The next generation of speculative decoding: DFlash and Spec V2
Using Modal and Z Lab's DFlash speculative decoding models with SGLang’s newly default Spec V2 engine, you can achieve state-of-the-art latencies for LLM inference serving. Our new, jointly-released DFlash model for Qwen 3.5 397B-A17B achieves higher throughput than both the baseline model and native MTP speculation in all the settings we benchmarked. At concurrency 1 on the HumanEval coding dataset, it achieves >4.3x the throughput of baseline and 1.5x the throughput of MTP.
 Workload: Qwen 3.5 397B-A17B (BF16), HumanEval. Settings: greedy decoding, thinking enabled, max new tokens 4096. Hardware: 8xB200 on Modal. Acceptance lengths are averaged across requests. Draft token/block counts selected for maximum throughput (MTP: 7 steps; DFlash: block size 16).
Workload: Qwen 3.5 397B-A17B (BF16), HumanEval. Settings: greedy decoding, thinking enabled, max new tokens 4096. Hardware: 8xB200 on Modal. Acceptance lengths are averaged across requests. Draft token/block counts selected for maximum throughput (MTP: 7 steps; DFlash: block size 16).
To celebrate this collaboration, we're releasing this model in triplicate across our Hugging Face organizations:
You can try the model yourself with this command:
export SGLANG_ENABLE_OVERLAP_PLAN_STREAM=1
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-397B-A17B \
--trust-remote-code \
--speculative-algorithm DFLASH \
--speculative-draft-model-path modal-labs/Qwen3.5-397B-A17B-DFlash \
--speculative-dflash-block-size 8 \
--speculative-draft-attention-backend fa4 \
--attention-backend trtllm_mha \
--linear-attn-prefill-backend triton \
--linear-attn-decode-backend flashinfer \
--mamba-scheduler-strategy extra_buffer \
--tp-size 8 \
--max-running-requests 32 \
--cuda-graph-max-bs-decode 32 \
--cuda-graph-backend-prefill tc_piecewise \
--enable-flashinfer-allreduce-fusion \
--mem-fraction-static 0.8 \
--host 0.0.0.0 \
Below, we describe DFlash’s novel diffusion + KV injection strategy for speculative decoding, why that matters for achieving massive speedups, and how the teams at Z Lab, SGLang, and Modal worked together to make those speedups available to everyone.
DFlash: Parallel drafting with KV injection
Transformer-based large language models (LLMs) are powerful, but their autoregressive decoding process makes inference slow: tokens must be generated one by one, with low arithmetic intensity that makes them a poor fit for modern hardware.
Speculative decoding addresses this bottleneck by using a smaller, faster draft model to propose multiple tokens, which are then verified in parallel by the target LLM, with no impact on model quality.
However, many speculative decoding methods, like the EAGLE series and the native multi-token prediction (MTP) modules in recent models like Gemma 4 and DeepSeek-V4, still rely on sequential autoregression – but in the draft model instead of the target. The draft model generates draft tokens one-by-one,a poor fit for modern hardware and a limit on achievable speedup.
That’s why Z Lab developed DFlash, which uses a lightweight block diffusion draft model to generate an entire block of draft tokens in parallel, just the way GPUs and TPUs like. Xiaomi's new MiMo v2.5-Pro-UltraSpeed uses DFlash to achieve over 1k output tps.
Using block diffusion for speculative drafting is non-trivial. Directly training a small block diffusion model as the drafter leads to low acceptance length, while using an existing large diffusion LLM like SpecDiff-2 as the drafter introduces a large memory footprint and high drafting cost.
The key insight of DFlash is simple: the target LLM knows the context best. Inspired by previous methods like Medusa, EAGLE and MTP (Gloeckle et al., 2024; Samragh et al., 2025), we extract hidden representations of the context tokens from the target model. Unlike previous work, we inject them directly into the draft model’s KV cache. This scales better with increased draft depth. KV injection also allows the draft model to skip modeling the full context from scratch and focus purely on predicting the next block of tokens – using the same tensors as the later layers of the target model!
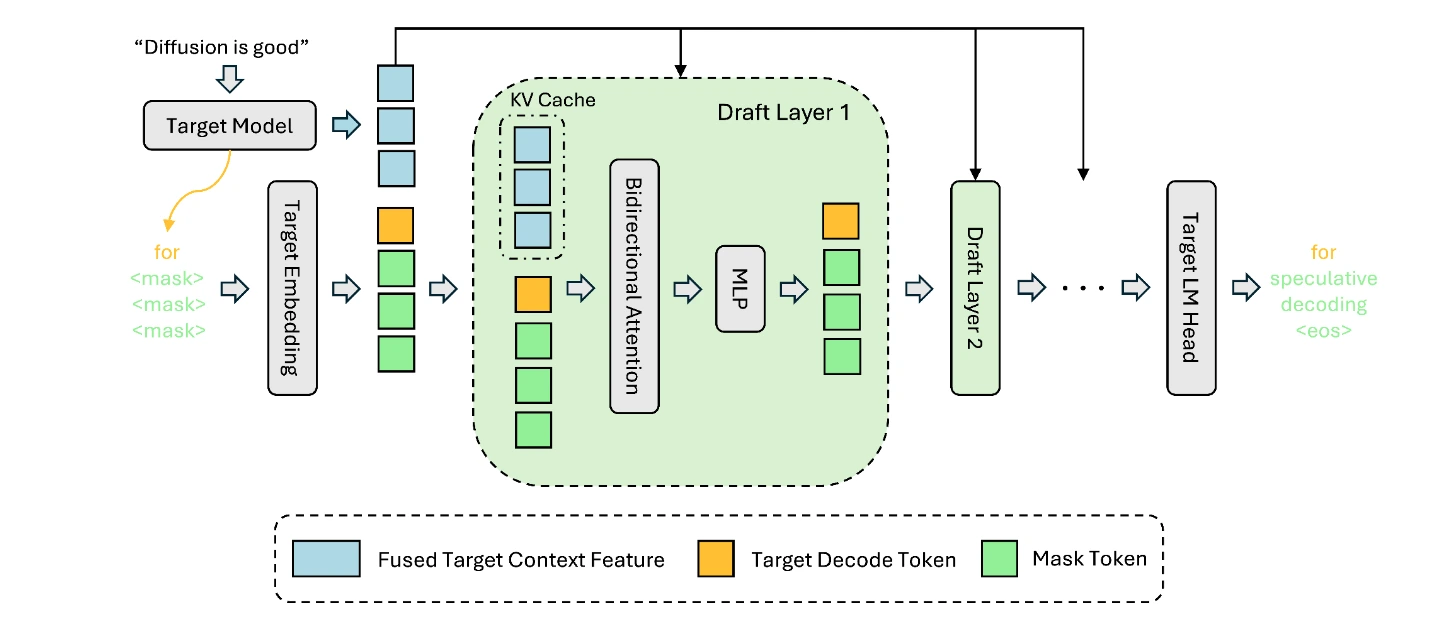
With this design, DFlash leverages the rich, highly relevant contextual features produced by the target LLM while keeping the draft model extremely small and efficient. As a result, DFlash achieves high acceptance length with low drafting latency.
Why is DFlash so fast?
Speculative decoding speedup mainly depends on two factors: how many drafted tokens are accepted per cycle and how much extra cost the draft model adds. DFlash improves both: diffusion drafting lowers draft cost and KV injection raises acceptance.
Concretely, let's compare end-to-end acceptance lengths and speeds for a 5-layer EAGLE-3 drafter and several 5-layer DFlash variant drafters trained for Qwen 3-4B on the same dataset. Baseline DFlash achieves a similar acceptance length to a 5-layer EAGLE-3 drafter, but thanks to its ultra-fast parallel drafting, it delivers much higher end-to-end speedup. Results are reported as acc_len / speedup.
| Task | EAGLE-3 (5 layers) | DFlash |
|---|---|---|
| GSM8K | 4.2 / 2.1x | 4.2 / 3.3x |
| HumanEval | 4.3 / 2.2x | 4.0 / 3.2x |
| MT-Bench | 3.1 / 1.4x | 3.0 / 2.2x |
DFlash drafts faster
Autoregressive drafters like EAGLE-3 generate draft tokens one by one. As the draft length grows, the drafting cost grows roughly linearly. To keep latency low, these methods usually rely on very shallow draft models, which limits draft quality.
DFlash avoids this bottleneck with a block diffusion drafter. It generates a whole block of tokens in parallel with a single forward pass, making drafting much more hardware-friendly. A 5-layer DFlash drafter generating 4, 8, or even 16 tokens has much lower drafting latency than a single-layer EAGLE-3 drafter producing 4 tokens.
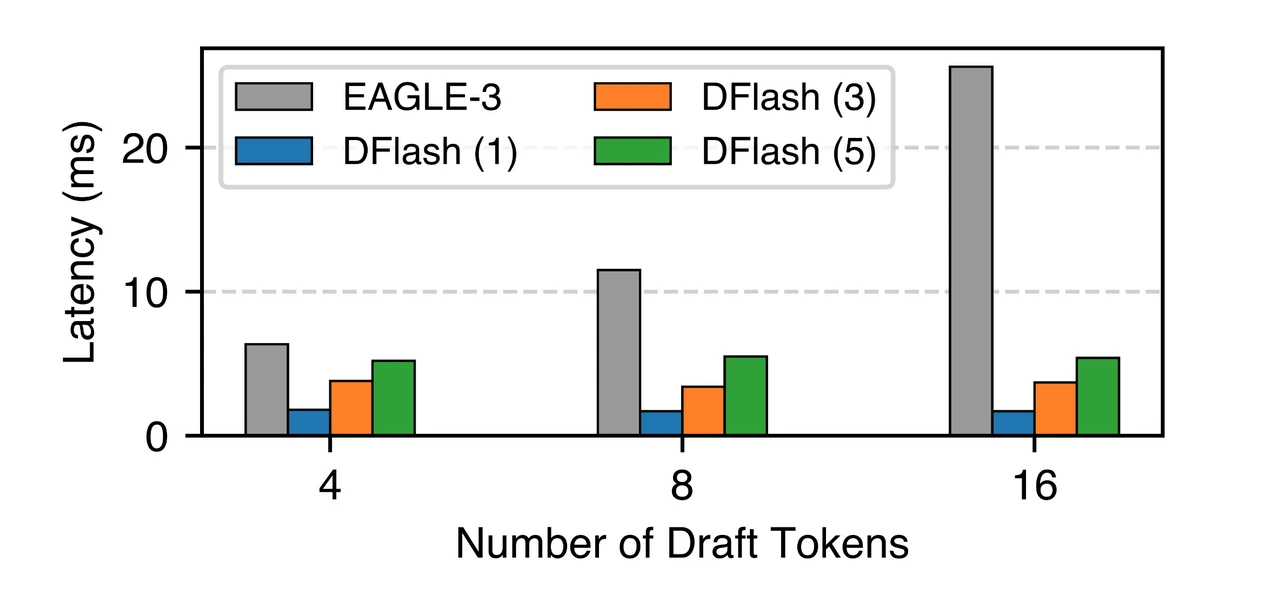
We can observe the independent impact of this technique by ablating other DFlash architectural features. DFlash still provides a higher end-to-end speedup than EAGLE-3, even at lower acceptance lengths, thanks to its faster drafting.
| Task | EAGLE-3 (5 layers) | DFlash (diffusion only) |
|---|---|---|
| GSM8K | 4.2 / 2.1x | 3.5 / 2.9x |
| HumanEval | 4.3 / 2.2x | 3.5 / 2.9x |
| MT-Bench | 3.1 / 1.4x | 2.6 / 2.0x |
KV injection increases acceptance lengths
Fast drafting only helps if the drafted tokens are accepted. EAGLE-3 uses target model features only at the input of the draft model, and this signal fades in deeper draft models.
DFlash instead injects target features into the KV cache of every draft layer. This keeps the drafter strongly conditioned on the target model’s context throughout generation, allowing deeper drafters to produce higher-quality drafts.
We can also observe the independent impact of KV injection by ablating the diffusion drafting. DFlash in autoregressive mode still produces higher speedups in our end-to-end benchmark due to higher acceptance lengths.
| Task | EAGLE-3 (5 layers) | DFlash (injection only) |
|---|---|---|
| GSM8K | 4.2 / 2.1x | 4.8 / 2.4x |
| HumanEval | 4.3 / 2.2x | 4.6 / 2.3x |
| MT-Bench | 3.1 / 1.4x | 3.4 / 1.5x |
Implementing DFlash in SGLang
The benchmark numbers in the above section are from the initial implementation of DFlash as part of R&D by Z Lab. Based on these impressive results, the teams at Modal and SGLang collaborated with Z Lab to optimize end-to-end performance in the SGLang inference engine.
Bringing a performance optimization technique like DFlash from research to prod requires two basic components: implementing the technique inside a high-performance engine and then optimizing the performance of the end-to-end system, from host scheduler to GPU execution.
The DFlash integration into SGLang can be split into two parts along these lines. First, DFlash was added to the original (now deprecated) V1 speculative decoding engine. Besides implementing a new draft model architecture, this also required integration of KV caches across draft and target to support injection. Second, DFlash was added to the new V2 speculative decoding engine, which offers improved performance through reduced synchronization with the host.
In the initial implementation of DFlash, we added support for this new model architecture to the existing speculative decoding engine. This included the addition of a DFlashWorker to control the draft model execution and the actual DFlashDraftModel that it drives.
As a reminder, SGLang uses a scheduler process (mostly on the host) to drive execution of model worker processes (mostly on the accelerators). One counterintuitive aspect of the way speculative decoding works in SGLang is that the draft model worker is the one that talks to the scheduler (via methods like .forward_batch_generation). It wraps a target model’s worker for the verification passes and calls it when the drafts are ready. Keep this in mind if you look at the code or a trace!
That’s not new in DFlash. The main novelty is the KV injection, which ties state between the draft and target models. For methods like EAGLE, the draft KV cache is fully private to the draft model, calculated based on KV projection of the draft’s own latents. In DFlash, the latents of the target model are instead passed through a KV projection by the draft model.
We don’t want to store those latents and cut into precious KV cache space and we want all requests that have the same prefix to share the radix cache. So we run the draft KV projection ahead of the rest of the draft forward pass – immediate materialization. That needs to be fast, so we added a layer-batched linear projection and a fused Triton kernel for the norm+RoPE post-processing.
Eliminating host overhead for DFlash with Spec V2 and overlap scheduling
That worked and was fast, but we knew it could be faster. We were concurrently working on the V2 speculative decoding engine, so the next step was to combine DFlash with the V2 engine, which is what’s now available in SGLang.
The key goal of the V2 engine as a whole is to reduce points of host-device synchronization, which kill inference performance, no matter how fast the GPU is or how good the kernels are. The solution is called the overlap scheduler.
In particular, there are two key opportunities for overlap:
- host-side
pop_and_processcleanup after the GPU finishes batch N-1 (e.g. stop token detection, request metadata updates) can overlap with GPU work on batch N; - host KV allocation (in
prepare_for_decode) for batch N can overlap with GPU work on batch N-1.
Under V2 with these optimizations, performance improved by over 33%, from ~11.4 ktok/s to ~15.3 ktok/s, when running Qwen 3-8B on a single B200 at concurrency 32 (details here).
High-performance DFlash draft models are available for a variety of models
Today, we're releasing a new DFlash draft model for Qwen 3.5 397B-A17B. It achieves higher throughput than the model's native MTP speculation in all of the settings we tested, from GSM8K to HumanEval to MT-Bench and for request concurrencies from 1 to 32.
 For benchmark details and to reproduce the numbers yourself, see the Hugging Face repo.
For benchmark details and to reproduce the numbers yourself, see the Hugging Face repo.
You can find more high-quality drafters in Z Lab's DFlash collection on Hugging Face. And keep your eyes peeled for more models soon!
Try DFlash in SGLang now
You don’t have to just read this blog and feel FOMO. You can read the code. You can deploy a DFlash-accelerated SGLang server using the command shown at the start of this post — or spin one up on Modal.
You can also train a DFlash speculator model for your own data or target model. The same block diffusion plus KV injection approach can be applied to most target LLMs. Reach out to Z Lab or Modal if you're interested!
More broadly: you can run inference at optimal intelligence, speed, and cost thanks to the work of the open-weights model builders, systems researchers, and the open source community. Whether it’s research work on techniques like DFlash by the Z Lab or features and performance enhancements from open source contributors like Modal, the world’s best work on LLM inference is landing in the SGLang open source engine for you to build on and with.
Acknowledgements
Thanks to everyone who contributed to bringing Spec V2 and DFlash to SGLang.
Z Lab: Jian Chen, Yesheng Liang, and Zhijian Liu.
Modal: David Wang and Charles Frye.
SGLang: Qiaolin Yu, Liangsheng Yin, and Khoa Pham.