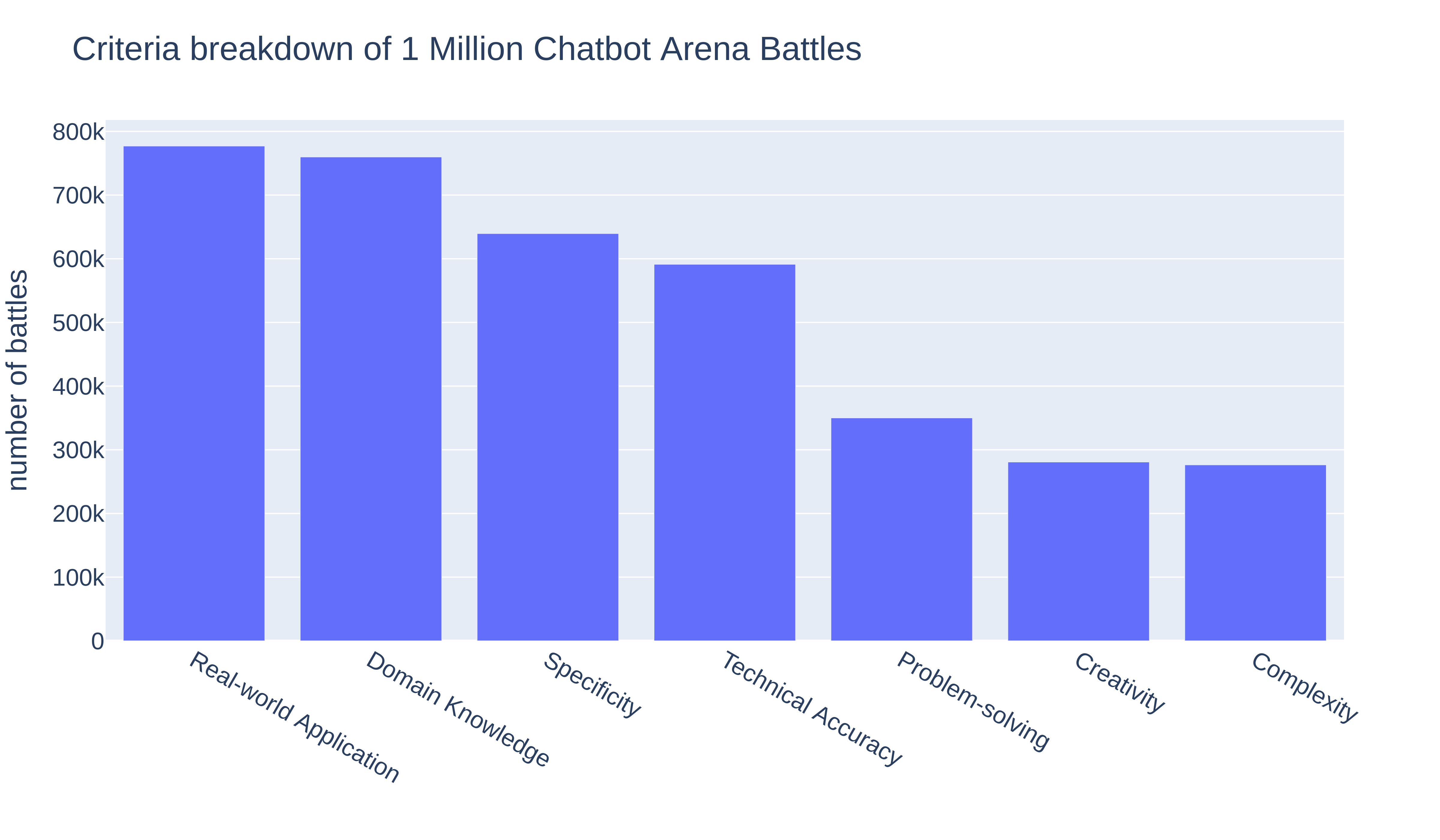
Figure 3. The percentage of each criteria within 1 million Chatbot Arena data.
We then calculate its Hardness Score by how many criteria are satisfied and present the distribution in Figure 3. Interestingly, we find that approximately 20% of prompts have a score of 6 or higher. You can find several examples below to demonstrate what a hard prompt looks like in the Example Section.
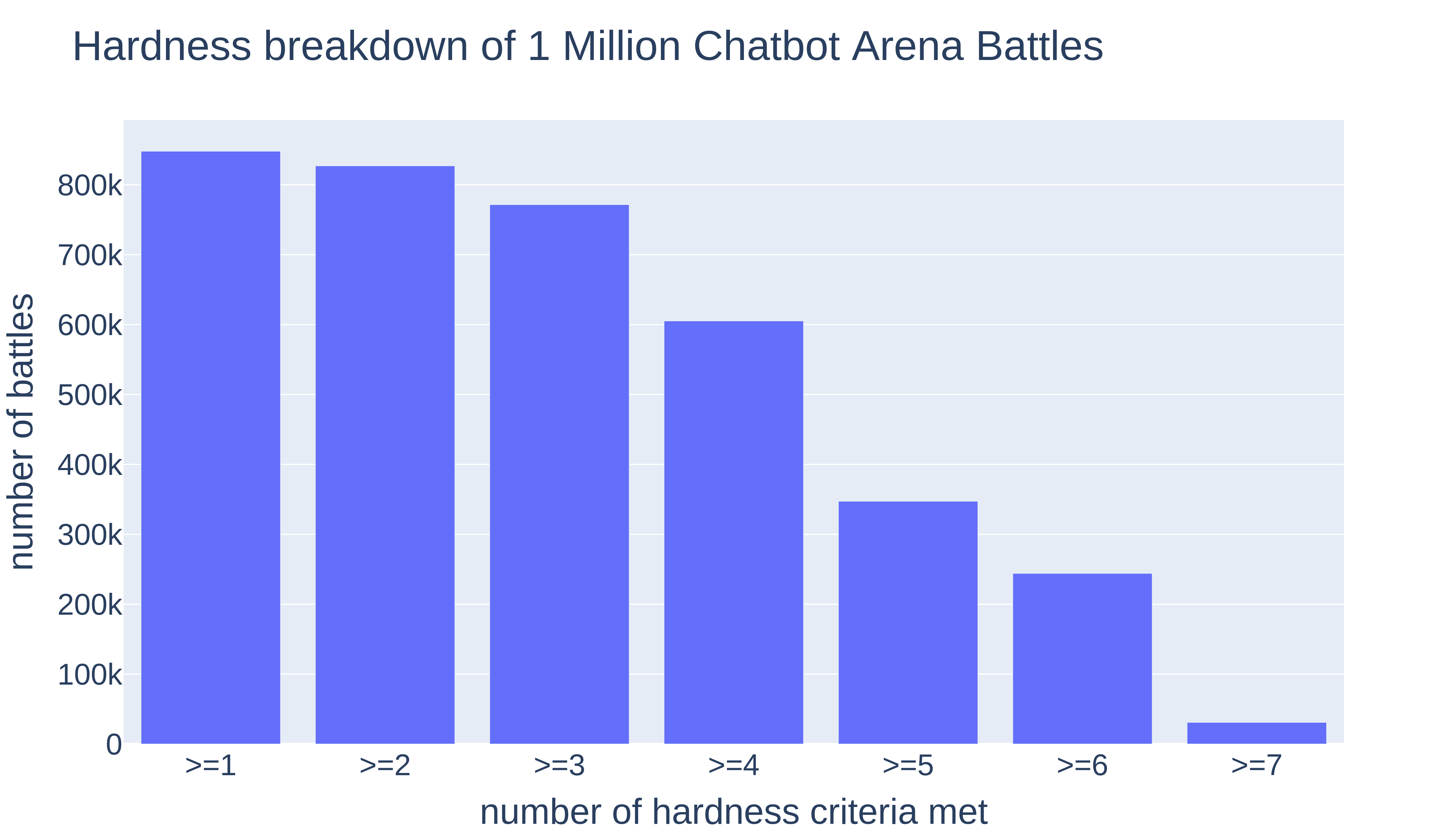
Figure 4. The percentage of prompts with different hardness score within 1 million Chatbot Arena data.
We use prompts with a score of 6 or higher to create the "Hard Prompts" category and calculate two leaderboards: Hard Prompt (English) and Hard Prompts (Overall).
Below is screenshot of the leaderboard for Hard Prompts (English) category (as of May 17, 2024). You can find the latest version at https://leaderboard.lmsys.org (-> Category dropdown).
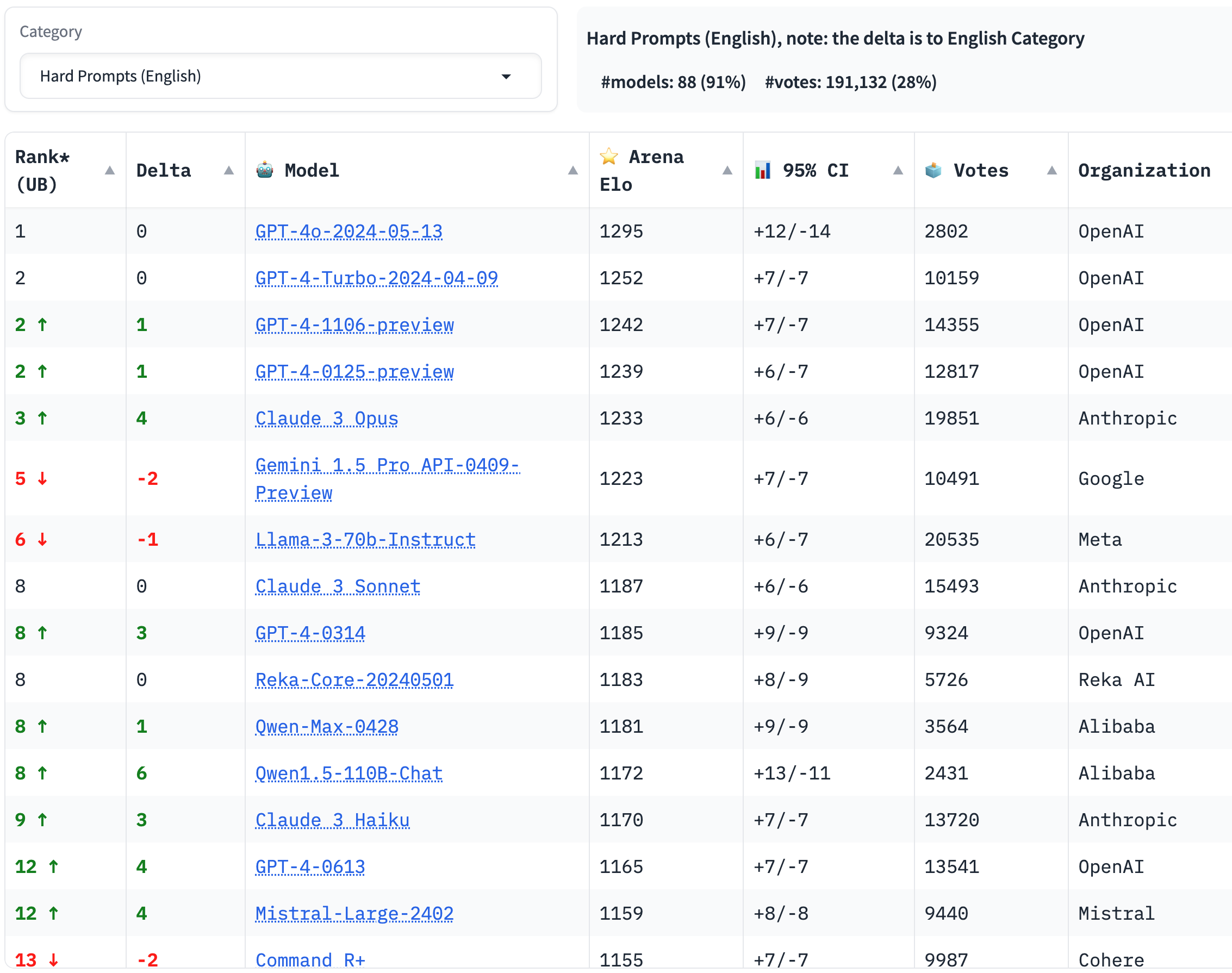
Figure 5. The leaderboard for Hard Prompts (English) category as of May 17, 2024.
We are commited to continuously enhance the Chatbot Arena leaderboard and share insights with the broader community. We welcome you to contribute more challenging prompts and look forward to seeing how the latest advancements in language models perform!
Note: Enhancing Quality Through De-duplication
To improve the overall quality of prompts in Chatbot Arena, we also implement a de-duplication pipeline. This new pipeline aims to remove overly redundant user prompts that might skew the distribution and affect the accuracy of our leaderboard. During our analysis, we noticed that many first-time users tend to ask similar greeting prompts, such as "hello," leading to an over-representation of these types of queries. To address this, we down-sample the top 0.1% most common prompts (approximately 1000 prompts, mostly greetings in different languages) to the 99.9% percentile frequency (25 occurrences). After this process, about 8.6% of the votes are removed. We believe this helps maintain a diverse and high-quality set of prompts for evaluation. We hope to encourage users to submit more unique & fresh prompts to reduce the risk of contamination.
We have also open-sourced this de-duplication script on Github and publish the vote data with de-duplication tags in the notebook. We will continue to monitor the impact of this de-duplication process on the leaderboard and make adjustments as necessary to ensure the diversity and quality of our dataset.
Citation
@misc{arenahard2024,
title = {From Live Data to High-Quality Benchmarks: The Arena-Hard Pipeline},
url = {https://lmsys.org/blog/2024-04-19-arena-hard/},
author = {Tianle Li*, Wei-Lin Chiang*, Evan Frick, Lisa Dunlap, Banghua Zhu, Joseph E. Gonzalez, Ion Stoica},
month = {April},
year = {2024}
}
Example
We present 10 examples of user prompt with increasing hardness score. The labeled criteria are inside the bracket.
Prompt 1:
[None]
hello
Prompt 2:
[Real World]
what is cake
Prompt 3:
[Creativity, Real World]
How to pickup a girl?
Prompt 4:
[Specificity, Creativity, Real World]
writen ten different sentences that end with word "apple"
Prompt 5:
[Specificity, Creativity, Real World]
Writing prompt: write the start of a short story / a man with an iphone is transported back to 1930s USA.
Prompt 6:
[Specificity, Domain Knowledge, Complexity, Problem-solving, Technical Accuracy, Real World]
tell me how to make a hydroponic nutrient solution at home to grow lettuce with precise amount of each nutrient
Prompt 7:
[Specificity, Domain Knowledge, Complexity, Problem-solving, Technical Accuracy, Real World]
Solve the integral $\int_{-\infty}^{+\infty} exp(-x^2) dx $ step-by-step with detailed explanation
Prompt 8:
[Specificity, Domain Knowledge, Complexity, Problem-solving, Technical Accuracy, Real World]
write me GLSL code which can gennrate at least 5 colors and 2 waves of particles cross each other
Prompt 9:
[Specificity, Domain Knowledge, Complexity, Problem-solving, Technical Accuracy, Real World]
My situation is this: I’m setting up a server running at home Ubuntu to run an email server and a few other online services. As we all know, for my email to work reliably and not get blocked I need to have an unchanging public IP address. Due to my circumstances I am not able to get a static IP address through my ISP or change ISPs at the moment.
The solution I have found is to buy a 4G SIM card with a static IP (from an ISP that offers that), which I can then use with a USB dongle. However this 4G connection costs me substantially per MB to use.
But. Mail is the only server that needs a static IP address. For everything else using my home network connection and updating my DNS records with DDNS would be fine. I have tested this setup previously for other services and it has worked.
So. I was wondering. Would it in theory be possible to: connect the server to two network interfaces at the same time and route traffic depending on destination port. I.e. all outgoing connections to ports 25, 465, 587, and possibly 993 should be sent through the 4G dongle interface (enx344b50000000) and all other connections sent over eth0. Similarly, the server should listen for incoming connections on the same ports on enx344b50000000 and listen on all other ports (if allowed by ufw) on eth0.
I would then need DNS records from mail.mydomain.tld —> <4g static public IP> and mydomain.tld —>
Computers on the internet would then be able to seamlessly connect to these two IP addresses, not “realising” that they are in fact the same machine, as long as requests to mail.mydomain.tld are always on the above mentioned ports.
Question: Is this possible? Could it be a robust solution that works the way I hope? Would someone be able to help me set it up?
I have come across a few different guides in my DuckDuckGo-ing, I understand it has to do with setting a mark in iptables and assigning them to a table using ip route. However I haven't managed to get it to work yet, and many of these guides are for VPNs and they all seem to be slightly different to each other. So I thought I would ask about my own specific use case
Prompt 10:
[Specificity, Domain Knowledge, Complexity, Problem-solving, Creativity, Technical Accuracy, Real World]
Write me a python script for the foobar problem, but make it so that if read aloud, each pair of lines rhymes. (i.e. lines 1/2 rhyme, 3/4 rhyme and so on)