How Long Can Open-Source LLMs Truly Promise on Context Length?
In this blogpost, we introduce our latest series of chatbot models, LongChat-7B and LongChat-13B, featuring a new level of extended context length up to 16K tokens. Evaluation results show that the long-range retrieval accuracy of LongChat-13B is up to 2x higher than other long-context open models such as MPT-7B-storywriter (84K), MPT-30B-chat (8K), and ChatGLM2-6B (8k). LongChat shows promising results in closing the gap between open models and proprietary long context models such as Claude-100K and GPT-4-32K.
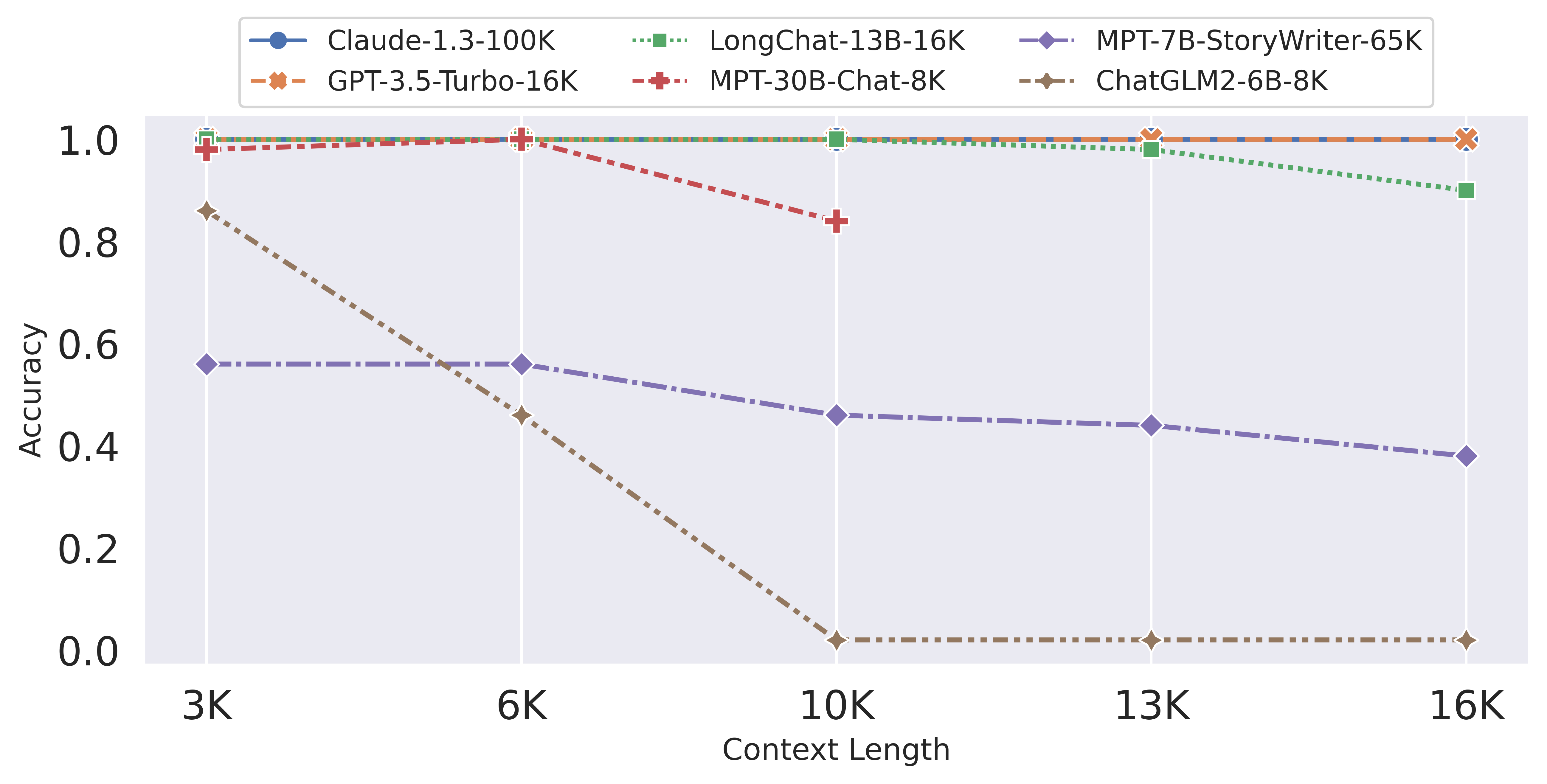
Figure 1: Comparing LongChat to other models on the long-range topic retrieval task.
Not only can LongChat models handle such a long context length, but they also precisely follow human instructions in dialogues and demonstrate strong performance in the human preference benchmark MT-Bench. Their preview versions are available at HuggingFace: lmsys/longchat-13b-16k and lmsys/longchat-7b-16k. You can try them immediately in CLI or web interface using FastChat:
python3 -m fastchat.serve.cli --model-path lmsys/longchat-7b-16k
There has been a significant surge of interest within the open-source community in developing language models with longer context or extending the context length of existing models like LLaMA. This trend has led to interesting observations and extensive discussions in various sources, such as Kaiokendev’s blog and this arXiv manuscript; meanwhile, several notable models have been released claiming to support much longer context than LLaMA, notable ones include:
- MPT-7B-storywriter supports 65K context length and extrapolates to 84K.
- MPT-30B-chat supports 8K context length.
- ChatGLM2-6B supports 8K context.
At LMSYS Org, we have been concurrently exploring various techniques to lengthen the context of our models like Vicuna. In this blogpost, alongside the release of the LongChat series, we share our evaluation tools to verify the long-context capability of LLMs.
Using our evaluation tools in combination with various academic long-context evaluation benchmarks, we conduct a thorough comparison of several open-source and commercial models that claim to support long context. Through this analysis, we examine how well these models deliver on their promised context length. We found that while commercial models like GPT-3.5-turbo performs well on our tests, many open source models do not deliver the expected results on their promised context length.
The data and code used to reproduce the results in the blog post are available in our LongChat repo. We provide a visualization in this notebook.
LongChat Training Recipe
LongChat is finetuned from LLaMA models, which were originally pretrained with 2048 context length. The training recipe can be conceptually described in two steps:
Step 1: Condensing rotary embeddings
Rotary position embedding is a type of positional embedding that injects the information of position in Transformer. It is implemented in Hugging Face transformer by:
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
Where position_ids are indices such as 1, 2, 3, ... that denote the position of a token in the sentence.
For instance, the token "today" in the sentence "today is a good day" has position_ids 1.
The apply_rotary_pos_emb() function then applies a transformation based on the provided position_ids.
The LLaMA model is pre-trained with rotary embedding on sequence length 2048, which means that it has not observed scenarios where position_ids > 2048 during the pre-training phase. Instead of forcing the LLaMA model to adapt to position_ids > 2048, we condense position_ids > 2048 to be within 0 to 2048. Intuitively, we conjecture this condensation can maximally reuse the model weights learned in the pre-training stage. See more insights from Kaiokendev’s blog.
We define the term condensation ratio by dividing the target new context length y by 2048. We then divide every position_ids by this ratio and feed it into the apply_rotary_pos_emb() function.
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids / ratio)
In this release, we fine-tune the model to a context length of 16384, and thus the condensation ratio is 8. For instance, a token with position_ids = 10000 becomes position_ids = 10000 / 8 = 1250, and the neighboring token 10001 becomes 10001 / 8 = 1250.125. This step requires no training.
Step 2: Finetuning on Curated Conversation Data
After condensing the embedding, we perform the finetuning procedure on our curated conversation dataset.
We reuse our collected user-shared conversations previously used for training Vicuna.
We clean the data using FastChat data pipeline, and truncate these conversations so they are no longer than 16K.
We finetune the model using standard next-token prediction loss. We fine-tune the 7B and 13B models with 80k and 18k conversations, respectively.
To save memory, we use Pytorch FSDP and Flash Attention. Assume A100 is $3/hour on Cloud, the 7B model costs ~$300, and the 13B model costs ~$700.
Evaluation toolkits: LongEval
Recently, commercial and open-source models have continued to tout their abilities to support expanded context length (from 8K, 32K, 84K, to 100K) in their latest releases, but how can we verify these claims? The term "long-context capability" can mean different things for different model providers. For instance, does MPT-7B-StoryWriter's advertised 84K context length operate at the same capacity as OpenAI’s ChatGPT at 16K? This issue is also prevalent in our LongChat models development: how do we swiftly and effectively confirm if a freshly trained model can handle the intended context length?
To address this, we can base our evaluations on tasks that necessitate LLMs to process lengthy contexts, such as text generation, retrieval, summarization, and information association in long text sequences. Inspired by recent discussions, we've devised, LongEval, a long context test suite. This suite incorporates two tasks of varying degrees of difficulty, providing a simple and swift way to measure and compare long-context performance.
Task 1: Coarse-grained Topic Retrieval
In real-world long conversations, users usually talk about and jump between several topics with the chatbot. The Topic Retrieval task mimics this scenario by asking the chatbot to retrieve the first topic in a long conversation consisting of multiple topics. An example task is:
… (instruction of the task)
USER: I would like to discuss <TOPIC-1>
ASSISTANT: Sure! What about xxx of <TOPIC-1>?
… (a multi-turn conversation of <TOPIC-1>)
USER: I would like to discuss <TOPIC-2>
…
USER: I would like to discuss <TOPIC-k>
…
USER: What is the first topic we discussed?
ASSISTANT:
This task tests whether the model can locate a chunk of text and associate it with the right topic name. We design a conversation to be 400 ~ 600 tokens long. Thus, this task is considered coarse-grained because the model may give correct predictions when it locates positions not too far away (<500 token distance) from the right ones.
Task 2: Fine-grained Line Retrieval
To further test the model ability to locate and associate texts from a long conversation, we introduce a finer-grained Line Retrieval test. In this test, the chatbot needs to precisely retrieve a number from a long document, instead of a topic from long multi-round conversations. Below is an example:
line torpid-kid: REGISTER_CONTENT is <24169>
line moaning-conversation: REGISTER_CONTENT is <10310>
…
line tacit-colonial: REGISTER_CONTENT is <14564>
What is the <REGISTER_CONTENT> in line moaning-conversation?
The task was originally proposed in Little Retrieval Test. The original testcase uses numbers to denote a line, which we found smaller LLMs usually cannot comprehend well. To disentangle these factors and make them more suitable for testing open-source chatbots at various sizes, we improve it by using random natural language (e.g., torpid-kid) instead.
We found these two tasks behave with the expected characteristics:
- The task can effectively capture the abilities of text generation, retrieval, and information association at long context, reflected by the retrieving accuracy.
- It is easy to extend the tests to arbitrary lengths to test models’ capacity under different context lengths.
- We have run sanity checks of both tasks and observed the expected results. For example, the vanilla LLaMA models, pretrained with a 2K context length, can achieve perfect accuracy on both tasks when the test inputs length is <2K, but will immediately fail (nearly 0 accuracy) on any test inputs beyond 2K.
More details and example usage of LongEval can be found in this notebook.
Results and findings
In this section, we share our evaluation and findings.
Table 1. Model Specifications.
| Model | Size | Instruction-tuned? | Pretrained Context Length | Finetune Context Length | Claimed Context Length | Open Source? |
|---|---|---|---|---|---|---|
| MPT-30-chat | 30B | Yes | 8K | - | 8K | Yes |
| MPT-7b-storywriter | 7B | Yes | 2K | 65K | 84K | Yes |
| ChatGLM2-6b | 6B | Yes | 32K | 8K | 8K | Yes |
| LongChat-13b-16k (ours) | 13B | Yes | 2K | 16K | 16K | Yes |
| GPT-3.5-turbo | - | - | - | - | 16K | No |
| Anthropic Claude-1.3 | - | - | - | - | 100K | No |
In particular, we consider four open-sourced models and two proprietary models, listed in Table 1.
LongEval results
From the coarse-grained topic retrieval test results (Figure 2 at the beginning), we observe the problematic performance of open-source long-context models. For instance, MPT-7B-storywriter claims to have a context length of 84K but barely achieves 50% accuracy even at one-fifth of its claimed context length (16K). ChatGLM2-6B cannot reliably retrieve the first topic at the length of 6K (46% accuracy). On the other hand, LongChat-13B-16K model reliably retrieves the first topic, with comparable accuracy to GPT-3.5-turbo.
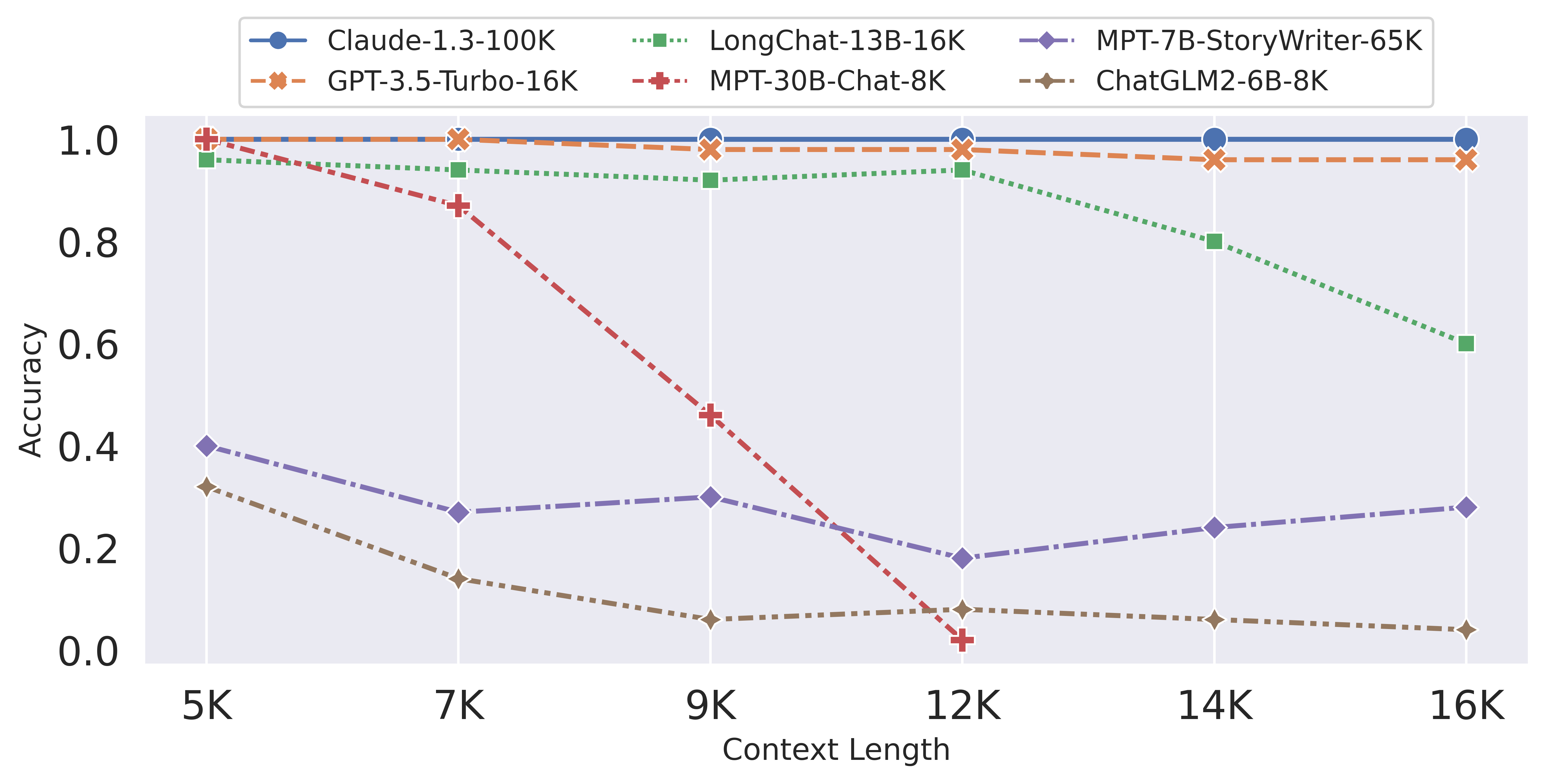
Figure 3: Accuracy on the long-range line retrieval task.
In the fine-grained line retrieval test, MPT-7B-storywriter performs even worse -- the accuracy drops from ~50% to ~30%. ChatGLM2-6B also observes degradation and does not perform well at 5K context length (32%). We notice that ChatGLM2-6B states that it has not been yet fully optimized for single-turn long document understanding, which could explain its current performance on LongEval. LongChat-13B-16K performs closely to GPT-3.5 and Claude-v3 within 12K context length. However, we also find the preview versions are not perfect at 12K-16K, see the discussion section.
Disentangle irrelevant LLM abilities in LongEval
In topics and line retrieval tests, we observe mistakes caused by factors irrelevant to long-context ability, such as the instruction-following ability. For instance, in the Line Retrieval test, the model may simply respond “sure, I will tell you the number” instead of returning an actual number. To give a fair comparison, we took two actions to avoid factors irrespective of long-context capabilities: prompt engineering and estimating accuracy only based on cases in which the models correctly follow instructions. Check our codes for details.
Human preference benchmark (MT-bench)
In the previous section, we observed that LongChat models perform well on long-range retrieval tasks, but does this come with a significant drop in human preference? To test whether it still follows human preferences, we use GPT-4 graded MT-bench, a set of challenging multi-turn conversation questions.
Table 2. MT-bench scores comparing LongChat-13B to other models of similar sizes.
| Model | MT-bench (score) |
|---|---|
| LongChat-13B-16K | 5.95 |
| Vicuna-13B | 6.39 |
| WizardLM-13B | 6.35 |
| Baize-v2-13B | 5.75 |
| Nous-Hermes-13B | 5.51 |
| Alpaca-13B | 4.53 |
We find that LongChat-13B-16K is comparable to its closest alternative -- Vicuna-13B, which indicates that this long-range ability does not come with a significant sacrifice of its short-range ability. At the same time, LongChat-13B-16K is competitive compared to other models of similar sizes.
Long sequence question answer benchmark
In the previous sections, we tested models on our long-range retrieval tasks and human preference tasks. But how do these models perform on more complex academic long-range reasoning tasks? In this section, we study this by running the Qasper question answering dataset. We use the validation set selection and prompts from the ZeroScrolls long sequence benchmark.
Table 3. ZeroScrolls benchmark (validation set)
| Benchmark | LongChat-13B-16K | LongChat-7B-16k | Vicuna-13B-v1.3 | Vicuna-7B-v1.3 | GPT-4-8k |
|---|---|---|---|---|---|
| Qasper (F1) | 0.286 | 0.275 | 0.220 | 0.190 | 0.356 |
We find that LongChat significantly outperforms Vicuna due to its extended context length. We leave more rigorous analysis on academic benchmarks for future work.
Discussion
We find that LongChat-13B-16K experiences an accuracy drop when the context length is near 16K on the fine-grained line retrieval task. In our preliminary attempts, we conjecture that this is because it is near the maximal fine-tuning length. For instance, training on even longer (e.g., 32K) documents can alleviate this problem. We are actively address this issue in a near-future release.
Conclusion
In our evaluations, commercial long-context models always fulfill their promises: GPT-3.5-16K and Anthropic Claude-v3 (almost) achieve perfect performance in both benchmarks. However, existing open-source models often do not perform well in their claimed context length.
Table 4. Ability levels of open source models supporting long context
| Claimed Context Length | Text generation | Coarse Retrieval | Fine-grained Retrieval | |
|---|---|---|---|---|
| Ability Description at claimed context length | - | Faithfully generate natural languages | Retrieve information in a coarse granularity | Retrieve information precisely in a fine-grained granularity |
| LongChat-13B-16K | 16K | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| MPT-30B-chat | 8K | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| MPT-7B-storywriter | 80K | ⭐⭐⭐ | ⭐⭐ | ⭐ |
| ChatGLM2-6B | 8K | ⭐⭐⭐ | ⭐⭐ | ⭐ |
| GPT-3.5-turbo | 16K | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Anthropic Claude-1.3 | 100K | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
We qualitatively illustrate the level of performance in Table 4, and we would like to make our final thoughts -- There are gaps between being able to generate coherent text and being able to retrieve or reason on long context. We call for the community to contribute to more evaluation benchmarks of long-context chatbots and further understand and bridge the gap.
Next Steps
Inspired by the promising performance and the simple training recipe of our 16K models, we would like to explore how to build chatbots with even longer context. We have observed many efficiency issues (e.g., memory and throughput) during training and inference using chatbots with much longer context length. We plan to develop new system technologies to improve LLMs' performance at long context.
Disclaimer
The benchmark LongEval introduced in this blogpost is not yet a comprehensive benchmark that should be used as the only indicator. We are actively working on more systematic benchmarking.
The Team
The LongChat models and this blog post are developed, evaluated, and maintained by the following members: Dacheng Li*, Rulin Shao*, Anze Xie, Ying Sheng, Lianmin Zheng, Joseph E. Gonzalez, Ion Stoica, Xuezhe Ma, Hao Zhang.
(* Joint first author)
Citation
If you find our LongChat models or LongEval tools helpful, please consider citing this blog post via:
@misc{longchat2023,
title = {How Long Can Open-Source LLMs Truly Promise on Context Length?},
url = {https://lmsys.org/blog/2023-06-29-longchat},
author = {Dacheng Li*, Rulin Shao*, Anze Xie, Ying Sheng, Lianmin Zheng, Joseph E. Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang},
month = {June},
year = {2023}
}