HiSparse: Turbocharging Sparse Attention with Hierarchical Memory
Why sparse attention leaves performance on the table
Self-attention has become a major bottleneck in scaling LLMs to long contexts because of its quadratic compute and memory/IO cost. This has driven growing interest in efficient attention mechanisms. Among them, sparse attention is especially promising: by attending to only a selected subset of KV caches, it retains strong modeling capability while avoiding the sharp increase in compute and I/O costs that regular attention faces as context grows.
However, sparse attention—typically top-k selection—does not eliminate the memory capacity bottleneck. In practice, the KV cache for the full context must remain in GPU HBM for fast access, even though only a small fraction of entries are active at any given decoding step. As a result, sparse attention is often capacity-bound rather than compute-bound, limiting the achievable batch size and overall throughput. As shown in the figure below, token-generation throughput of the baseline (sparse attention without HiSparse) plateaus early because the KV cache footprint quickly hits the GPU memory capacity limit. By comparison, HiSparse achieves near-linear throughput scaling with increasing concurrency, reaching over 3× the baseline throughput at 256 concurrent requests. Note that at low concurrency, HiSparse introduces modest overhead, as the extra I/O from sparse KV loading outweighs the memory savings. The gains become pronounced as concurrency increases and memory pressure dominates.

Benchmark results for the GLM-5.1-FP8 model using 32k-input, 8k-output queries on a PD-colocated 8×H200 deployment.
Design of HiSparse
In line with our prior work, HiCache, we propose HiSparse: a hierarchical memory system designed to overcome this limitation. HiSparse proactively offloads inactive KV cache entries to host memory, significantly reducing GPU memory pressure, while maintaining a hot device buffer on GPU HBM for frequently accessed KV regions to minimize data movement on the critical path. This enables much larger decoding batch sizes, improving throughput while scaling to longer contexts. The diagram below illustrates the HiSparse workflow. Although depicted in a prefill–decode disaggregated setup, the design applies equally to co-located instances.
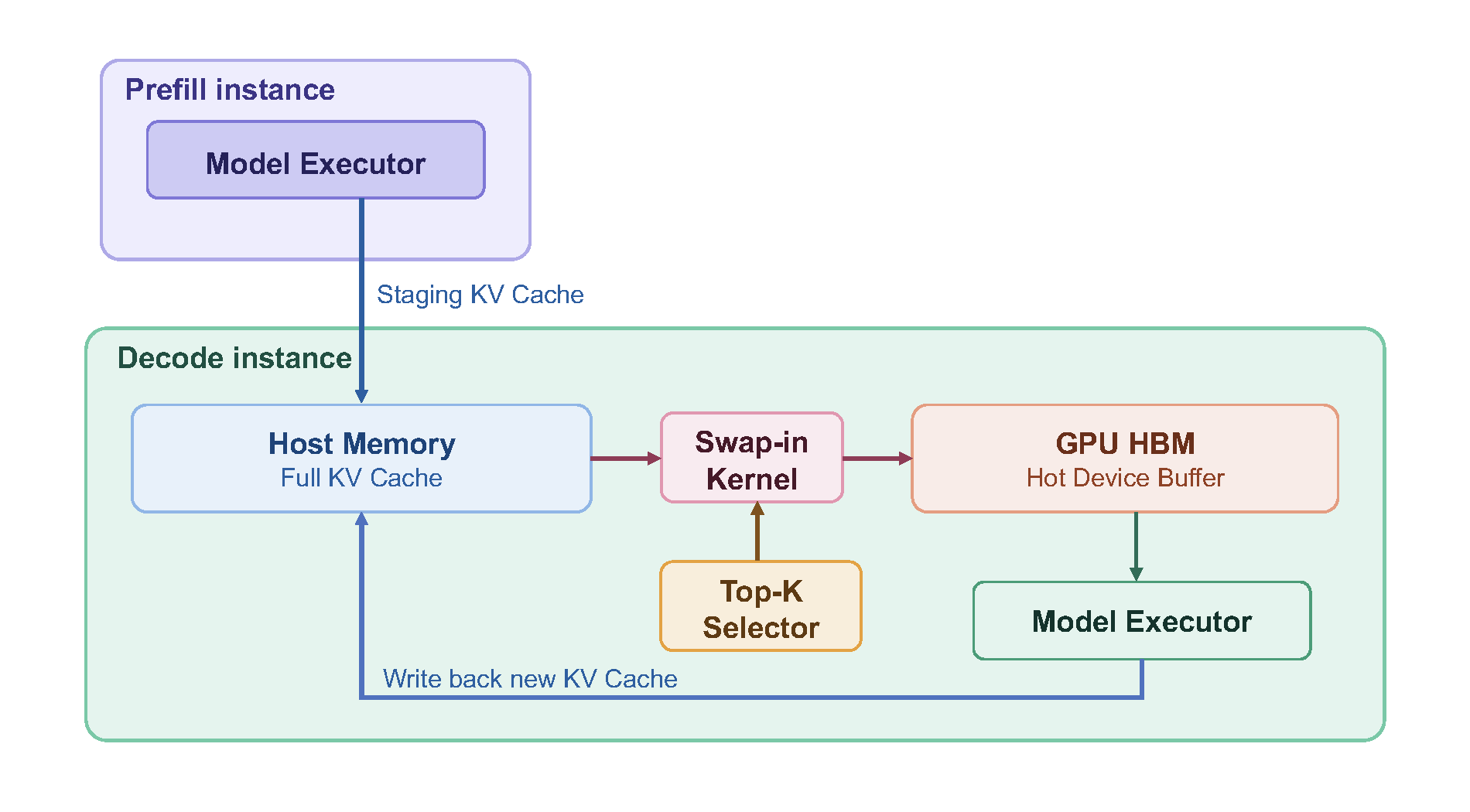
Efficient Swap-in Kernel
Central to this system is a specialized CUDA kernel that efficiently:
(1) identifies top-k cache misses in the device buffer, (2) selects eviction candidates via an LRU policy, and (3) updates the page table and fetches the required entries from host to device memory.
The figure below illustrates the impact of hot-buffer sizing and eviction policy on miss rates. With a larger hot device buffer (4096 vs. 2048 slots) and LRU eviction, miss counts drop substantially, directly translating to lower swap-in latency on the critical path.

Cache miss count benchmark results for DeepSeek-V3.2 (top-k=2048) on LongBenchV2, with miss counts smoothed using a 100-step rolling window.
Benchmark
Below, we highlight results from sweeping various sequence configurations for a state-of-the-art open model GLM-5.1-FP8, achieving up to 5x throughput improvement on long context scenarios, and you can find more detailed instructions here.

Benchmark results for the GLM-5.1-FP8 model across various input and output sequence length configurations on a two-H20 PD-disaggregated deployment.
# PD-disaggregation deployment (recommended) on two H20 nodes
# prefill instance:
python3 -m sglang.launch_server \
--model-path "zai-org/GLM-5.1-FP8" --trust-remote-code --watchdog-timeout 100000 \
--chunked-prefill-size 65536 --max-running-requests 480 --mem-fraction-static 0.8 \
--tp-size 8 --dp-size 8 --enable-dp-attention --schedule-conservativeness 0.5 \
--disaggregation-mode prefill \
--disaggregation-ib-device mlx5_0,mlx5_1,mlx5_2,mlx5_3 \
--dist-init-addr 127.0.0.1:5757 --nnodes 1 --node-rank 0
# decode instance:
python3 -m sglang.launch_server \
--model-path "zai-org/GLM-5.1-FP8" --trust-remote-code --watchdog-timeout 100000 \
--chunked-prefill-size 65536 --max-running-requests 480 --mem-fraction-static 0.85 \
--tp-size 8 --dp-size 8 --enable-dp-attention \
--load-balance-method round_robin --prefill-round-robin-balance \
--kv-cache-dtype bfloat16 --nsa-decode-backend flashmla_sparse \
--disaggregation-mode decode --dist-init-addr 127.0.0.1:5757 \
--disaggregation-ib-device mlx5_0,mlx5_1,mlx5_2,mlx5_3 --nnodes 1 --node-rank 0 \
--enable-hisparse \
--hisparse-config '{"top_k": 2048, "device_buffer_size": 6144, "host_to_device_ratio": 10}'
# PD-colocation deployment on a single 8xH200 instance
python3 -m sglang.launch_server \
--model-path "zai-org/GLM-5.1-FP8" --trust-remote-code --watchdog-timeout 100000 \
--chunked-prefill-size 65536 --max-running-requests 480 --mem-fraction-static 0.85 \
--tp-size 8 --dp-size 8 --enable-dp-attention --disable-radix-cache \
--enable-hisparse \
--hisparse-config '{"top_k": 2048, "device_buffer_size": 4096, "host_to_device_ratio": 8}'
Future Work
HiSparse currently supports model families that use DeepSeek Sparse Attention (DSA), including DeepSeek-V3.2 and GLM-5.1. As an experimental feature, we expect to continue improving both performance and model coverage. HiSparse is designed for high-concurrency scenarios to maximize throughput; however, it also introduces some overhead due to the additional IO incurred by top-k cache misses. We expect to reduce this overhead through better overlap, and believe it will be further mitigated by the higher CPU–GPU bandwidth of emerging platforms such as Grace Blackwell (GB) systems.
Looking ahead, following the direction of our earlier HiCache work, we plan to extend this hierarchical memory management approach to support a broader range of emerging architectures, including hybrid models.
Acknowledgements
We would like to thank the Alibaba Cloud TairKVCache team and the Ant Group SCT Inference team for their valuable contributions. We are also grateful to Shangming Cai, Teng Ma, and Xingyu Ling from Alibaba Cloud, and to Ziyi Xu from the SGLang community, for their generous support. We further thank Christos Kozyrakis and Kristopher Geda from Stanford, as well as the Baidu Baige AI Team, for their thoughtful feedback.