Chatbot Arena: Benchmarking LLMs in the Wild with Elo Ratings
by: Lianmin Zheng*, Ying Sheng*, Wei-Lin Chiang, Hao Zhang, Joseph E. Gonzalez, Ion Stoica, May 03, 2023
We present Chatbot Arena, a benchmark platform for large language models (LLMs) that features anonymous, randomized battles in a crowdsourced manner. In this blog post, we are releasing our initial results and a leaderboard based on the Elo rating system, which is a widely-used rating system in chess and other competitive games. We invite the entire community to join this effort by contributing new models and evaluating them by asking questions and voting for your favorite answer.
Table 1. LLM Leaderboard (Timeframe: April 24 - May 1, 2023). The latest and detailed version here.
| Rank | Model | Elo Rating | Description |
|---|---|---|---|
| 1 | 🥇 vicuna-13b | 1169 | a chat assistant fine-tuned from LLaMA on user-shared conversations by LMSYS |
| 2 | 🥈 koala-13b | 1082 | a dialogue model for academic research by BAIR |
| 3 | 🥉 oasst-pythia-12b | 1065 | an Open Assistant for everyone by LAION |
| 4 | alpaca-13b | 1008 | a model fine-tuned from LLaMA on instruction-following demonstrations by Stanford |
| 5 | chatglm-6b | 985 | an open bilingual dialogue language model by Tsinghua University |
| 6 | fastchat-t5-3b | 951 | a chat assistant fine-tuned from FLAN-T5 by LMSYS |
| 7 | dolly-v2-12b | 944 | an instruction-tuned open large language model by Databricks |
| 8 | llama-13b | 932 | open and efficient foundation language models by Meta |
| 9 | stablelm-tuned-alpha-7b | 858 | Stability AI language models |
Table 1 displays the Elo ratings of nine popular models, which are based on the 4.7K voting data and calculations shared in this notebook. You can also try the voting demo.
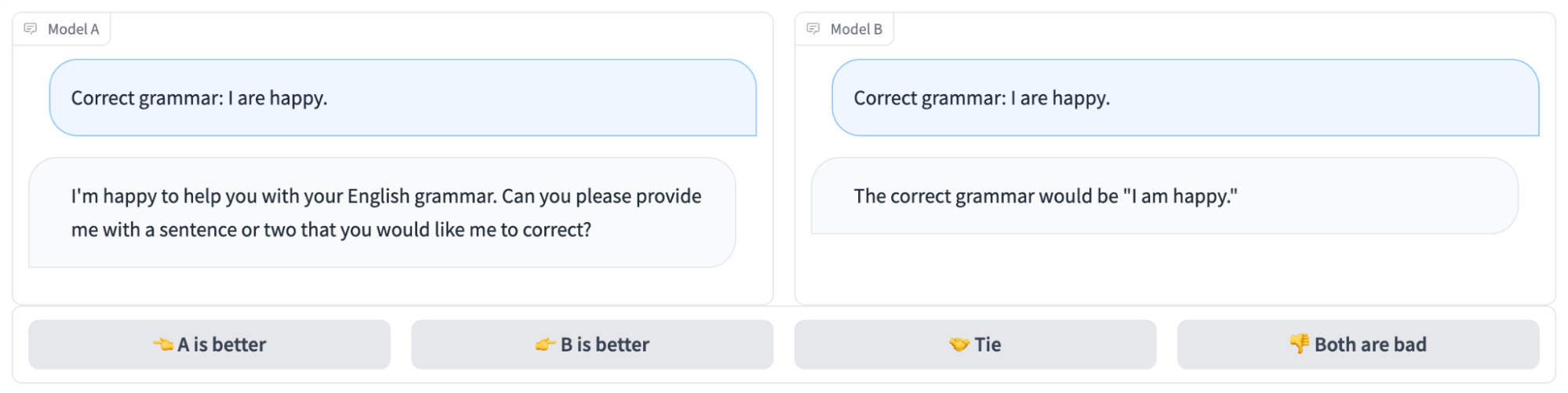
Figure 1. The side-by-side chatting and voting interface.
Please note that we periodically release blog posts to update the leaderboard. Feel free to check the following updates:
- May 10 Updates
- May 25 Updates
- June 22 Updates
- Dataset Release (July 20)
- Dec. 7 Updates
- Policy Updates (March 1, 2024)
Introduction
Following the great success of ChatGPT, there has been a proliferation of open-source large language models that are finetuned to follow instructions. These models are capable of providing valuable assistance in response to users’ questions/prompts. Notable examples include Alpaca and Vicuna, based on LLaMA, and OpenAssistant and Dolly, based on Pythia.
Despite the constant release of new models every week, the community faces a challenge in benchmarking these models effectively. Benchmarking LLM assistants is extremely challenging because the problems can be open-ended, and it is very difficult to write a program to automatically evaluate the response quality. In this case, we typically have to resort to human evaluation based on pairwise comparison.
There are some desired properties for a good benchmark system based on pairwise comparison.
- Scalability. The system should scale to a large number of models when it is not feasible to collect sufficient data for all possible model pairs.
- Incrementality. The system should be able to evaluate a new model using a relatively small number of trials.
- Unique order. The system should provide a unique order for all models. Given any two models, we should be able to tell which ranks higher or whether they are tied.
Existing LLM benchmark systems rarely satisfy all of these properties. Classical LLM benchmark frameworks, such as HELM and lm-evaluation-harness, provide multi-metric measurements for tasks commonly used in academic research. However, they are not based on pairwise comparison and are not effective at evaluating open-ended questions. OpenAI also launched the evals project to collect better questions, but this project does not provide ranking mechanisms for all participating models. When we launched our Vicuna model, we utilized a GPT-4-based evaluation pipeline, but it does not provide a solution for scalable and incremental ratings.
In this blog post, we introduce Chatbot Arena, an LLM benchmark platform featuring anonymous randomized battles in a crowdsourced manner. Chatbot Arena adopts the Elo rating system, which is a widely-used rating system in chess and other competitive games. The Elo rating system is promising to provide the desired property mentioned above. We noticed that the Anthropic LLM paper also adopted the Elo rating system.
To collect data, we launched the arena with several popular open-source LLMs one week ago. In the arena, a user can chat with two anonymous models side-by-side and vote for which one is better. This crowdsourcing way of data collection represents some use cases of LLMs in the wild. A comparison between several evaluation methods is shown in Table 2.
Table 2: Comparison between different evaluation methods.
| HELM / lm-evaluation-harness | OpenAI/eval | Alpaca Evaluation | Vicuna Evaluation | Chatbot Arena | |
|---|---|---|---|---|---|
| Question Source | Academic datasets | Mixed | Self-instruct evaluation set | GPT-4 generated | User prompts |
| Evaluator | Program | Program/Model | Human | GPT-4 | User |
| Metrics | Basic metrics | Basic metrics | Win rate | Win rate | Elo ratings |
Data Collection
We hosted the arena at https://lmarena.ai with our multi-model serving system, FastChat. When a user enters the arena, they can chat with two anonymous models side-by-side, as shown in Figure 1. After getting responses from the two models, users can continue chatting or vote for the model they think is better. Once a vote is submitted, the model names will be revealed. Users can continue chatting or restart a new battle with two new randomly chosen anonymous models. The platform logs all user interactions. In our analysis, we only use the votes when the model names are hidden.
The arena was launched about one week ago and we have collected 4.7k valid anonymous votes since then. We share some exploratory analysis in this notebook and present a short summary here.
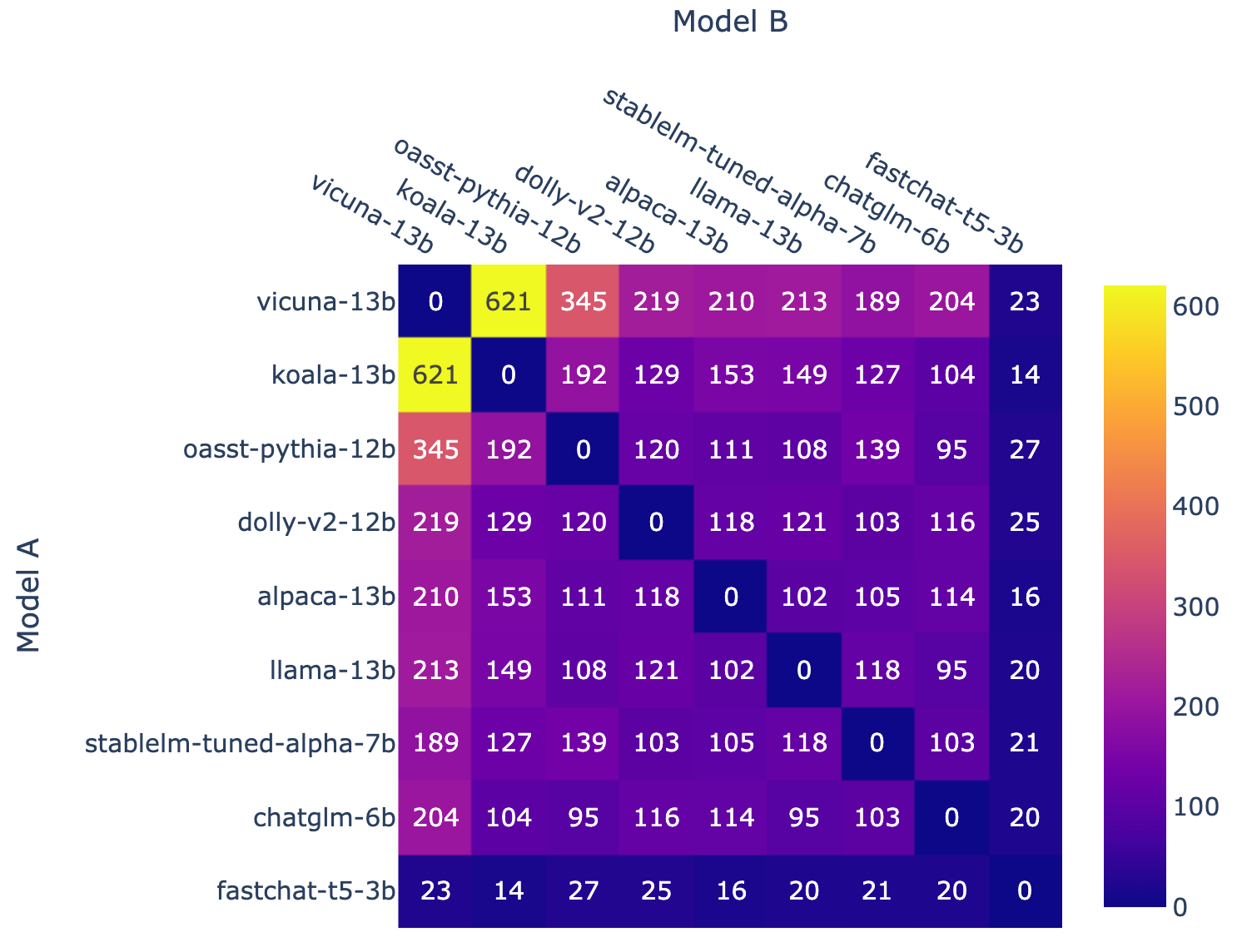
Figure 2: Battle count of each combination of models
Figure 2 shows the battles count of each combination of models. When we initially launched the tournament, we had prior information on the likely ranking based on our benchmarks and chose to pair models according to this ranking. We gave preference to what we believed would be strong pairings based on this ranking. However, we later switched to uniform sampling to get better overall coverage of the rankings. Towards the end of the tournament, we also introduced a new model fastchat-t5-3b. All of these result in non-uniform model frequency.
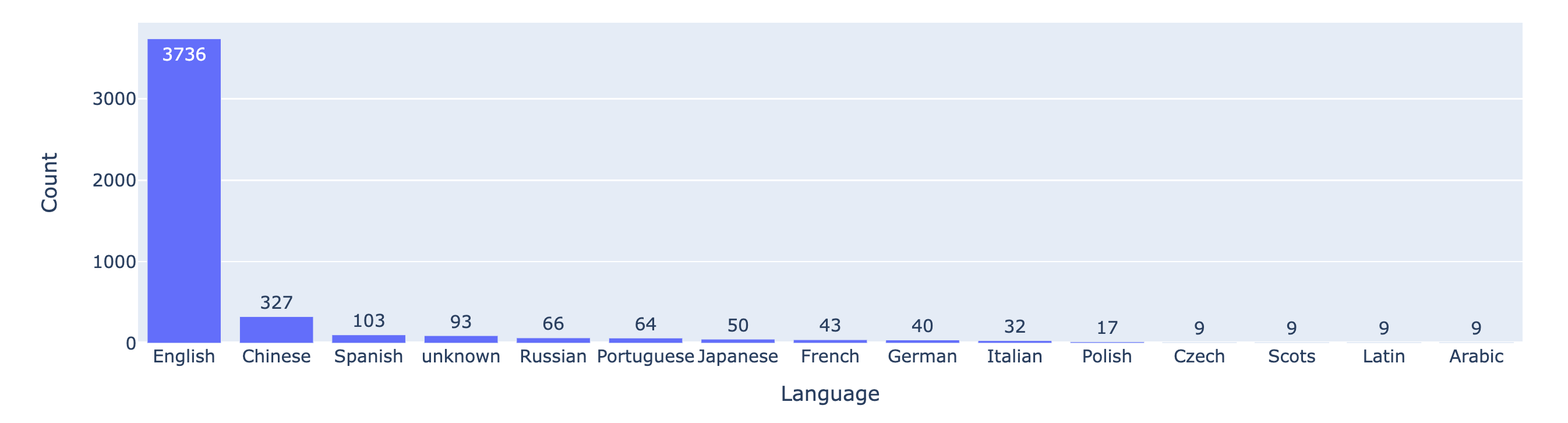
Figure 3: Battle counts for the top-15 languages.
Figure 3 plots the language distribution and shows most user prompts are in English.
Elo Rating System
The Elo rating system is a method for calculating the relative skill levels of players, which has been widely adopted in competitive games and sports. The difference in the ratings between two players serves as a predictor of the outcome of a match. The Elo rating system works well for our case because we have multiple models and we run pairwise battles between them.
If player A has a rating of Ra and player B a rating of Rb, the exact formula (using the logistic curve with base 10) for the probability of player A winning is

The ratings of players can be linearly updated after each battle. Suppose player A (with Rating Ra) was expected to score Ea points but actucally scored Sa points. The formula for updating that player's rating is

Using the collected data, we compute the Elo ratings of the models in this notebook and put the main results in Table 1. You are welcome to try the notebook and play with the voting data by yourself. The data only contains voting results without conversation histories because releasing the conversation history will raise concerns such as privacy and toxicity.
Pairwise Win Rates
As a basis for calibration, we also present here the pairwise win rates for each model in the tournament (Figure 4) as well as the predicted pairwise win rate estimated using Elo ratings (Figure 5). By comparing the figures, we find the elo ratings can predict win rates relatively well.
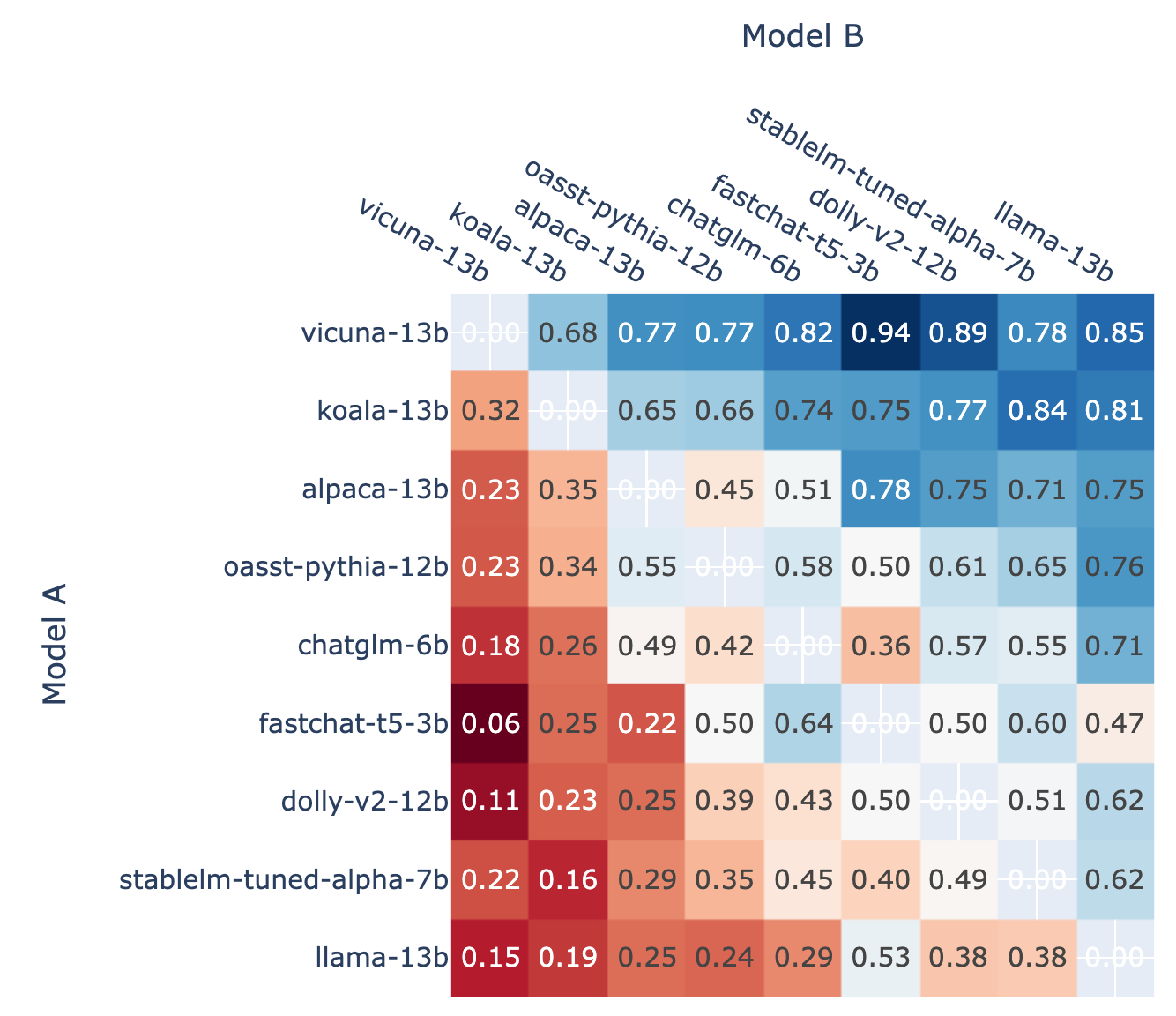
Figure 4: Fraction of Model A wins for all non-tied A vs. B battles.
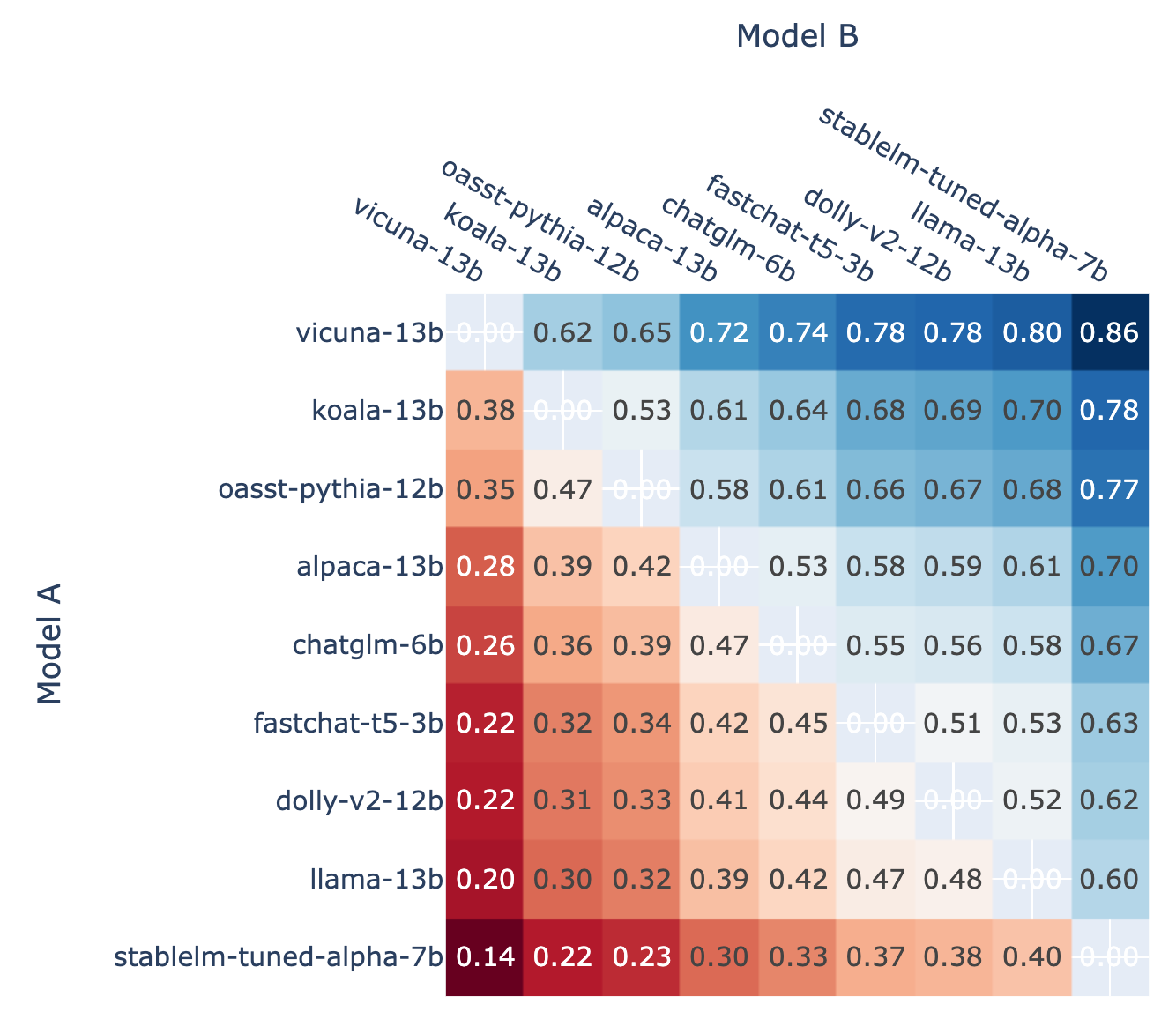
Figure 5: Predicted win rate using Elo ratings for Model A in an A vs. B battle
Future Plans
We plan to work on the following items:
- Add more closed-source models (ChatGPT-3.5, ChatGPT-4, and Claude-v1 are avaiable now in the anonymous Arena)
- Add more open-source models
- Release periodically updated leaderboards (e.g., monthly)
- Implement better sampling algorithms, tournament mechanisms, and serving systems to support a much larger number of models
- Provide fine-grained rankings on different task types.
We appreciate any feedback from you to make the arena better.
Join Us
We invite the entire community to join this benchmarking effort by contributing your models and votes for the anonymous models you think provide better answers. You can visit https://lmarena.ai to vote for better models. If you want to see a specific model in the arena, you can follow this guide to help us add it.
Acknowledgment
We thank other members of the Vicuna team for valuable feedback and MBZUAI for donating compute resources. Additionally, we extend our thanks to Tianjun Zhang and Eric Wallace for their insightful discussions.
Links
- Demo: https://lmarena.ai
- Leaderboard: https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
- GitHub: https://github.com/lm-sys/FastChat
- Colab notebook: https://colab.research.google.com/drive/1RAWb22-PFNI-X1gPVzc927SGUdfr6nsR?usp=sharing
Citation
Please cite the following papers if you find our work useful.
@misc{chiang2024chatbot,
title={Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference},
author={Wei-Lin Chiang and Lianmin Zheng and Ying Sheng and Anastasios Nikolas Angelopoulos and Tianle Li and Dacheng Li and Hao Zhang and Banghua Zhu and Michael Jordan and Joseph E. Gonzalez and Ion Stoica},
year={2024},
eprint={2403.04132},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
@inproceedings{zheng2023judging,
title={Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena},
author={Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2023},
url={https://openreview.net/forum?id=uccHPGDlao}
}
@inproceedings{zheng2024lmsyschatm,
title={LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset},
author={Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Tianle Li and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zhuohan Li and Zi Lin and Eric Xing and Joseph E. Gonzalez and Ion Stoica and Hao Zhang},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=BOfDKxfwt0}
}