SGLang and Miles Add Day-0 Support for NVIDIA Nemotron 3 Ultra for Long-Running Autonomous Agents

We are excited to announce that SGLang and Miles support NVIDIA Nemotron 3 Ultra on Day 0.
Agentic AI systems are moving from short prompt-response interactions to persistent workflows that plan, use tools, inspect results, recover from failures, and continue working across long task horizons. These agents need strong reasoning, fast inference, long-context understanding, and reliable tool use in the same deployment stack.
Nemotron 3 Ultra is built for this class of workloads.
Part of the Nemotron family of open models, Nemotron 3 Ultra is an open frontier reasoning model designed for long-running autonomous agents. It is optimized for complex orchestration across coding, deep research, enterprise workflows, and EDA use cases where agents must sustain reasoning across many steps and large context windows.
With SGLang, developers can serve Nemotron 3 Ultra through a high-performance inference stack and integrate it into agent frameworks, coding systems, research pipelines, and enterprise automation workflows.
TL;DR: About Nemotron 3 Ultra
- Architecture: Mixture of Experts with Hybrid Transformer-Mamba Architecture
- Model size: 550B total parameters, 55B active parameters
- Context length: Up to 1M tokens
- Modalities: Text input, text output
- Efficiency: High-throughput inference with NVFP4 and BF16 support. NVFP4 checkpoint works on Blackwell GPUs.
- Reasoning: Optimized for long-running autonomous agents, tool calling, coding, deep research, and orchestration
- Training: Post-trained with multi-environment reinforcement learning for robust reasoning and agentic behavior
- Deployment: Open weights, open data, and open recipes for customization and deployment across infrastructure
- Supported GPUs:
- BF16: 8x GB200/GB300/B200/B300, 16x H100, 16x H200,
- NVFP4: 2x GB200/GB300/B200
- Get Started
- Download model weights from Hugging Face - BF16, NVFP4
- Run inference with SGLang using the getting started cookbook
- Read the Nemotron 3 Ultra technical report for architecture, training, and benchmark details
Installation and Quick Start
For an easier setup with SGLang, refer to the Nemotron 3 Ultra getting started cookbook or use the NVIDIA Brev launchable for NVFP4.
Launch the SGLang Docker container:
docker run --rm -it \
--gpus all \
--cap-add SYS_NICE \
--ipc=host \
--network=host \
--shm-size=16g \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e SAFETENSORS_FAST_GPU=1 \
-e NVIDIA_TF32_OVERRIDE=1 \
-e SGLANG_DISABLE_DEEP_GEMM=1 \
--entrypoint /bin/bash \
lmsysorg/sglang:dev-nemotron3-ultra
Serve the model:
The command below is configured for a 8x B200 setup. If your hardware differs, adjust the parallelism flags and related settings for your environment.
python3 -m sglang.launch_server \
--model-path nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-NVFP4 \
--host 0.0.0.0 \
--port 8000 \
--served-model-name nemotron-3-ultra \
--trust-remote-code \
--tensor-parallel-size 8 \
--reasoning-parser nemotron_3 \
--tool-call-parser qwen3_coder
Once the server is running, you can send requests using an OpenAI-compatible client:
from openai import OpenAI
# Set this to the model you launched the server with
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
resp = client.chat.completions.create(
model="nemotron-3-ultra",
messages=[
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "Give me 3 bullet points about SGLang."}
],
temperature=1.0,
top_p=0.95,
max_tokens=512,
)
print("Reasoning:", resp.choices[0].message.reasoning_content)
print("Content:", resp.choices[0].message.content)
Nemotron 3 Ultra Is Built for Long-Horizon Agentic Workloads
Nemotron 3 Ultra is fully open and designed to integrate with major agent frameworks and orchestration platforms. Nemotron 3 Ultra is optimized for agentic systems that need sustained reasoning over many steps. To mitigate the typical efficiency-accuracy tradeoffs for high-capacity reasoning models, the Nemotron models introduce profound architectural innovations:
- Post-Trained for Agent Harness: Nemotron models are post-trained using the NVIDIA NeMo RL and Gym across many agent harnesses. They are optimized for agent leading open harnesses, not just single-turn chat and specifically optimized to work inside workflows where agents plan, call tools, read observations, delegate to sub-agents, validate outputs, and recover from errors across many turns.
- Hybrid Mamba-Transformer: Mamba layers improve sequence efficiency for long-context workloads, while Transformer layers preserve precise recall when agents need to retrieve specific facts from large context windows.
- Latent MoE: Latent MoE supports more efficient expert routing, helping the model handle workflows that span reasoning, code generation, tool calls, and domain-specific logic.
- Multi-Token Prediction (MTP): MTP helps reduce generation time by predicting multiple future tokens in a single forward pass, improving throughput for long outputs and multi-turn workflows.
- NVFP4 precision: The same NVFP4 checkpoint runs on NVIDIA Hopper and Blackwell GPUs, so developers can seamlessly use one checkpoint across both architectures thanks to specialized NVFP4 quantization kernels.
High Throughput with Strong Reasoning Accuracy
Long-running agents benefit when models can complete more reasoning cycles in less time. Nemotron 3 Ultra combines a hybrid Transformer-Mamba MoE architecture, long-context support, and NVIDIA-optimized precision formats to deliver fast, capable inference for demanding agent workloads.
This makes Nemotron 3 Ultra a strong fit for production agent systems where speed, reasoning quality, and deployment flexibility all matter. As shown in Figure 1 and Figure 2, Nemotron 3 Ultra leads on accuracy on agent productivity, instruction following, and long context tasks and saves up to 30% on costs compared to other leading models.
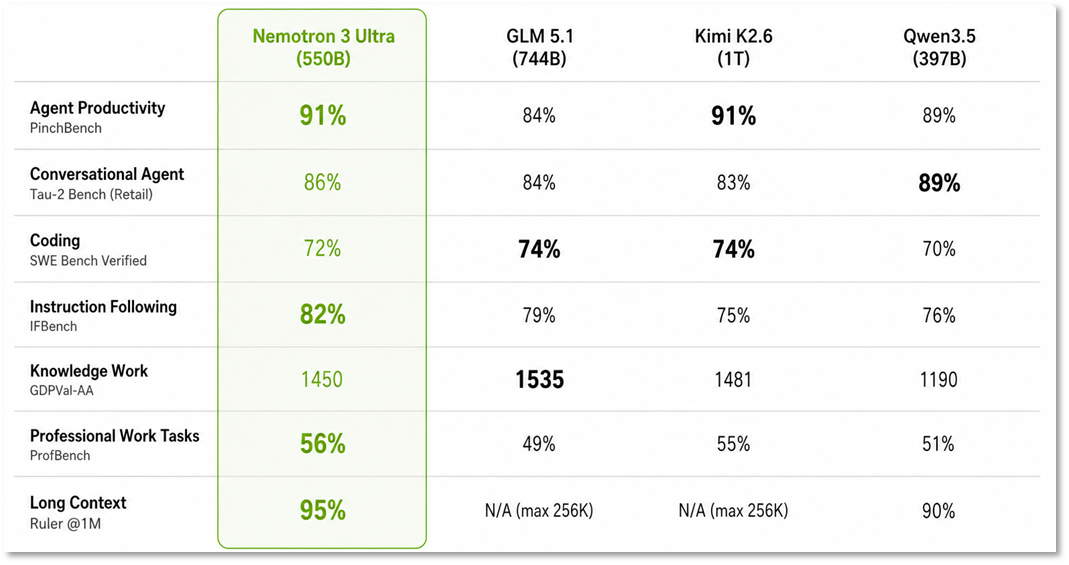
Figure 1: Nemotron 3 Ultra leads among open models on agentic benchmarks for agent productivity, coding, and instruction following.
Alt text: Image of a table showing Nemotron 3 Ultra leading among open models on agentic benchmarks for agent productivity, coding, and instruction following.
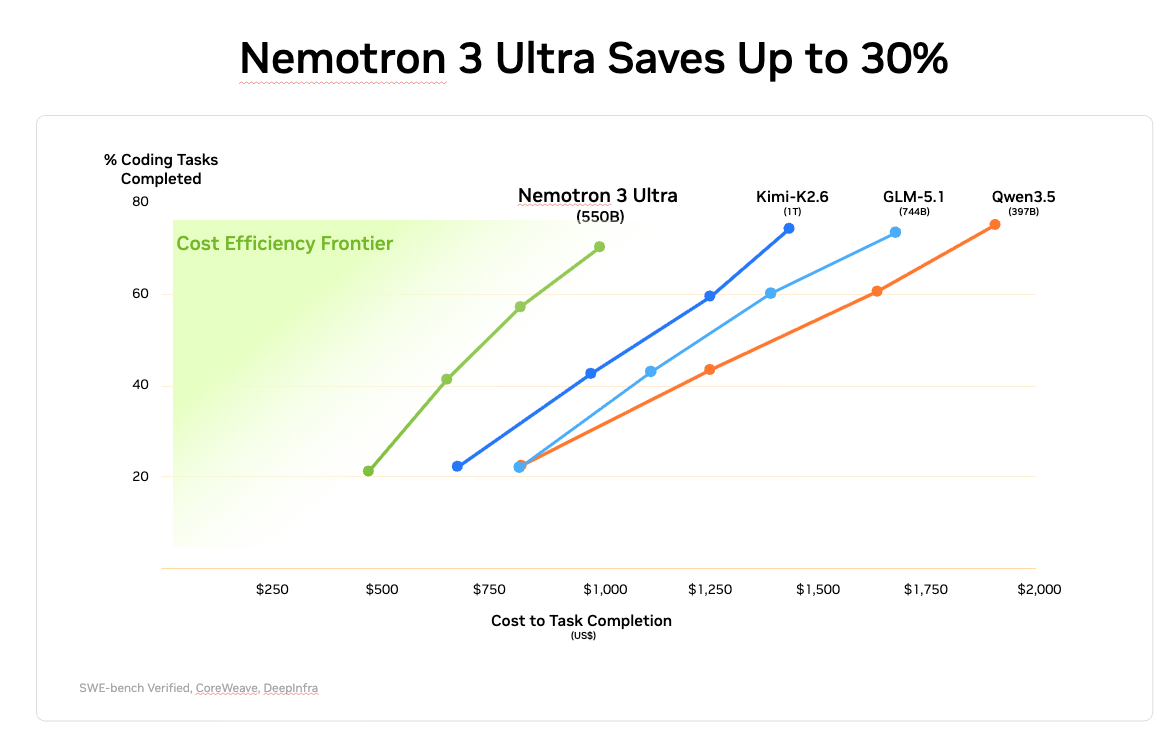
Figure 2: Nemotron 3 Ultra saves up to 30% in costs and leads on the cost efficiency frontier
Alt text: Image showing Nemotron 3 Ultra saves up to 30% in costs and leads on the cost efficiency frontier
Reinforcement Learning -- Miles Support
Using the Miles framework, we've enabled GRPO RL training on Nemotron 3 Ultra across 128 H200 GPUs in colocate mode (training and SGLang rollout sharing GPUs), verified on dapo-math-17k, with a single reproducible Docker image and launch script.
What Miles supports
Parallelism strategies. Miles trains Nemotron 3 Ultra with the multiple set of Megatron parallelism dimensions: TP, PP, EP, and DP.
DP attention for a Mamba-hybrid MoE. The Mamba constraint caps tensor-parallel sharding at 8 (required by n_groups=8), so a pure-TP inference engine is limited to a maximum engine size of 8 GPUs. DP attention lifts this restriction: by running attention (and Mamba) under data parallelism instead of tensor parallelism, each SGLang engine can combine expert parallelism with DP attention to scale to an arbitrary rollout size, enabling large-scale EP.
Verified RL pipeline. The full GRPO loop runs end to end with the deepscaler rule-based reward, and on dapo-math-17k the rollout and training log-probs stay close (about 0.01), which we take as an early indication that the pipeline is behaving on-policy. These are short bring-up runs, so we report them as a sanity check rather than a converged result.
Training Result. The results below are from dapo-math-17k runs on 128 H200 GPUs (16×8) in colocate mode. Training uses TP8 · PP4 · EP32 with DP4 and the optimizer CPU-offloaded; rollout uses 4 × 32-GPU SGLang engines (ep_size=32, dp_size=4, enable_dp_attention) with n_samples=8, and max response length 8192. Checkpoints are converted offline once from HF to Megatron torch_dist, the model is loaded natively via --load in Megatron, with --hf-checkpoint used only for the tokenizer and SGLang. GRPO runs
- On-policyness. A key health check for an RL pipeline is whether the policy used to generate rollouts matches the policy being updated during training. If the two drift apart, the gradients no longer reflect the data the model actually sampled, and training becomes off-policy and unstable. We track this with train_rollout_logprob_abs_diff, the average absolute difference between the log-probabilities assigned to each token by SGLang and Megatron. This value stays around 0.01 throughout the run, a small gap that suggests the rollout and training policies remain closely aligned and the pipeline is behaving on-policy.
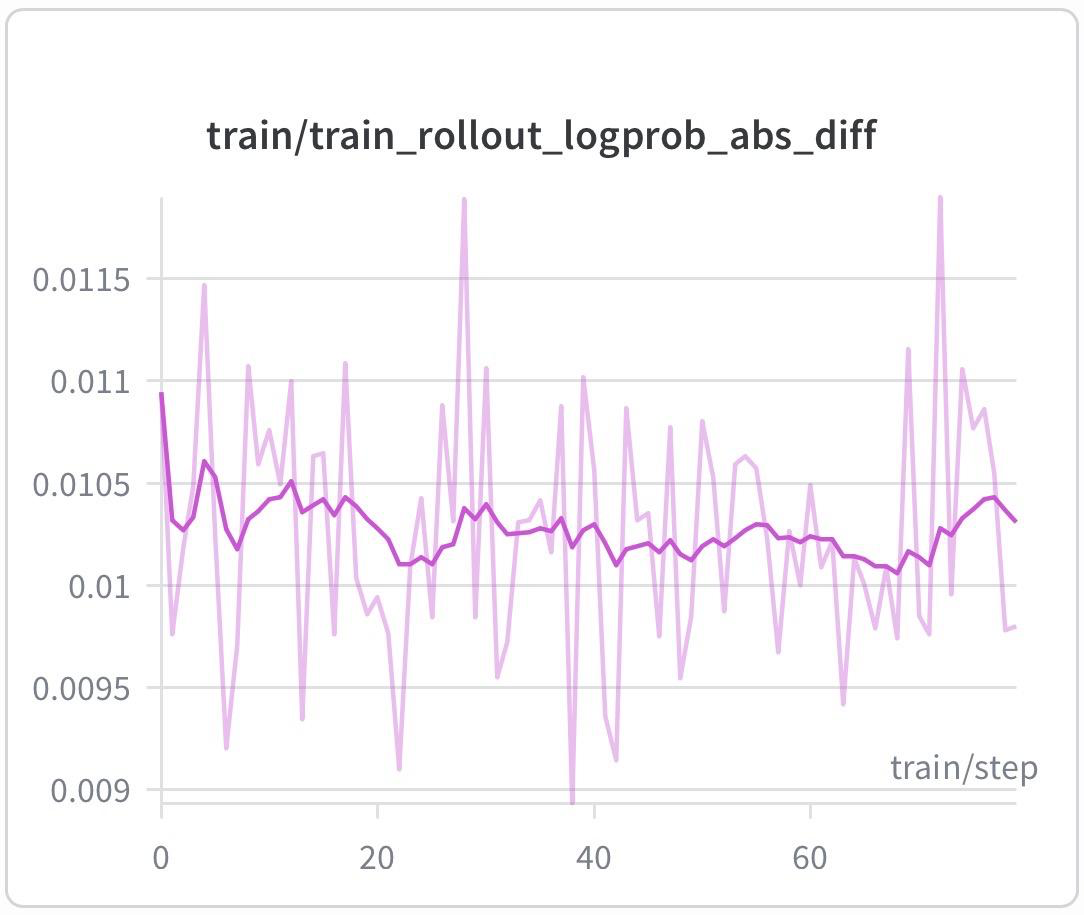 Figure: train_rollout_logprob_abs_diff over a full run; the band stays around 0.01.
Figure: train_rollout_logprob_abs_diff over a full run; the band stays around 0.01.
- Reward curve. As training proceeds, the model should learn to produce answers that score higher under the reward function. We track rollout/raw_reward, the average reward of the model's sampled responses. The reward grows steadily over the run within 30 rollout steps.
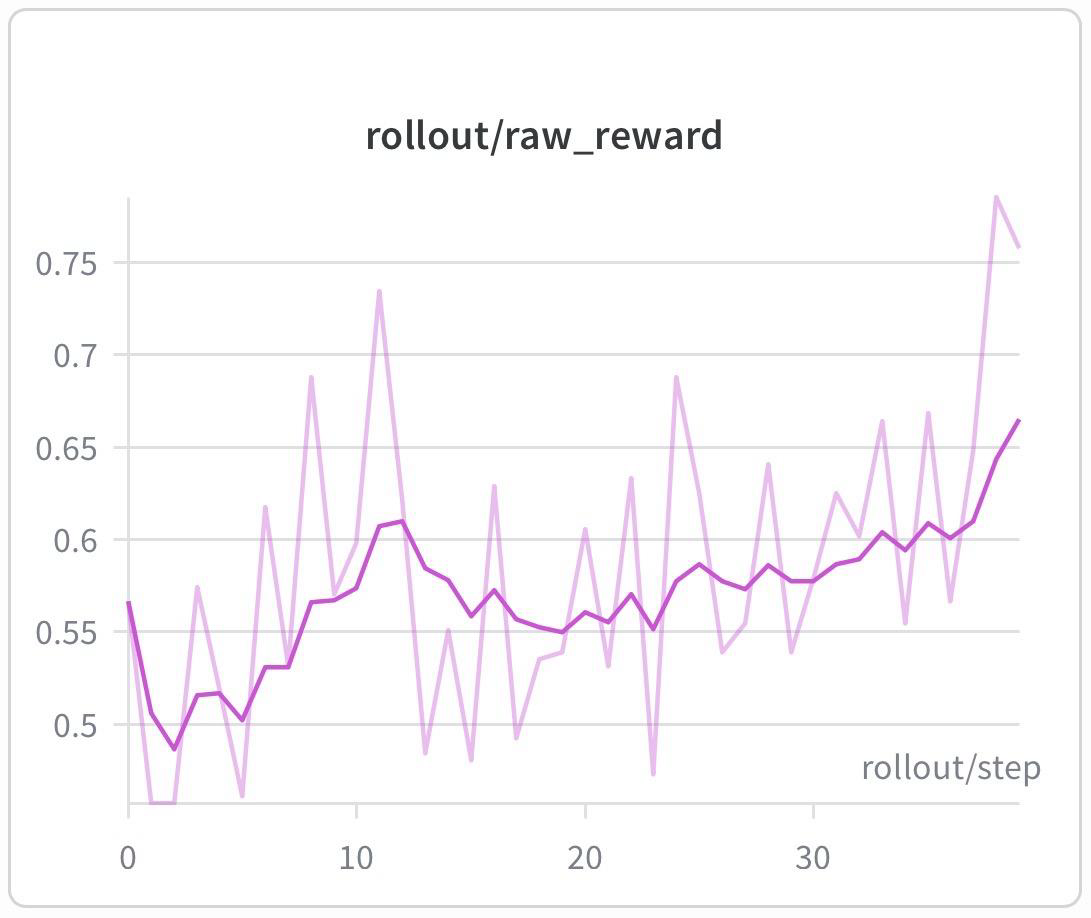 Figure: rollout/raw_reward on dapo-math-17k at 8k max context length, rising from ~0.55 to ~0.58 over the run.
Figure: rollout/raw_reward on dapo-math-17k at 8k max context length, rising from ~0.55 to ~0.58 over the run.
Nemotron 3 Ultra RL example:
## Miles docker image for nemotron-3-ultra
docker pull radixark/miles:nemotron-3-ultra
cd /root/miles
## convert hf to dist
## env (optional): MODELS_DIR=/your/models
HF=$MODELS_DIR/NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16
bash scripts/convert-nemotron-3-ultra-550b-hf-to-dist.sh <NODE_RANK 0..15> <HEAD_IP>
## Launch RL (128 GPU, colocate)
## head pod:
bash scripts/run-nemotron-3-ultra-550b-a55b.sh head <HEAD_IP>
## each worker pod:
bash scripts/run-nemotron-3-ultra-550b-a55b.sh worker <HEAD_IP>
Summary
NVIDIA Nemotron 3 Ultra brings high-throughput frontier reasoning to long-running autonomous agents. With SGLang and Miles Day-0 support, developers can quickly serve or post-train the model and connect it to coding agents, research systems, enterprise automation workflows, and domain-specific agent stacks.
Ready to build faster, more capable agents?
- Download model weights from Hugging Face - BF16, NVFP4
- Run Nemotron 3 Ultra with SGLang using the cookbook
- Read the Nemotron 3 Ultra technical report
Stay up to date on NVIDIA Nemotron by subscribing to NVIDIA news and following NVIDIA AI on LinkedIn, X, YouTube, and the Nemotron channel on Discord.
Acknowledgement
Thanks to everyone who contributed to bringing the NVIDIA Nemotron 3 Ultra to SGLang and Miles.
NVIDIA: Nirmal Kumar Juluru, Anusha Pant, Ryan Stewart, Tomer Asida, Daniel Afrimi, Shaun Kotek, Roi Koren, Daniel Serebrenik, Amir Klein, Omer Ullman Argov, Netanel Haber, Amit Zuker, Shahar Mor, Tomer Bar Natan, Max Xu
SGLang & Miles team: Zhichen Zeng, Jiajun Li, Baizhou Zhang, Brayden Zhong, Cheng Wan, Yueming Yuan, Yuwei An, Banghua Zhu