Heterogeneous CPU + GPU EPD Disaggregation to Boost VLM Serving
TL;DR
We enabled heterogeneous Encode-Prefill-Decode (EPD) disaggregation via Dynamo and SGLang for Vision-Language Models (VLMs). By offloading vision encoding tasks to CPUs (the easiest-getting CPU resource is the CPU in head node), we achieved consistent performance improvements across metrics: TTFT (Time to First Token), TPOT (Time Per Output Token), and overall throughput under load.
Introduction
The SGLang community has already demonstrated the necessity and benefits of EPD disaggregation to VLM serving ^{[1]}. It shows that EPD can significantly reduce TTFT in image-heavy scenarios where multi-images are fed into the service. With the observation that vision encoding is the primary computational bottleneck in image-heavy scenarios, we see offloading some vision encoding work to the head node CPU can help improve performance:
- Vision encoder (CNN/ViT) is usually smaller than language model part, which makes modern CPUs equipped with advanced matrix accelerators (e.g. AMX in Intel Xeon CPUs) be able to help.
- Vision encoding only happens during prefill, which makes it easy to plug in a heterogenous worker, without the needing of continuous cross-worker state management
Device-Aware Weighted Router
By collaborating with Dynamo community, we merged a new device-aware weighted router mode into Dynamic router to support heterogeneous dispatching(PR #7215). It introduces a budget-based throttle between devices (specifically CPU vs. GPU).
In a heterogeneous deployment environment where computing capabilities vary (e.g., a GPU vs. a CPU), the device-aware weighted router uses a Capability Ratio to define the relative throughput of the GPU against CPU. The router calculates an Allowed CPU In-flight Budget (). This budget represents the maximum number of requests the CPU pool should handle to stay "in sync" with the current pressure on the GPU pool:
Here, is total in-flight requests across all GPU instances, and is the count of GPU and CPU instances, respectively.
The routing decision is straightforward, when (total in-flight requests across all CPU instances) is less than , it means CPU pool is under-utilized relative to its normalized capacity, so route to CPU pool; else, route to GPU pool.
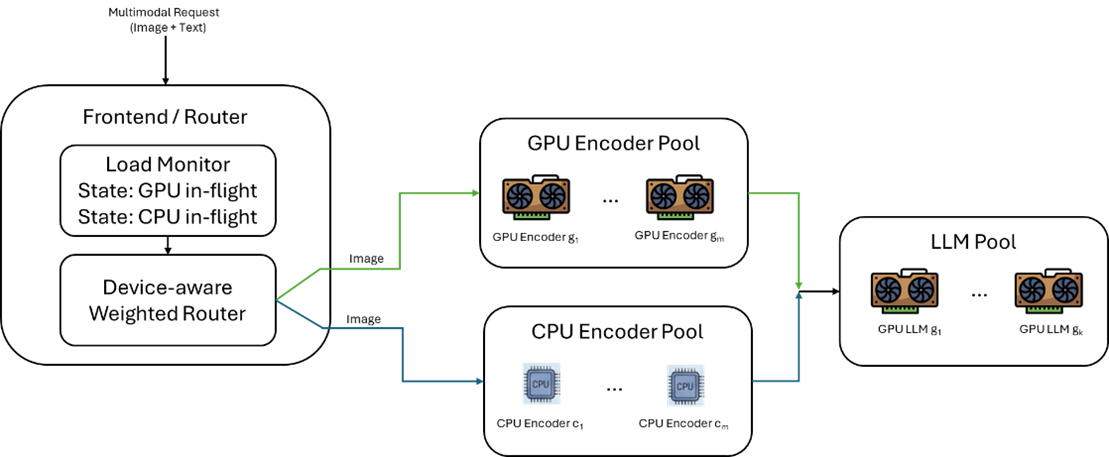
Figure 1. device-aware weighted router
Experiment Setup
Use Case Configuration
Environment:
- Intel(R) Xeon(R) 6747P CPUs (2 sockets, 2 NUMA nodes per socket, in total 4 NUMA nodes)
- 5x L40S CUDA GPUs
Model:
- Qwen3-VL-8B-Instruct
Dataset:
- ISL/OSL: 128/256
- Image Resolution: 1080p
- Image count: 8
- QPS Range: 1.0, 1.2, 1.5, 2.0
Deployment Configurations:
- 1E/4PD (Encoder: 1 GPU Encoder, PD: 4 GPU)
- (4 CPU + 1 GPU) E/4PD (Encoder: 4 CPU + 1 GPU, PD: 4 GPU), Capability Ratio is set to be 12
Use Case Launch Scripts
Launch vision encoder instances:
# launch cuda encoder
CUDA_VISIBLE_DEVICES=0 numactl --cpunodebind=0 --membind=0 python -m dynamo.sglang --multimodal-encode-worker --model-path "$MODEL_NAME" --chat-template "$CHAT_TEMPLATE" --embedding-transfer-mode nixl-read &
# launch cpu encoders, DYN_ENCODER_CUDA_TO_CPU_RATIO is 12 in this case
for node in 0 1 2 3; do 12
case "$node" in
0) cpus="$(printf "%s\n%s\n" "$(seq 0 2 46)" "$(seq 96 2 142)" | paste -sd, -)" ;;
1) cpus="$(printf "%s\n%s\n" "$(seq 48 2 94)" "$(seq 144 2 190)" | paste -sd, -)" ;;
2) cpus="$(printf "%s\n%s\n" "$(seq 1 2 47)" "$(seq 97 2 143)" | paste -sd, -)" ;;
3) cpus="$(printf "%s\n%s\n" "$(seq 49 2 95)" "$(seq 145 2 191)" | paste -sd, -)" ;;
esac
CUDA_VISIBLE_DEVICES="" \
SGLANG_USE_CPU_ENGINE=1 \
SGLANG_CPU_OMP_THREADS_BIND="$cpus" \
numactl --cpunodebind="$node" --membind="$node" \
python -m dynamo.sglang \
--multimodal-encode-worker \
--model-path "$MODEL_NAME" \
--chat-template "$CHAT_TEMPLATE" \
--embedding-transfer-mode nixl-read &
done
Launch the PD instance:
# launch PD instances
for gpu in 2 3 4 5; do
if [[ "$gpu" -lt 4 ]]; then
numa_node=0
else
numa_node=1
fi
CUDA_VISIBLE_DEVICES="$gpu" \
numactl --cpunodebind="$numa_node" --membind="$numa_node" \
python3 -m dynamo.sglang \
--multimodal-worker \
--model-path "$MODEL_NAME" \
--page-size 16 \
--tp 1 \
--prefill-max-requests 1 \
--log-level debug \
--trust-remote-code \
--skip-tokenizer-init \
--disable-radix-cache \
--embedding-transfer-mode nixl-read \
--disaggregation-transfer-backend nixl &
done
Launch router:
DYN_ENCODER_CUDA_TO_CPU_RATIO=12 python3 -m dynamo.frontend --router-mode device-aware-weighted
Benchmark
Benchmark Script
python -m sglang.bench_serving.py --model Qwen/Qwen3-VL-8B-Instruct --num-prompts 32 --dataset-name image --random-input-len 128 --random-output-len 256 --image-count 8 --image-resolution 1080p --host localhost --port 8000 --backend sglang-oai-chat --request-rate $QPS
Benchmark Results
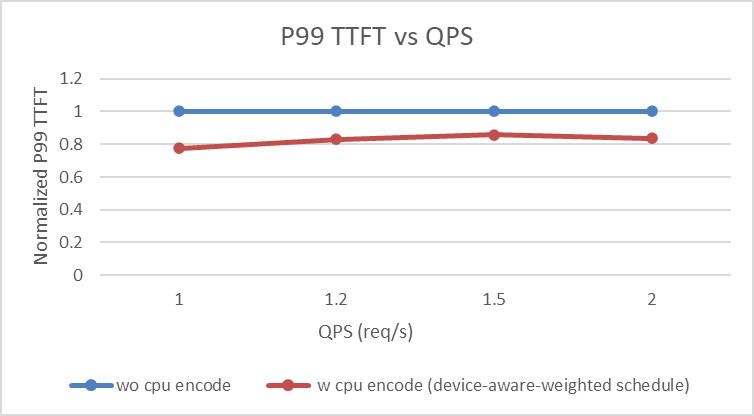
P99 TTFT
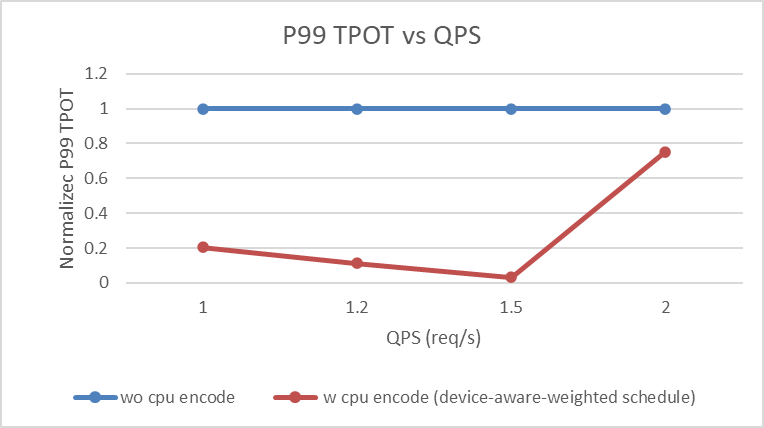
P99 TPOT
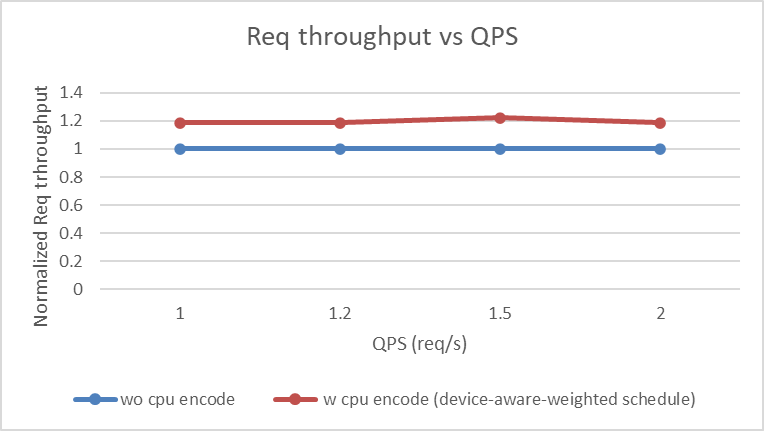
Request Throughput
Key Findings:
- Heterogeneous CPU + GPU EPD disaggregation brings consistent better performance over pure GPU EPD disaggregation across all metrics (TTFT, TPOT, request throughput) under load (QPS between 1 and 2).
- ~1.2x-1.3x P99 TTFT and request throughput improvement can be observed, indicating CPU helps offloading the vision encoder burden of GPU under load.
- Significant ~1.3x-30x P99 TPOT reduction is achieved by relieving vision encoding traffic and mitigating the 2+ token generation queueing time.
Heterogeneous CPU + GPU EPD disaggregation achieves an extra higher return on investment (ROI) in addition to the ROI brought by the pure GPU EPD disaggregation almost for free. This is achieved by the system-level optimization which includes the AMX powered CPU into the solution space with a whole system view.